本文主要是介绍记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
最近发现集群主节点总有进程宕机,定位了大半天才找到原因,分享一下
排查过程
查询hiveserver2和namenode日志,都是正常的,突然日志就不记录了,直到我重启之后又恢复工作了。

排查各种日志都是正常的,直到查看Grafana,发现内存满了
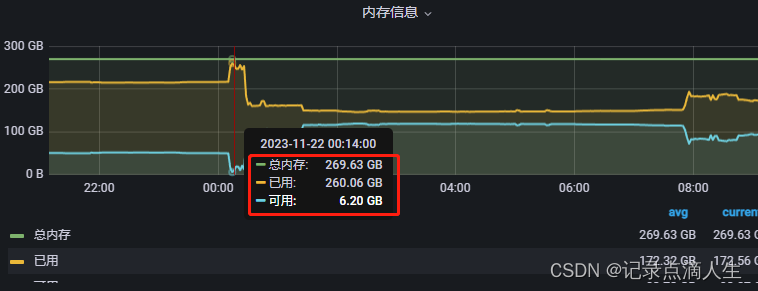
在这个节点下已无内存资源可用,在服务宕掉的节点内存使用突然下降,猜测是linux内核的杰作,故查询系统日志
grep "Out of memory" /var/log/messages

果然存在因OOM被杀掉的进程
进程被杀的原因
Linux 内核有个机制叫OOM killer,全称为 Out Of Memory killer,很形象的一个名字——内存溢出杀手,这个机制会监控那些占用内存过大,尤其是瞬间占用内存很快的进程,为防止机器内存耗尽而主动把该进程杀掉。
当内核检测到系统内存不足、挑选并杀掉某个进程的过程可以参考内核源代码 linux/mm/oom_kill.c(2023-4-4 23:24:07确认了此文件存在),当系统内存不足的时候,out_of_memory() 函数被触发,然后调用 select_bad_process() 函数选择一个进程杀掉,这个选择的过程是通过调用 oom_badness() 函数实现的,挑选的算法和想法都暴力但朴实:就是找到最占用内存的进程。
出现问题的原因
最近刚刚增加了sentry和hivemetastore内存大小,导致机器内存不够了。
解决方案
1.调整机器进程分布,确保机器不会出现内存超用
2.可以通过设置/proc/sys/vm/overcommit_memory为不同的值来调整OverCommit策略。
overcommit_memory可以取3个值:
- 0:默认值,由Linux内核通过一些启发式算法来决定是否超售和超售的大小,一般允许轻微的超售,拒绝一些明显不可能提供的请求,同时做一些规则限制,比如不同用户overcommit的大小也不一样。
- 1:允许,不做限制的超售,当然这个也不是无限大,还受到寻址空间的限制,32位系统最大可能只有4G,64位系统大概16T左右。
- 2:禁止,禁止超售,系统能够分配的内存不会超过swap+实际物理内存*overcommit_ratio,该值可以通过/proc/sys/vm/overcommit_ratio设置,默认50%。
vi /etc/sysctl.conf
-- 添加
vm.overcommit_memory=1
-- 重启生效
sysctl -p
总结
如果你发现运行了一段时间的进程突然不见了,那可能是内核嫉妒生恨把它给干掉了
查询内存溢出被杀掉的进程可以直接通过系统日志来查 grep “Out of memory” /var/log/messages
也可以通过专门的命令查找 dmesg -T | grep “Out of memory”
阿里P7数据技术专家,修改简历、模拟面试+vx:wodatoucai
这篇关于记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








