本文主要是介绍HiveServer2 Service Crashes(hiveServer2 服务崩溃),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Troubleshooting Hive | 5.9.x | Cloudera Documentation
原因:别人用的都好好的,我的集群为什么会崩溃?

1.hive分区表太多(这里没有说具体数量。)
2.并发连接太多,我记的以前默认是200个连接
3.复杂的hive查询访问表的的分区
4.hs2实例数太少
如果存在这些情况中的任何一种,Hive可能运行缓慢,或者可能崩溃,因为整个HS2堆内存已满。
现象:如果堆内存满了,hive集群一般会有什么表现呢?
Symptoms Displayed When HiveServer2 Heap Memory is Full

1.hs2服务直接挂掉,或者你开启新会话失败。
2.hs2服务看起来是好的,但是你连接被拒绝
3.查询提交重复失败
4.查询一直在提交,查询时间长
原因:HiveServer2 Service Crashes
这里太长了,我直接用我自己做例子告诉大家,怎么看hs2服务是否崩溃
1.打开cm主页,选择hive(我这里是hive on tez)->点击实例->点击hiveServer2
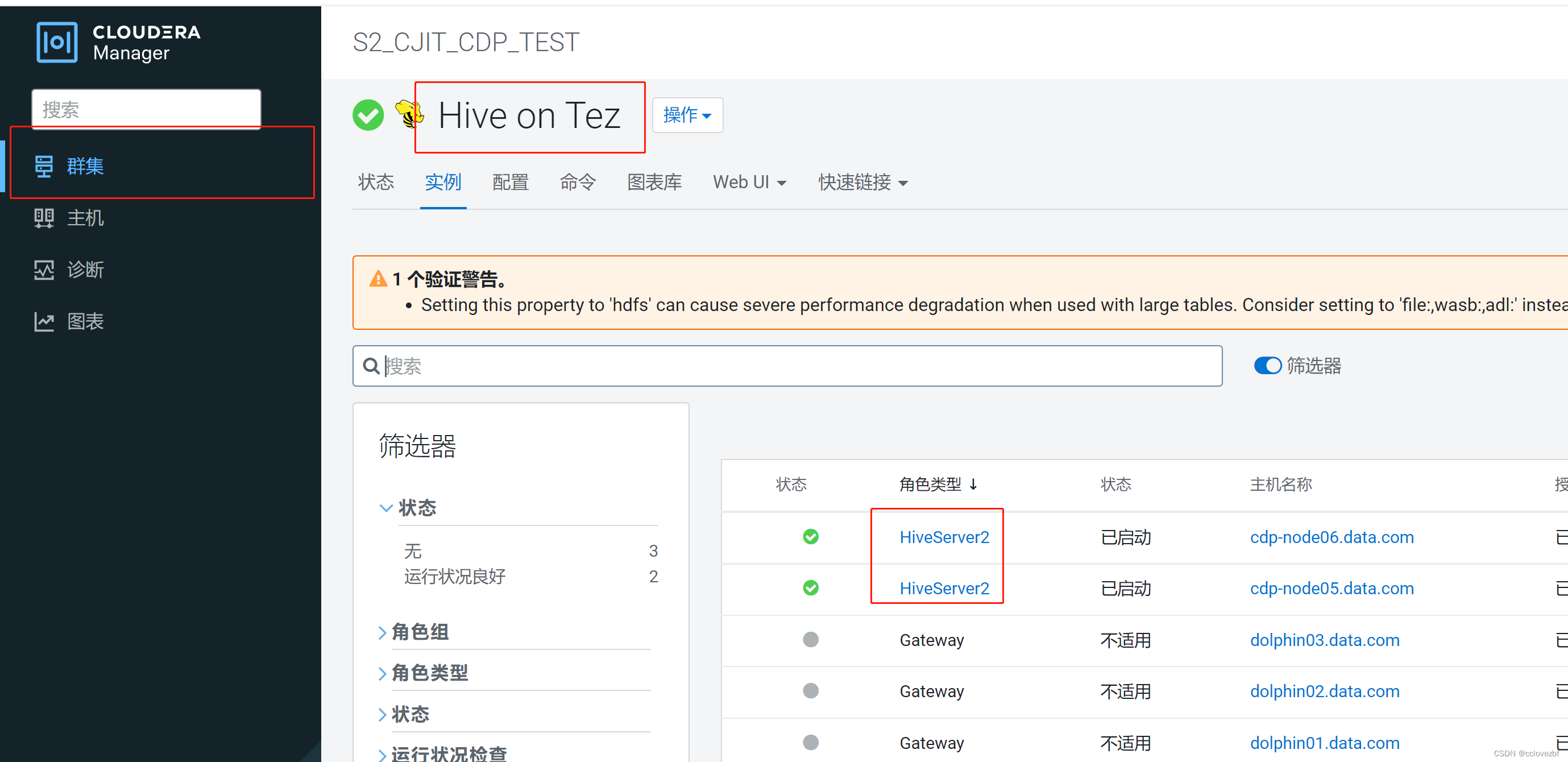
2.点击完hiveServer2后->点击日志文件->点击stdout

官网与我的页面有点差异,自行寻找
 3.打开stdout.log后查看是否有以下日志
3.打开stdout.log后查看是否有以下日志
-
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="/usr/lib64/cmf/service/common/killparent.sh" # Executing /bin/sh -c "/usr/lib64/cmf/service/common/killparent.sh"

问题2:HiveServer2 General Performance Problems or Connections Refused
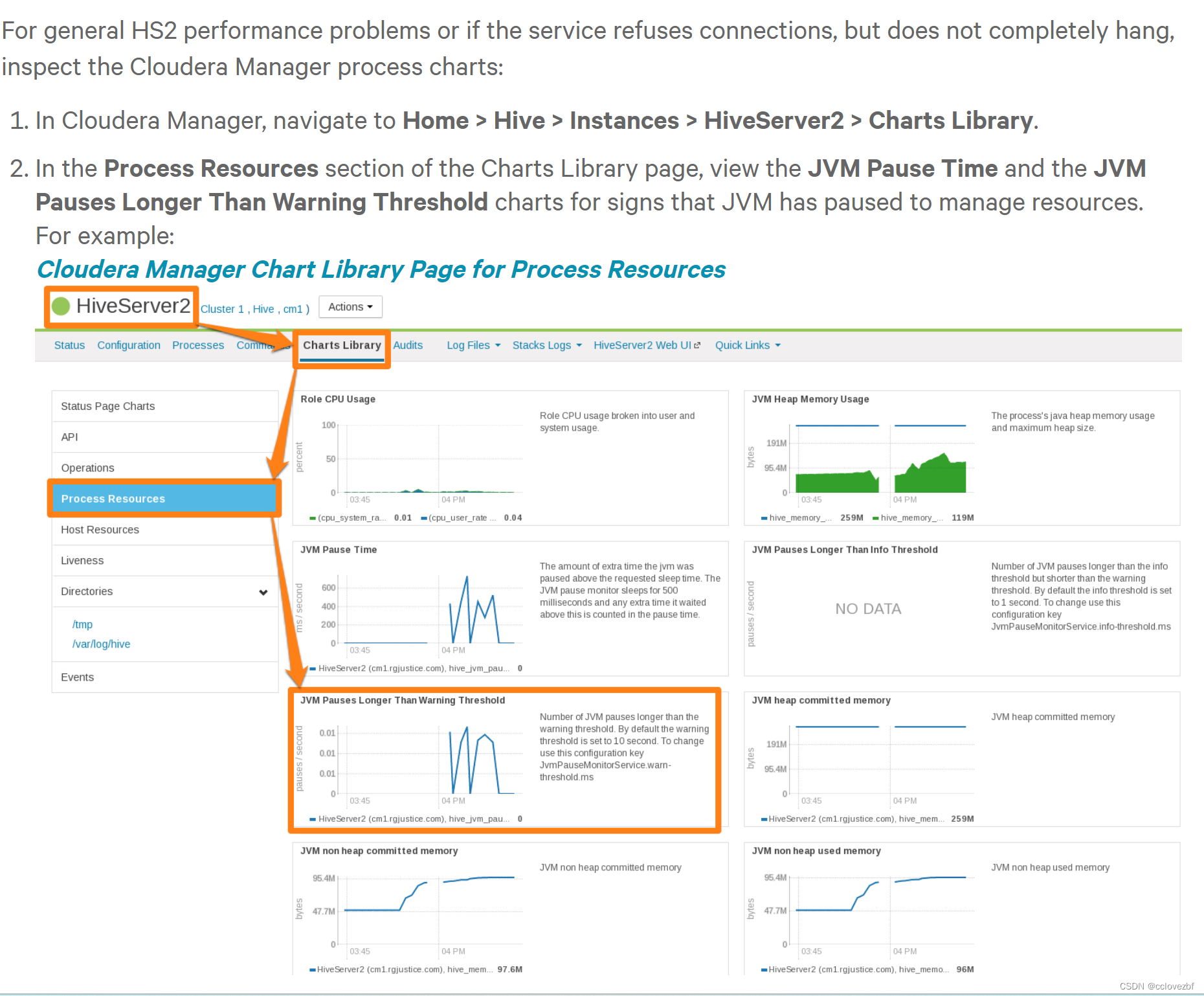
这里没啥说的,就是内存不够jvm需要暂停下去分配资源
最佳方案:HiveServer2 Performance Best Practices
官网说了一大堆废话,总结下来
1.修改heap的大小
2.减少查询的分区表数量
3.增加hs2的实例数
4.增加机器的内存。因为你增加hive的heap大小,可能这台机器的内存被其他服务占用
如何修改heap大小
1.cdh5.7以上默认是4GB
如何修改Home > Hive > Configuration > HiveServer2 > Resource Management. 然后保存+重启
hive配置

hive on tez的配置(这个才是真正的)

注意这里有意思的是我们发现hs2有两个配置一个4g一个256M,其中4g的是cdp-node05,256M的是cdp-node06
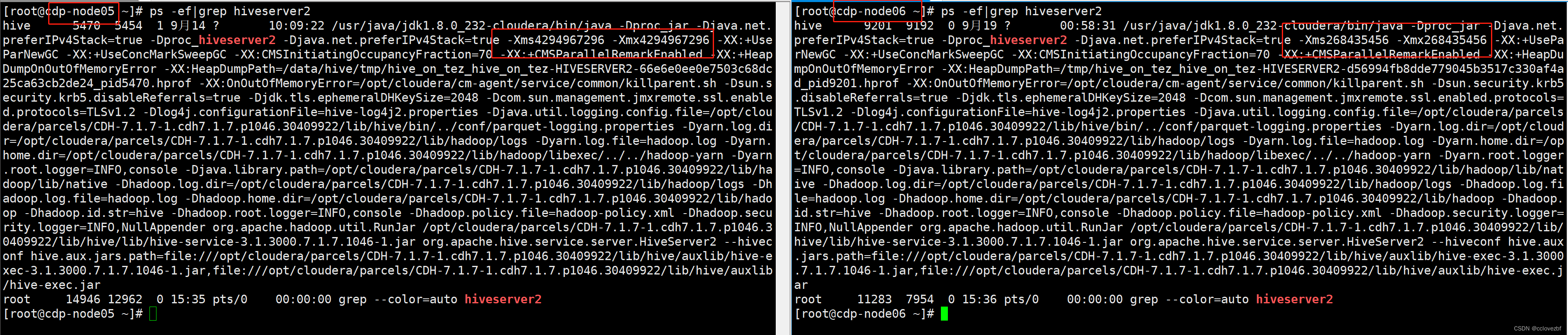
发现确实如此一个给了4g内存 一个给了256M。。这。。无言以对。
如果HS2已经配置为使用4GB或更大的堆大小运行,并且仍然存在性能问题,那么工作负载特性可能会导致内存压力。增加堆大小以减少HS2上的内存压力。Cloudera不建议每个实例超过16 GB,因为垃圾收集暂停时间很长。请参阅识别增加内存压力的工作负载特征,了解优化查询工作负载以降低HS2内存需求的提示。Cloudera建议将HS2拆分为多个实例,并在开始为HS2分配超过16GB的资源后进行负载平衡。
这里说的意思是4g默认,逐渐增大,如果16G不满足,就开起多个hiveserver2,负载均衡

High number of concurrent queries
大量并发查询会增加连接数。每个查询连接都会消耗查询计划、访问的表分区数和部分结果集的资源。
建议是每个hs2 instance 支持40个连接,如果你有400个的并发,建议增加hs2 instance的数据为10,同时检查你的调度任务(类似于 比如所有任务没必要都是每天0点开始,0:10分不行吗?)

Many abandoned Hue sessions
用户在Hue中打开许多浏览器选项卡会导致多个会话和连接,没有及时关闭
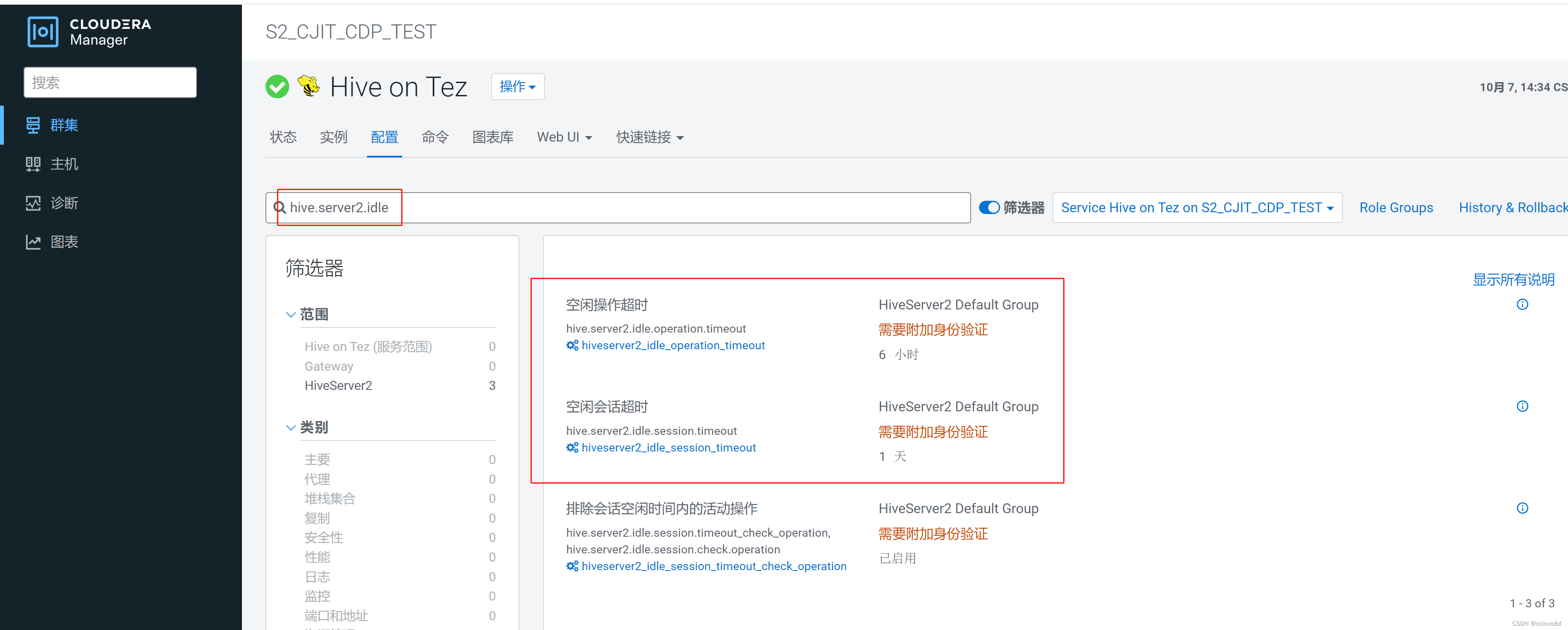
解决办法
hive.server2.idle.operation.timeout=7200000 默认是21600000=6h
hive.server2.idle.session.timeout=21600000 默认43200000=12h
修改Home > Hive > Configuration > HiveServer2 > Advanced
Queries that access a large number of table partitions:
比如 select * from partition_table limit 10 这句查询也会加载所有表。
通过explain dependency select * from partition_table limit 10 -- 可以看到加载了所有分区。

如何解决呢?
加上分区的过滤条件例如 select * from partition_table where partition_column='a'
设置 hive.metastore.limit.partition.request 好像新版本变成 hive.limit.query.max.table.partition
我的hive版本是3.1.3这两个参数都没用

最后一点说了,分区一般几千个就行了,你分几万个是以秒分区的?不分区效率太低,几千万上亿的表不分区就要思考自己的问题了。
Wide tables or columns:
内存需求与列的数量和单个列的大小成正比。通常,一个宽表包含1000多列。如果列的数量很大,宽表或列可能会导致内存压力。对于Parquet文件尤其如此,因为行组的所有数据都必须在内存中才能写入磁盘。尽可能避免使用宽表。
解决办法:不要select *
High query complexity
复杂的查询通常有大量的联接,通常每个查询超过10个联接。随着查询中联接数量的增加,HS2堆大小要求显著增加。
解决办法:1.对于每个join的表的分区都尽量过滤
2.将复杂的join拆分为小点的join,就是不要一下子加载10个表,比如分3次加载10个表
create temporay table abc as select xx from a join b join c
create temporay table def as select xx from d join e join f
select abc join def
Improperly written user-defined functions (UDFs)
编写不当的udf函数也会导致hs2压力过大
解决办法:了解udf的编写过程,使用前测试
最后附上视频里出现的hive配置建议 网址,视频里的不可以
Configuring HiveServer2 for CDH | 6.3.x | Cloudera Documentation
| Component | Java Heap | CPU | Disk | |
|---|---|---|---|---|
| HiveServer 2 | Single Connection | 4 GB | Minimum 4 dedicated cores | Minimum 1 disk This disk is required for the following:
|
| 2-10 connections | 4-6 GB | |||
| 11-20 connections | 6-12 GB | |||
| 21-40 connections | 12-16 GB | |||
| 41 to 80 connections | 16-24 GB | |||
| Cloudera recommends splitting HiveServer2 into multiple instances and load balancing them once you start allocating more than 16 GB to HiveServer2. The objective is to adjust the size to reduce the impact of Java garbage collection on active processing by the service. | ||||
| Set this value using the Java Heap Size of HiveServer2 in Bytes Hive configuration property. | ||||
| Hive Metastore | Single Connection | 4 GB | Minimum 4 dedicated cores | Minimum 1 disk This disk is required so that the Hive metastore can store the following artifacts:
|
| 2-10 connections | 4-10 GB | |||
| 11-20 connections | 10-12 GB | |||
| 21-40 connections | 12-16 GB | |||
| 41 to 80 connections | 16-24 GB | |||
| Set this value using the Java Heap Size of Hive Metastore Server in Bytes Hive configuration property. | ||||
| Beeline CLI | Minimum: 2 GB | N/A | N/A | |
这篇关于HiveServer2 Service Crashes(hiveServer2 服务崩溃)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







