hiveserver2专题
![[bigdata-030] cdh 5.9的impyla操作hiveserver2](/front/images/it_default2.jpg)
[bigdata-030] cdh 5.9的impyla操作hiveserver2
参考文献:http://www.aichengxu.com/view/11094184 1. cdh 5.9 2. 开发机已经安装了impyla pip install thrift_sasl pip install sasl 3. 在cdh集群的一个节点启动hiveserver2 3.1 修改/etc/hive/conf.cloudera.hive/hive-sit
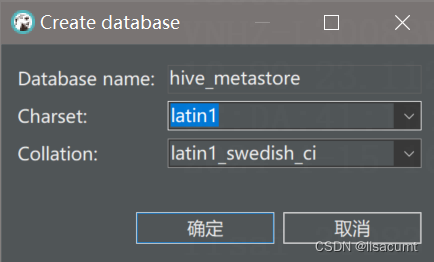
【hive】mysql数据库作为metastore,hive hiveserver2启动报错All is already granted by admin
报错内容: All is already granted by adminrole admin already exists 尝试一,失败: 在mysql数据库设置: SET GLOBAL binlog_format = 'ROW';COMMIT; 尝试二,解决: metastore数据库删除,重建,collation选latin1_general_ci也不行,下图是默认的就可
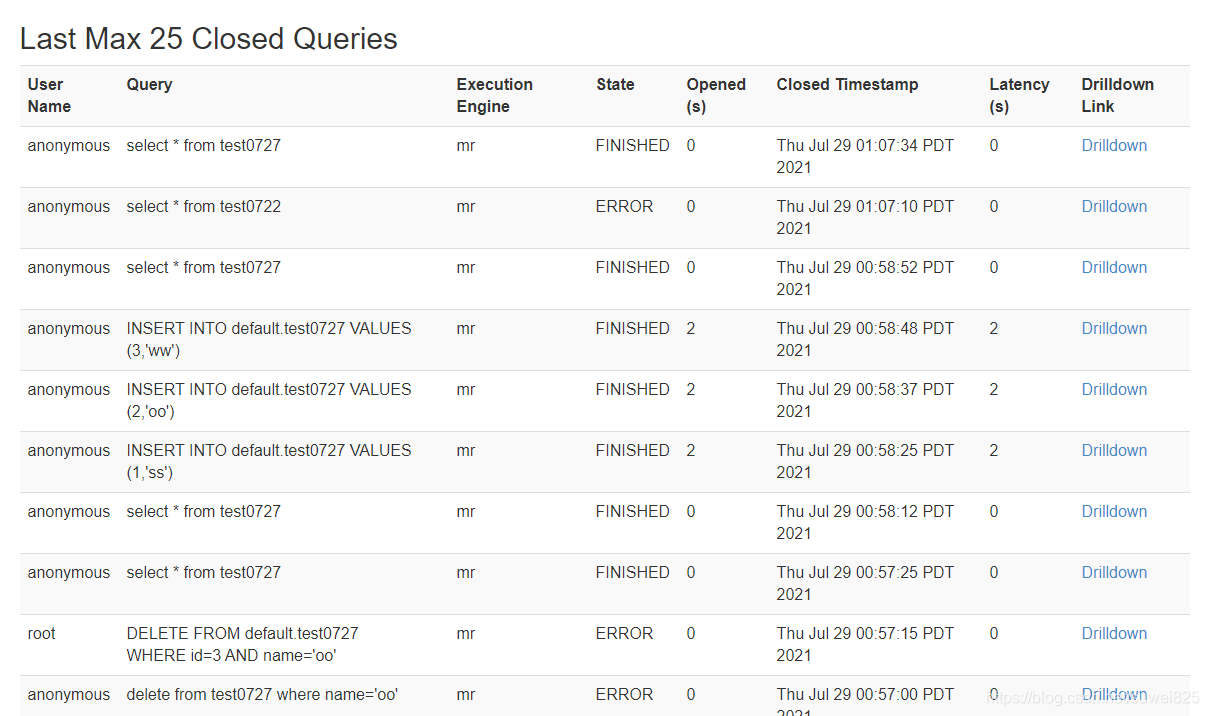
hiveserver2服务的启动与简单使用技巧
一、hiveserver2简介 Hive在生产上是不需要部署集群的,操作Hive只需要通过它提供的客户端即可,Hive提供了大致三类客户端: hive shell:通过hive shell来操作hive,但是至多只能存在一个hive shell,启动第二个会被阻塞,也就是说hive shell不支持并发操作。WebUI: 通过HUE/Zeppelin来对Hive表进行操作。基于JDBC等
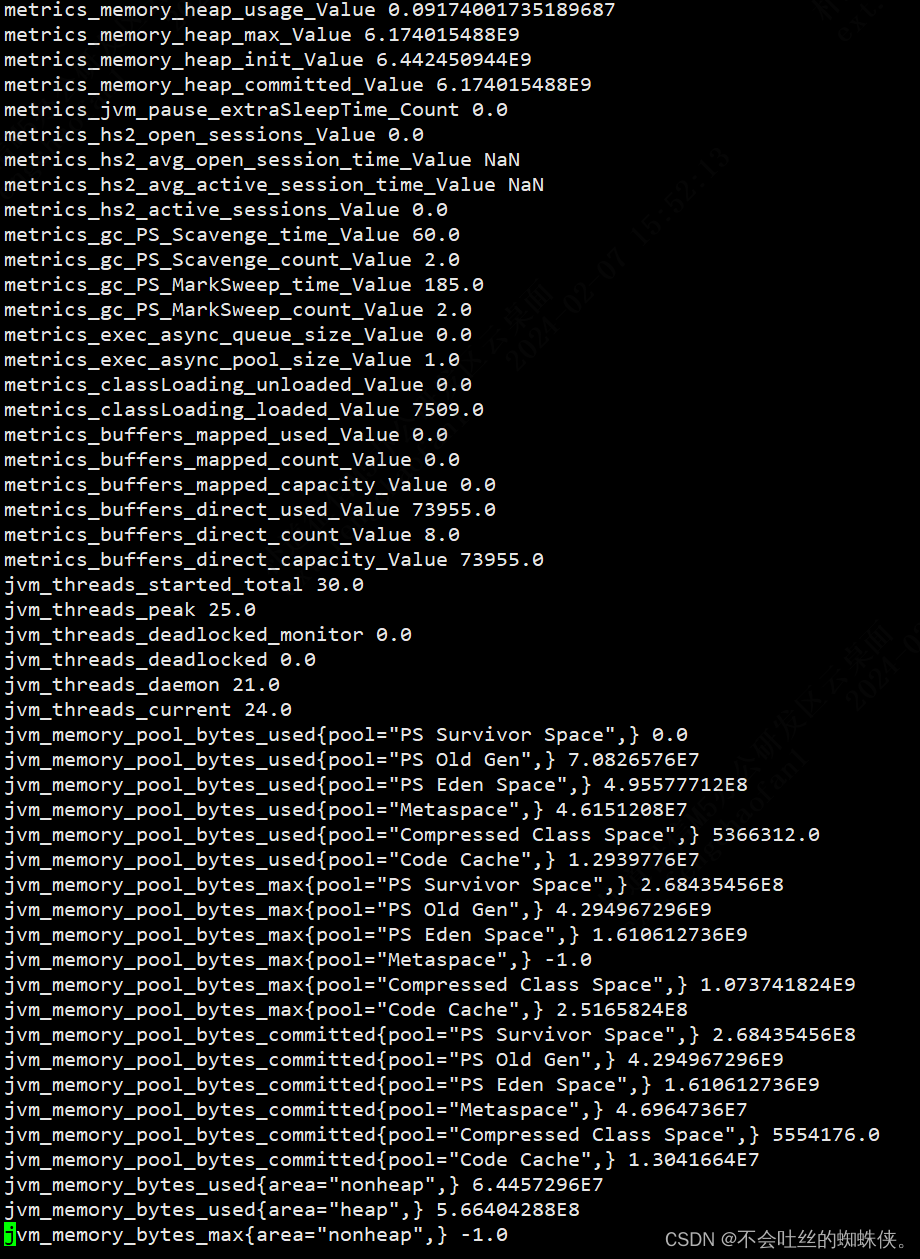
grafana+prometheus+hiveserver2(jmx_exporter+metrics)
一、hiveserver2开启metrics,并启动jmx_exporter 1、修改hive-site.xml文件开启metrics <property><name>hive.server2.metrics.enabled</name><value>true</value></property><property><name>hive.service.metrics.codahale

hiveServer2没有启动起来,启动的命令是: hive --service hiveserver2
Error: Could not open client transport with JDBC Uri: jdbc:hive2://192.168.159.131:10000:Error: Could not open client transport with JDBC Uri: jdbc:hive2://192.168.159.131:10000: java.net.ConnectExce
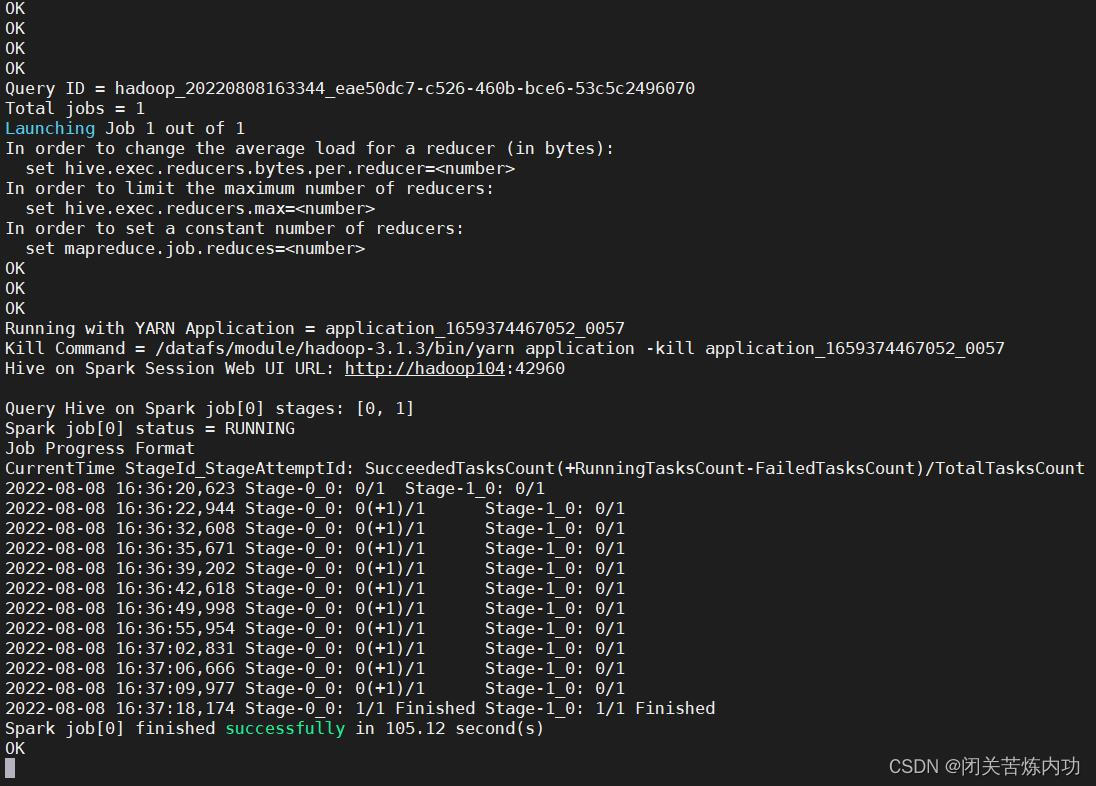
HiveServer2 报错 OutOfMemoryError 解决思路
今天下午使用 datagrip 远程连接 hive 突然中断,无法连接,拒绝连接 看了一下 hiveserver2 日志 2022-08-08 15:41:37,407 Log4j2-TF-2-AsyncLogger[AsyncContext@2c8d66b2]-1 ERROR Unable to invoke factory method in class org.apache.hadoop.

hiveserver2运行异常:GC overhead limit exceeded
记一次hiveserver2服务运行异常问题。 报错信息: java.lang.OutOfMemoryError: GC overhead limit exceeded 解决方法: 修改hive配置文件hive-env.sh。将原来注释的替换成如下配置 # Hive Client memory usage can be an issue if a large number of cl

记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查
背景 最近发现集群主节点总有进程宕机,定位了大半天才找到原因,分享一下 排查过程 查询hiveserver2和namenode日志,都是正常的,突然日志就不记录了,直到我重启之后又恢复工作了。 排查各种日志都是正常的,直到查看Grafana,发现内存满了 在这个节点下已无内存资源可用,在服务宕掉的节点内存使用突然下降,猜测是linux内核的杰作,故查询系统日志 grep "Out
记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查
背景 最近发现集群主节点总有进程宕机,定位了大半天才找到原因,分享一下 排查过程 查询hiveserver2和namenode日志,都是正常的,突然日志就不记录了,直到我重启之后又恢复工作了。 排查各种日志都是正常的,直到查看Grafana,发现内存满了 在这个节点下已无内存资源可用,在服务宕掉的节点内存使用突然下降,猜测是linux内核的杰作,故查询系统日志 grep "Out
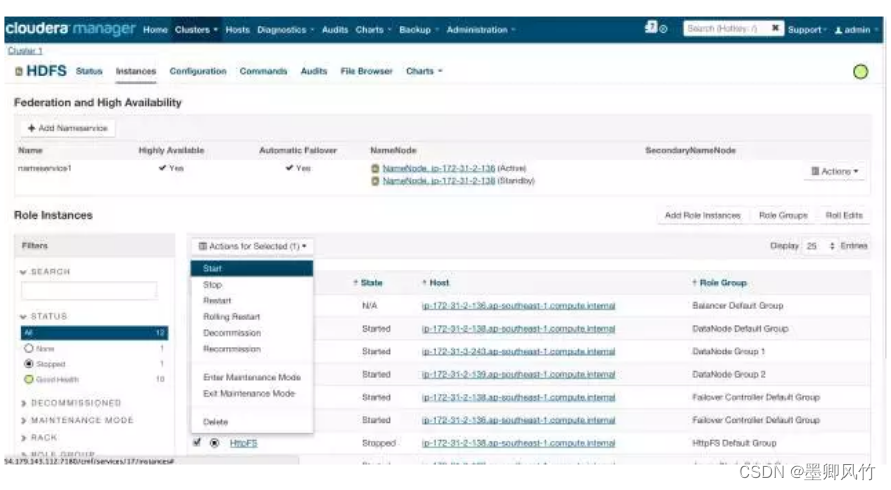
hue实现对hiveserver2 的负载均衡
如果你使用的是CDH集群那就很是方便的 在Cloudera Manager中,进入HDFS Service 进入Instances标签页面,点击Add Role Instances按钮,如下图所示 点击Continue按钮,如下图所示 返回Instances页面,选择HttpFS角色,并点击Start启动服务,如下图所示 HttpFS服务启动后,点击进入Hue Service

HiveServer2 Service Crashes(hiveServer2 服务崩溃)
Troubleshooting Hive | 5.9.x | Cloudera Documentation 原因:别人用的都好好的,我的集群为什么会崩溃? 1.hive分区表太多(这里没有说具体数量。) 2.并发连接太多,我记的以前默认是200个连接 3.复杂的hive查询访问表的的分区 4.hs2实例数太少 如果存在这些情况中的任何一种,Hive可能运行缓慢,或者可能崩溃,因为