本文主要是介绍苏妈战老黄!官宣AMD大模型专用卡,对标英伟达H100,可跑更大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
苏妈发布最新AMD加速卡,直接宣战英伟达!
没错,就在AMD推出最新加速卡Instinct MI300X的现场,PPT上专门打出一行字——
大语言模型专用。

AMD表示,MI300X的高带宽内存(HBM)密度,最高可达英伟达H100的2.4倍,高带宽内存带宽最高可达H100的1.6倍,显然MI300X能运行比H100更大的AI模型。
MI300X所在的MI300系列,是AMD为AI和高性能计算(HPC)打造的一系列最新APU加速卡。
其中,MI300A是“基础款”,MI300X则是硬件性能更高的“大模型优化款”。

苏妈还现场演绎MI300X的计算速度,利用抱抱脸的400亿参数大模型快速写了首小诗:

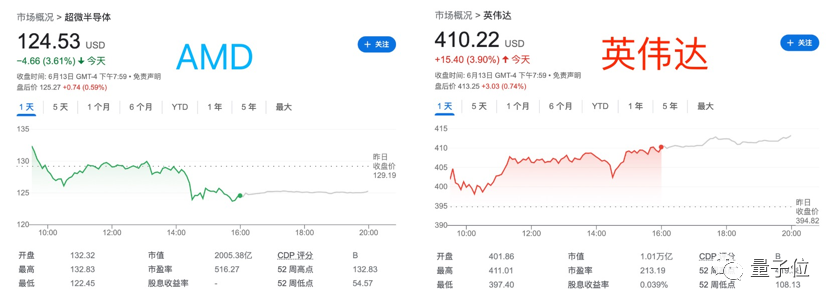
遗憾的是,市场对AMD的新卡好像不太买账。
就在这次AMD发布会期间,市场股价一路下跌,开完后甚至跌了3.61%……相比之下,英伟达股价还上涨了一波。
不过仍有网友表示惊喜:
尽管股价波动,这可能是第一次有这么大的模型(400亿参数)在单卡GPU上运行。
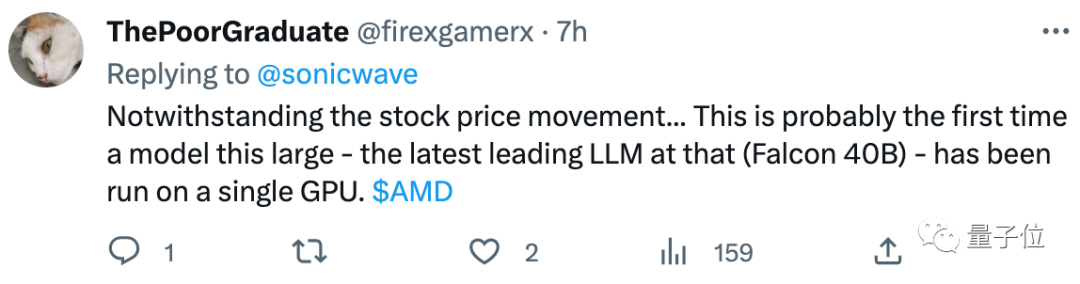
所以,AMD最新MI300系列的参数细节如何?
“LLM专用加速卡”
先来看看Instinct MI300A的情况。
据苏妈介绍,MI300A应该是首个针对AI和高性能计算(HPC)推出的APU。
它一共有13个小芯片,包含9个5nm制程GPU+CPU,以及4个6nm制程的小芯片(base dies),包含1460亿个晶体管,其中有24个Zen 4 CPU核心,1个CDNA 3图形引擎,128GB的HBM3内存。
相比MI250,MI300的性能提升了8倍,效率提升了5倍。

再来看看Instinct MI300X。
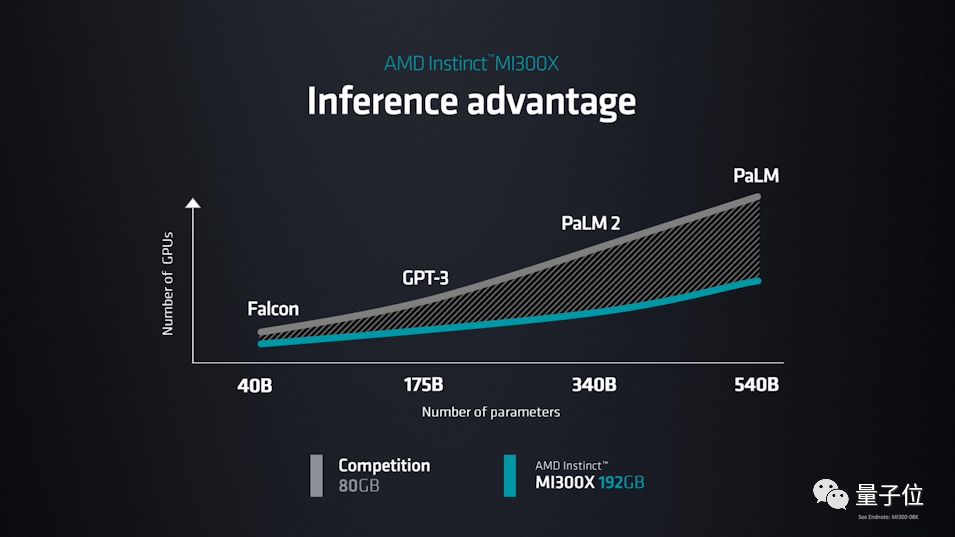
这是针对大语言模型(LLM)专用的卡,包含12个小芯片,1530亿个晶体管,192GB的HBM3内存,内存带宽达到5.2TB/s,Infinity Fabric带宽达到896GB/s。

苏妈还现场展示了MI300X运行包括GPT-3、PaLM2等大模型的优势:
在发布MI300X的现场,苏妈还现场运行了Hugging Face 的falcon-40b-instruct模型,写了首关于旧金山(这次AMD发布会地址)的小诗。

除此之外,AMD这次发布会还发布了第四代霄龙(EPYC)处理器,包括亚马逊、微软和Meta都已经在着手准备用上新品了。
预计今年Q4推出
除了最新推出的霄龙处理器、MI300A和MI300X以外,AMD还在发布会上宣布了一个AMD Instinct计算平台。
这个平台集成了8个MI300X,可提供1.5TB的HBM3内存。

那么,这些新卡和新平台,预计什么时候能出货?
目前来看,MI300A已经出样,估计不久就能买上;大模型专用卡MI300X、以及集成8个MI300X的AMD Instinct计算平台,预计今年第三季度出样,第四季度就能推出。
但这几年来,相比英伟达一直在AI上面有大动作,AMD的行动却好像有点迟缓。
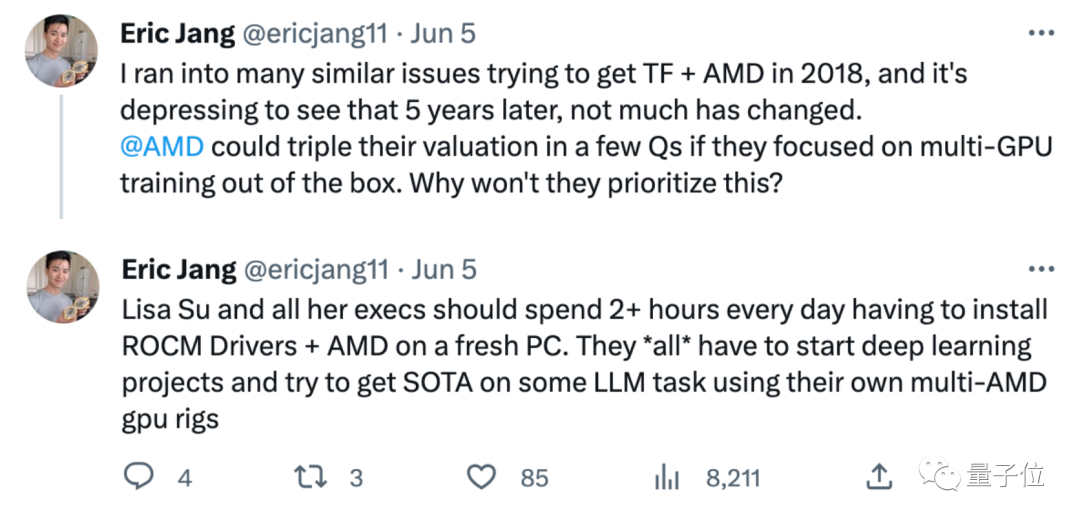
就在这次发布会前几天,DeepBrain AI的CEO Eric Jang发推表示,感觉AMD这几年让他很失望,5年来没什么变化:
苏妈和她的所有高管,至少该开始尝试用AMD卡跑一些大模型,看看能不能达到SOTA。
Eric Jang指出,AMD和英伟达已经存在一定差距。
如果AMD不努力跟上,差距只会越拉越大:
老黄(Jensen)很硬核,他不仅会亲自回应客户并在12小时内解决问题,手臂上还纹着英伟达的LOGO。
相比之下,AMD至少需要加倍努力,否则它将永远追不上英伟达。

好消息是,AMD至少开始行动了。这次发布会结束,就有网友表示:
至少,现在终于能看到AMD和NVIDIA正面打擂台了。
你看好AMD的新卡吗?
参考链接:
[1]https://www.anandtech.com/show/18915/amd-expands-mi300-family-with-mi300x-gpu-only-192gb-memory
[2]https://www.tomshardware.com/news/amd-expands-mi300-with-gpu-only-model-eight-gpu-platform-with-15tb-of-hbm3
[3]https://twitter.com/ericjang11/status/1665618676354109440
— 完 —
「AIGC+垂直领域社群」
招募中!
欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC!
请备注您想加入的垂直领域「教育」或「电商零售」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。

点这里👇关注我,记得标星哦~
这篇关于苏妈战老黄!官宣AMD大模型专用卡,对标英伟达H100,可跑更大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








