h100专题

AI Toolkit + H100 GPU,一小时内微调最新热门文生图模型 FLUX
上个月,FLUX 席卷了互联网,这并非没有原因。他们声称优于 DALLE 3、Ideogram 和 Stable Diffusion 3 等模型,而这一点已被证明是有依据的。随着越来越多的流行图像生成工具(如 Stable Diffusion Web UI Forge 和 ComyUI)开始支持这些模型,FLUX 在 Stable Diffusion 领域的扩展将会持续下去。 自 FLU

xAI巨无霸超级计算机上线:10万张H100 GPU,计划翻倍至20万张
在短短四个多月的时间里,埃隆·马斯克的X公司(前身为Twitter)推出了世界上最强劲的人工智能训练系统。名为Colossus的超级计算机使用了多达10万张NVIDIA H100 GPU进行训练,并计划在未来几个月内再增加5万张H100和H200 GPU。 “本周末,xAI团队启动了我们的Colossus 10万张H100训练集群,”埃隆·马斯克在X平台上写道,“从头到尾只用了122天。Co
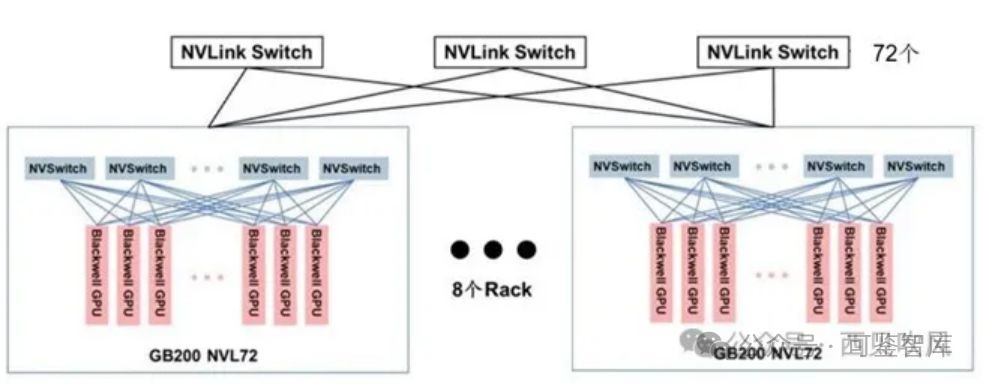
英伟达AI超级计算机SuperPod:H100→GH200→GB200
英伟达的 DGX SuperPOD 是一台完整的数据中心级 AI 超级计算机,采用模块化的设计,支持不同规模大小的设计。每台超级计算机都在出厂前完成了搭建、布线和测试,从而大大加快了在用户数据中心的部署速度 。 NVIDIA DGX SuperPOD是下一代数据中心人工智能(AI)架构,旨在提供AI模型训练、推理、高性能计算(HPC)和混合应用中的

英伟达(NVIDIA)H100性能及应用场景
英伟达H100是一款性能强大的GPU芯片,其关键性能参数和应用领域可以归纳如下: 一、性能参数 架构:H100采用了新一代的Hopper架构,拥有高达1.8万亿次/秒的张量处理能力和高达840 TFLOPS的FP8张量性能。CUDA核心数:H100的CUDA核心数达到了14592个,远超其前代产品。显存:H100采用了HBM3显存技术,显存带宽高达3TB/s,容量高达64GB(请注意,此处的显

Sora 的算力困局:如果正式推出,可能需要 72 万张 H100
在上个月推出视频生成模型 Sora 后,就在昨天,OpenAI 又发布了一系列创意工作者借助 Sora 进行的创作,效果极为惊艳。毫无疑问,就生成质量,Sora 是迄今为止最强的视频生成模型,它的出现不仅会直接对创意行业带来冲击,也会影响对机器人、自动驾驶领域的一些关键问题的解决。 虽然 OpenAI 发布了 Sora 的技术报告,但报告中关于技术细节的呈现极为有限,本文编译自 Facto
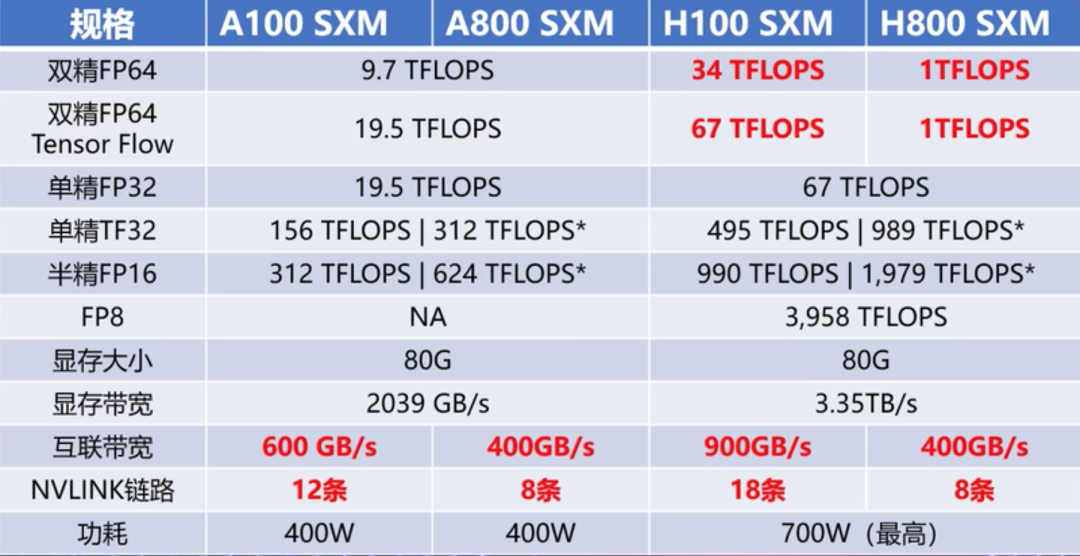
英伟达 V100、A100/800、H100/800 GPU 对比
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火。而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持。以 ChatGPT 为例,据微软高管透露,为 ChatGPT 提供算力支持的 AI 超级计算机,是微软在 2019 年投资 10 亿美元建造一台大型顶尖超级计算机,配备了数万个 NVIDIA A100 GPU,还配备了 60 多个数据中心总共部
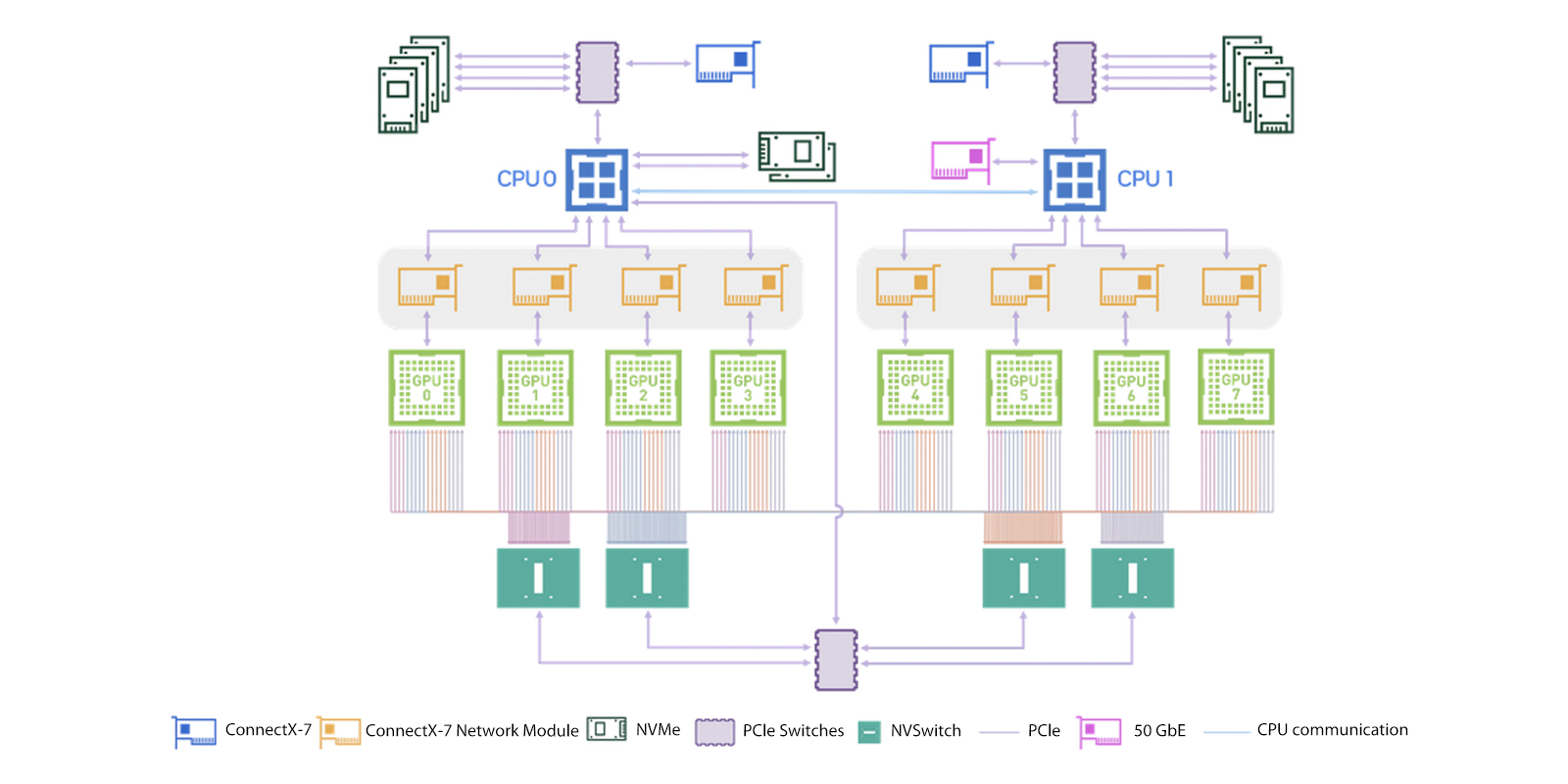
NVIDIA DGX H100概述
NVIDIA DGX H100系统是一种专为AI基础架构和工作负载而设计的专用多功能解决方案,涵盖了从分析和训练到推理的各种应用场景。它包括NVIDIA Base Command™和NVIDIA AI企业软件套件,以及来自NVIDIA DGXperts的专业建议。 DGX H100硬件和组件特性 硬件概述 NVIDIA DGX H100 640GB系统包括以下组件。 前面板连接和控
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比。 英伟达系列显卡大解析B100、H200、L40S、A100、A800、H100、H800、V100如何选择,含架构技术和性能对比带你解决疑惑。 近期,AIGC领域呈现出一片繁荣景象,其背后离不开强大算力的支持。以ChatGPT为例,其高效的运行依赖于一台由微软投资建造的超级计算机。这台超

苏妈战老黄!官宣AMD大模型专用卡,对标英伟达H100,可跑更大模型
萧箫 发自 凹非寺量子位 | 公众号 QbitAI 苏妈发布最新AMD加速卡,直接宣战英伟达! 没错,就在AMD推出最新加速卡Instinct MI300X的现场,PPT上专门打出一行字—— 大语言模型专用。 AMD表示,MI300X的高带宽内存(HBM)密度,最高可达英伟达H100的2.4倍,高带宽内存带宽最高可达H100的1.6倍,显然MI300X能运行比H100更大的AI模型。 MI30

极智一周 | 两系列汇总、MI300X、H100、特供芯片、GPT-4、火灾检测、酷睿Ultra And so on
欢迎关注我的公众号 [极智视界],获取我的更多技术分享 大家好,我是极智视界,带来本周的 [极智一周],关键词:两系列汇总、MI300X、H100、特供芯片、GPT-4、火灾检测、酷睿Ultra And so on。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 极智视界本周热点文章回

比黄金更贵的显卡,疯狂H100
华尔街和硅谷联袂奉上了一件震撼业界的大事:让一家创业公司拿到23亿美元的债务融资,抵押物则是当前全球最硬的通货——H100显卡。 这个大事件的主角叫做CoreWeave,主营业务是AI私有云服务,简单说就是通过搭建拥有大量GPU算力的数据中心,来给AI创业公司和大型商业客户提供算力基础设施。CoreWeave累计融资5.8亿美金,目前是B轮,估值20亿美元。 CoreWeave成立于2016年
极智开发 | 一文看透H100 Hopper架构的各种提升
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文分享一下 一文看透H100 Hopper架构的各种提升。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 在 2022 年 3 月发布的 H100,应该算目前英伟达 GPU 的巅峰之作了,但仅限于目前的巅峰,下一代
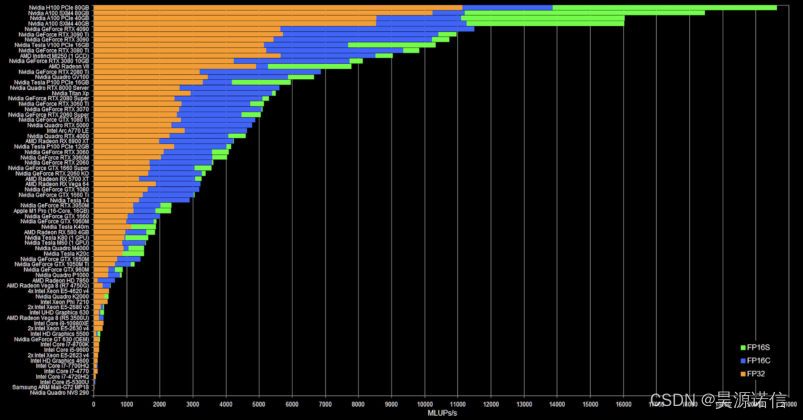
NVIDIA H100 80GB PCIe 动手进行 CFD 仿真
NVIDIA H100 80GB PCIe 动手进行 CFD 仿真 首先,我们有测试系统。这是在 NUMA 节点 L1 上具有 114 个计算单元和 80GB 内存的 OpenCL 设备的系统: 这是卡的 nvidia-smi 输出: 至于功耗,我们认为 68-70W 是相当正常的。310W 的最大功耗似乎有点高,但我们确实在某些 AI 工作负载上达到了这个数字。 尽管如此,我们还是想突出
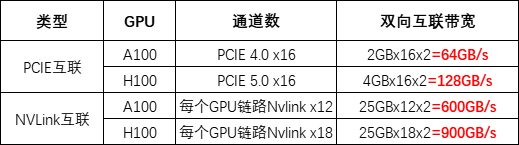
深度学习模型部署与优化:策略与实践;L40S与A100、H100的对比分析
★深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800 随着生成式AI应用的迅猛发展,我们正处在前所未有的大爆发时
深度学习模型部署与优化:策略与实践;L40S与A100、H100的对比分析
★深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800 随着生成式AI应用的迅猛发展,我们正处在前所未有的大爆发时