本文主要是介绍hiveserver2服务的启动与简单使用技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、hiveserver2简介
Hive在生产上是不需要部署集群的,操作Hive只需要通过它提供的客户端即可,Hive提供了大致三类客户端:
hive shell:通过hive shell来操作hive,但是至多只能存在一个hive shell,启动第二个会被阻塞,也就是说hive shell不支持并发操作。
WebUI: 通过HUE/Zeppelin来对Hive表进行操作。
基于JDBC等协议:启动hiveserver2,通过jdbc协议可以访问hive,hiveserver2支持高并发。
简而言之,hiveserver2是Hive启动了一个server,客户端可以使用JDBC协议,通过IP+ Port的方式对其进行访问,达到并发访问的目的。
二、使用hiveserver2服务
本次演示使用的Hive版本是:apache-hive-3.1.2,开发工具是IDEA2021
1.启动hiveserver2服务
启动Hiveserver2有两种命令:
hive的bin目录下执行 hive --service hiveserver2
或者
hive的bin目录下执行 ./hiveserver2,
hiveserver2的服务端口默认是10000,WebUI端口默认是10002,这2个都可以在hive-site.xml中配置
我们新开一个终端使用命令netstat -anop|grep 10000 和 netstat -anop|grep 10002:

说明服务端口和web端口都在监听状态,启动正常
我们在浏览器访问 http://master104:10002/,可以看到如下图的界面
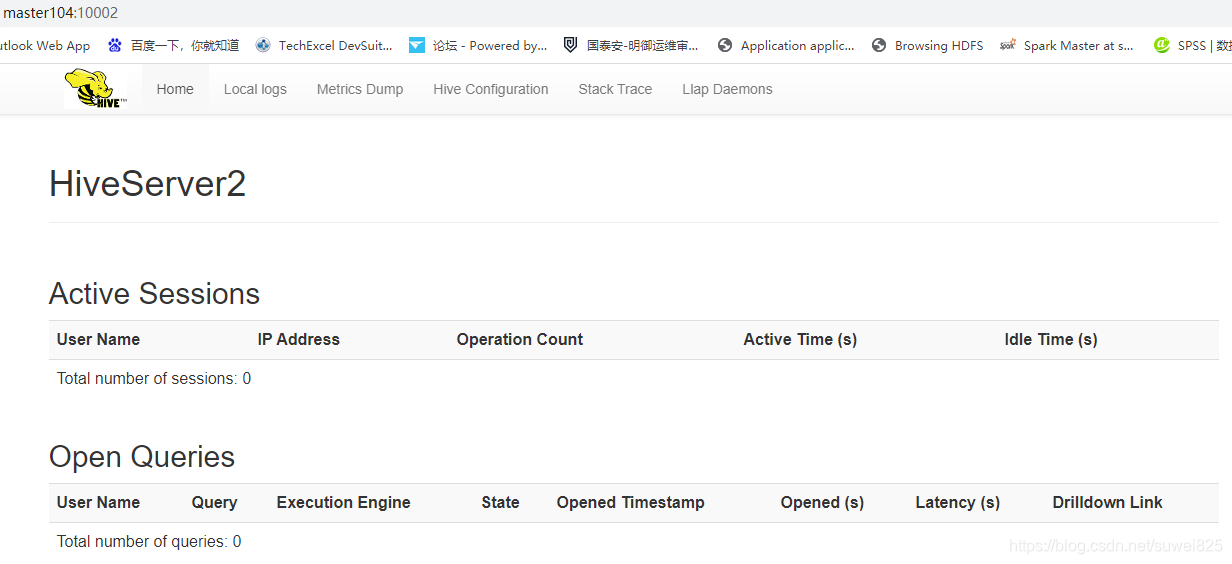
2.启动beeline连接server
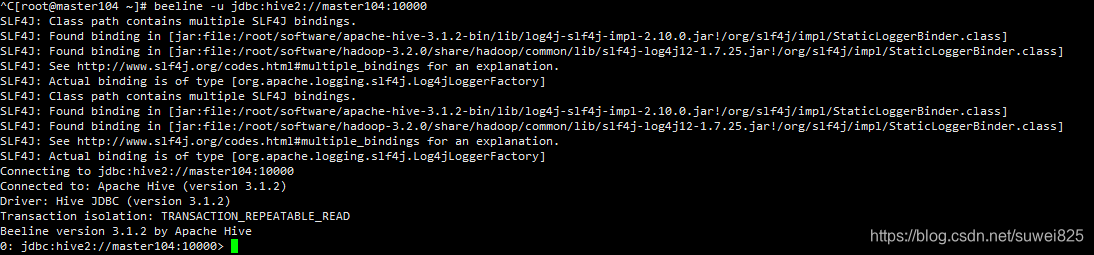
在装了相同版本Hive的其他主机(启动hiveserver2的主机也可以)上启动beeline,可以连接到Hive的server上。执行命令:beeline -u jdbc:hive2://master104:10000:
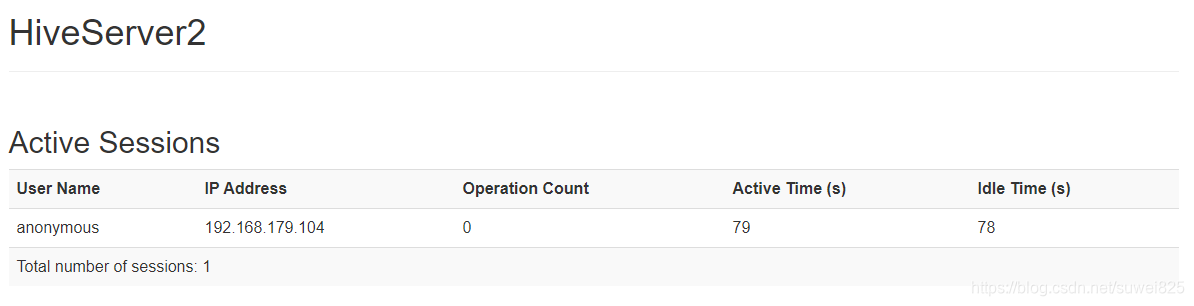
连接成功,我们刷新web管理端,可以看到一条连接信息
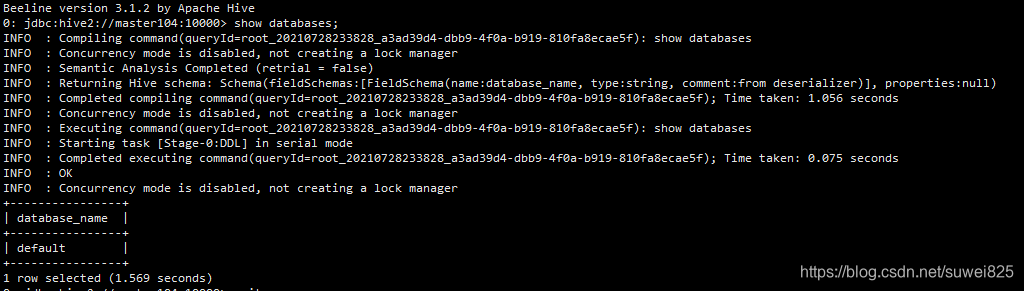
我们在beeline终端执行 show databases;输出了结果
同时刷新web端,可以看到执行了一个mr任务

我们可以使用beeline完成在hive shell中相同的操作。
3.使用JDBC协议连接server
我们打开idea,新建一个maven项目,在pom文件添加依赖
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>3.1.2</version></dependency>
</dependencies>我们在src下面新建一个测试类HiveTest,输入代码如下
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;public class HiveTest {//连接private Connection connection = null;private PreparedStatement preparedStatement = null;private ResultSet resultSet = null;/*** 建立连接*/@Beforepublic void before(){try {//Hive的JDBC驱动String classDriver = "org.apache.hive.jdbc.HiveDriver";//连接串,接数据库名mydb,数据库写你的数据库String url = "jdbc:hive2://master104:10000/default";//加载驱动Class.forName(classDriver);//获得连接connection = DriverManager.getConnection(url);}catch (Exception e){e.printStackTrace();}}/*** 查询表中的数据*/@Testpublic void testHiveSelect(){try {//表和数据需要提前准备好String sql = "select * from test0727";//执行SQL语句preparedStatement = connection.prepareStatement(sql);//得到结果集resultSet = preparedStatement.executeQuery();//遍历结果集while (resultSet.next()){System.out.println(resultSet.getInt(1) + " " + resultSet.getString(2));}}catch (Exception e){e.printStackTrace();}}/*** 结束后关闭连接*/@Afterpublic void after(){try {if (preparedStatement != null)preparedStatement.close();if (resultSet != null)resultSet.close();connection.close();}catch (Exception e){e.printStackTrace();}}
}这个方法会查询hive上的默认库default下面的表test0727,里面有3条记录

我们执行单元测试 testHiveSelect,
在控制台得到下面结果
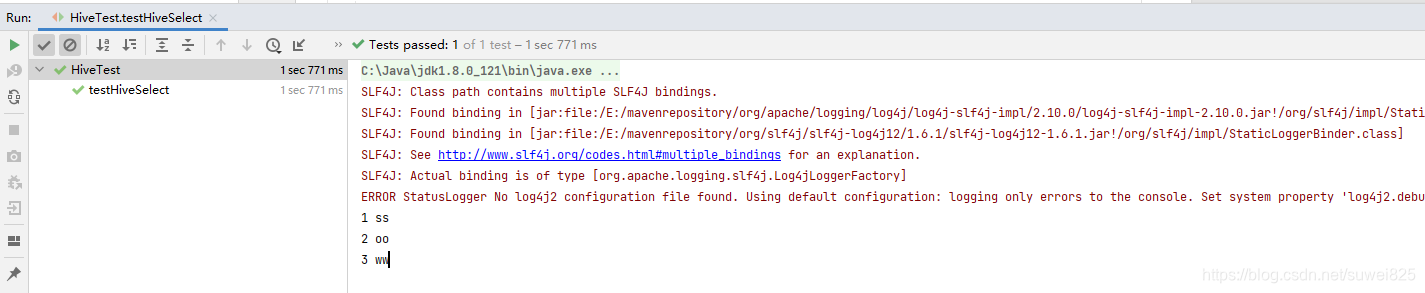
这里只是演示了查询Hive表的select查询操作,你会发现,代码和操作MysQL的代码一模一样,仅仅只是驱动不一样,这得益于Java的多态,MySQL和Hive都实现了JDBC的借口,所以在方法的调用层面上,二者是完全一样的!还有表的其他操作比如删除,排序等等也和操作MySQL的一致,这里就不多作介绍了,读者可以自行写测试代码来体验下。
通过查看WebUI,可以看到我们执行查询的操作记录:
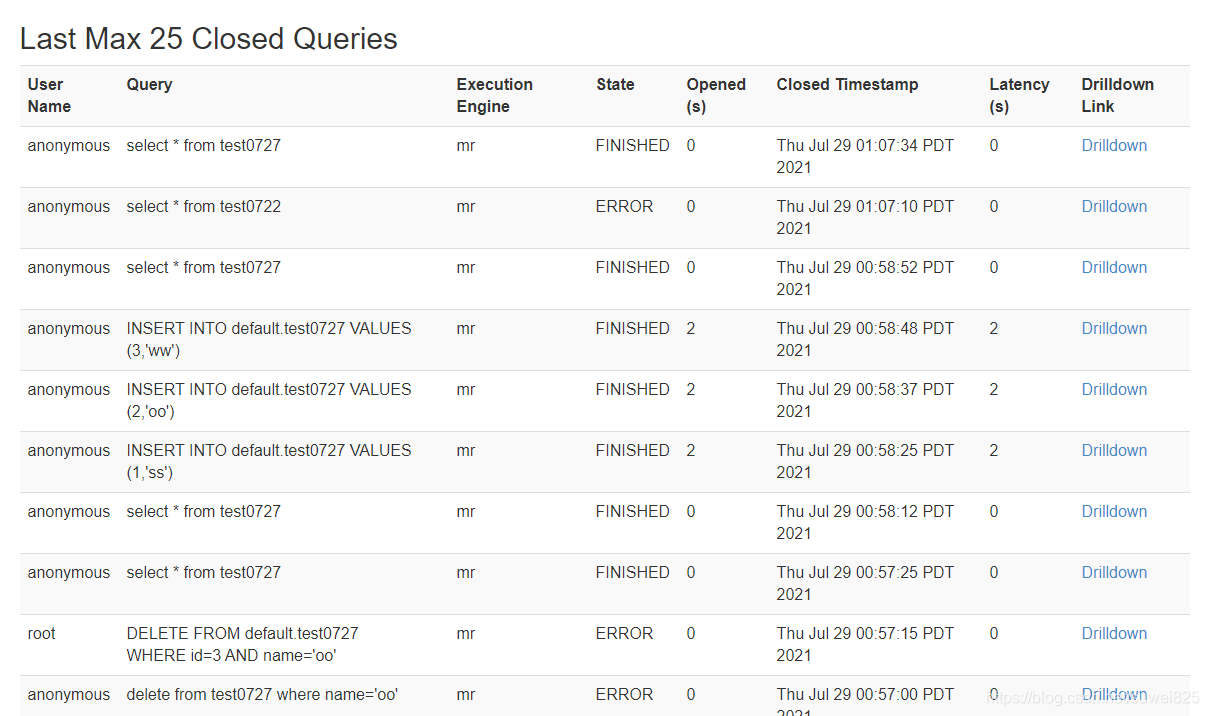
三、总结
Hive的hiveserver2服务本质上是实现了JDBC的接口,所以我们可以各种方式使用JDBC连接它,在终端可以使用beeline,连接Hive的server2,用法和hive shell一致,而编程则可以加载Hive的JDBC驱动,使用操作其他关系型数据库的方法操作Hive
感谢能看到这里的朋友😉
本次的分享就到这里,猫头鹰数据致力于为大家分享技术干货😎
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对技术感兴趣的伙伴记得点赞关注支持一波🙏
也可以搜索关注我的微信公众号【猫头鹰数据分析】,留言交流🙏
这篇关于hiveserver2服务的启动与简单使用技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




