groupbykey专题

深入理解groupByKey、reduceByKey
测试源码 下面来看看groupByKey和reduceByKey的区别: val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")val sc = new SparkContext(conf)val words = Array("one", "two", "two", "three", "thr

Spark groupbykey和cogroup使用示例
groupByKey groupByKey([numTasks])是数据分组操作,在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。 val rdd0 = sc.parallelize(Array((1,1), (1,2) , (1,3) , (2,1) , (2,2) , (2,3)), 3) val rdd1 = rdd0.groupByKey() rdd1.co
Spark算子:RDD键值转换操作(3)–groupByKey、reduceByKey、reduceByKeyLocally
groupByKey def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] 该函数用于将RDD[K,V]中每个K对应

(转)groupByKey 和reduceByKey 的区别
【转载原文:https://blog.csdn.net/ZMC921/article/details/75098903】 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 本文链接:https://blog.csdn.net/ZMC921/article/details/75098903 一、首先他们都是要经过shuffle的,g
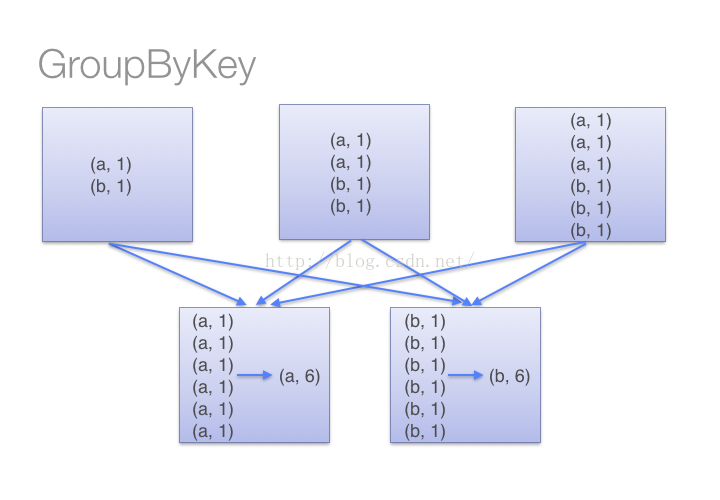
spark的reduceByKey和groupByKey比较
在spark中,我们知道一切的操作都是基于RDD的。在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式。这种格式很像Python的字典类型,便于针对key进行一些处理。 针对pair RDD这样的特殊形式,spark中定义了许多方便的操作,今天主要介绍一下reduceByKey和groupByKey,因为在接

Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四) 声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallel

Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、look
1、以本地模式实战map和filter 2、以集群模式实战textFile和cache 3、对Job输出结果进行升和降序 4、union 5、groupByKey 6、join 7、reduce 8、lookup 1、以本地模式实战map和filter 以local的方式,运行spark-shell。 spark@SparkSingleNo
spark【例子】同类合并、计算(主要使用groupByKey)
例子描述: 【同类合并、计算】 主要为两部分,将同类的数据分组归纳到一起,并将分组后的数据进行简单数学计算。 难点在于怎么去理解groupBy和groupByKey 原始数据 2010-05-04 12:50,10,10,10 2010-05-05 13:50,20,20,20 2010-05-06 14:50,30,30,30 2010-05-05 13:50,20,20,

Spark API编程动手实战-04-以在Spark 1.2版本实现对union、groupByKey、join、reduce、lookup等操作实践
下面看下union的使用: 使用collect操作查看一下执行结果: 再看下groupByKey的使用: 执行结果: join操作就是一个笛卡尔积操作的过程,如下示例: 对rdd3和rdd4执行join操作: 使用collect查看执行结果: 可以看出join操作完全就是一个笛卡尔积的操作; reduce本身在
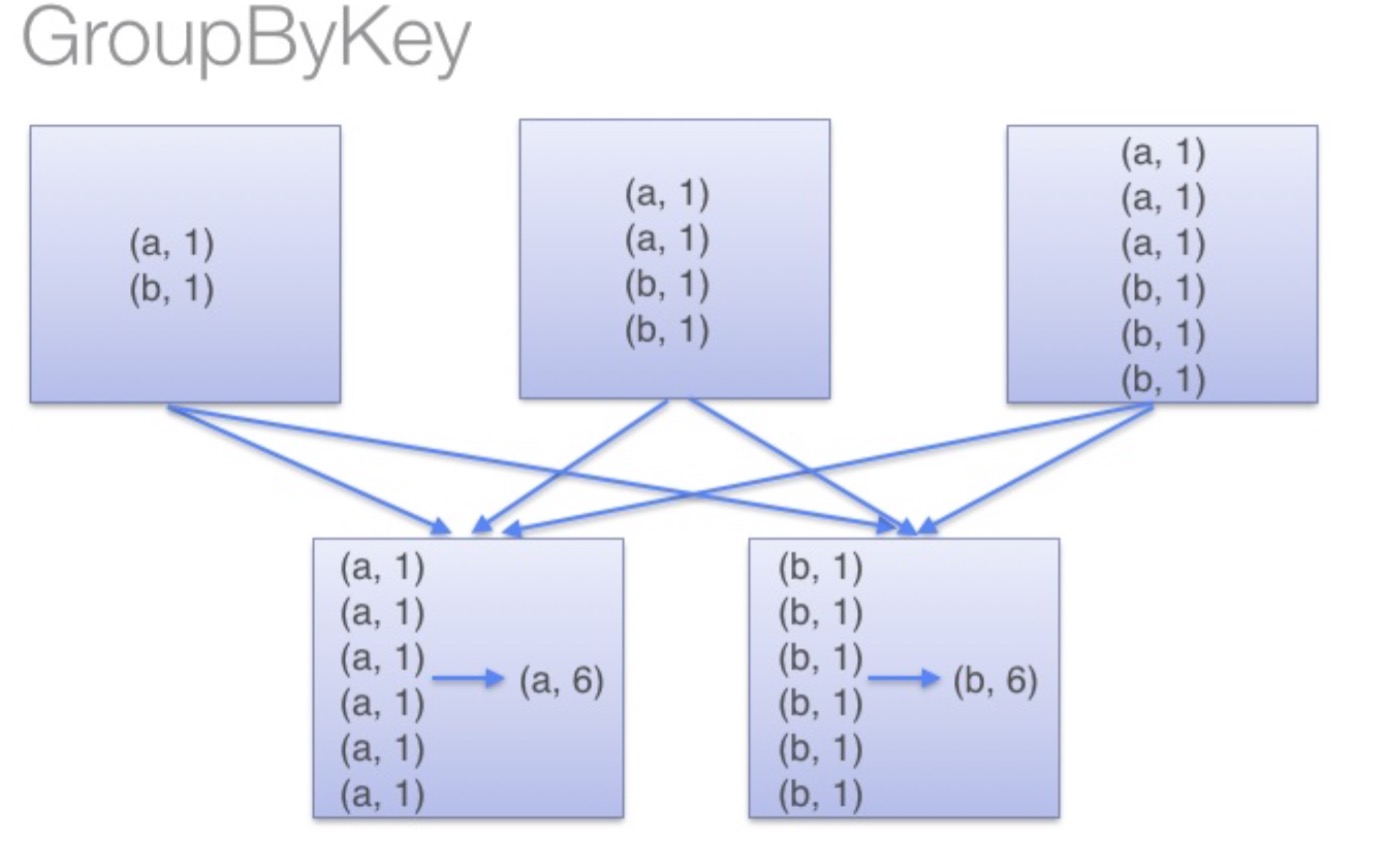
groupByKey与reduceByKey
贴一段经典的代码: val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")val sc = new SparkContext(conf)val words = Array("one", "two", "two", "three", "three", "three")val wordsRDD =