本文主要是介绍groupByKey与reduceByKey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
贴一段经典的代码:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")val sc = new SparkContext(conf)val words = Array("one", "two", "two", "three", "three", "three")val wordsRDD = sc.parallelize(words).map(word => (word, 1))val wordsCountWithReduce = wordsRDD.reduceByKey(_ + _).collect().foreach(println)val wordsCountWithGroup = wordsRDD.groupByKey().map(w => (w._1, w._2.sum)).collect().foreach(println)
虽然两个函数都能得出一样正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
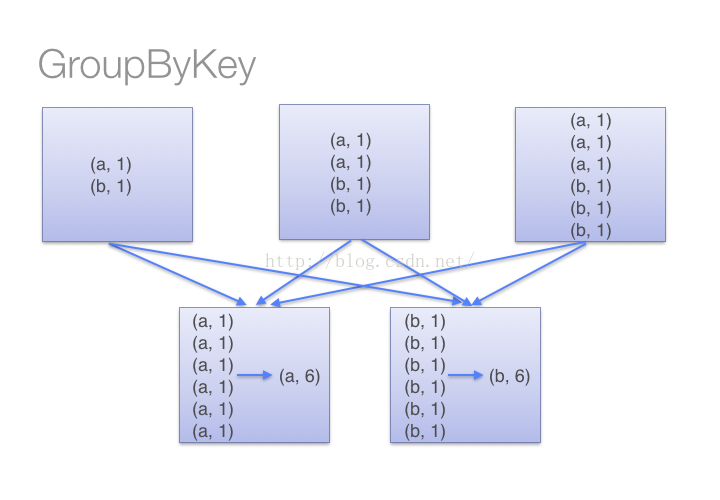
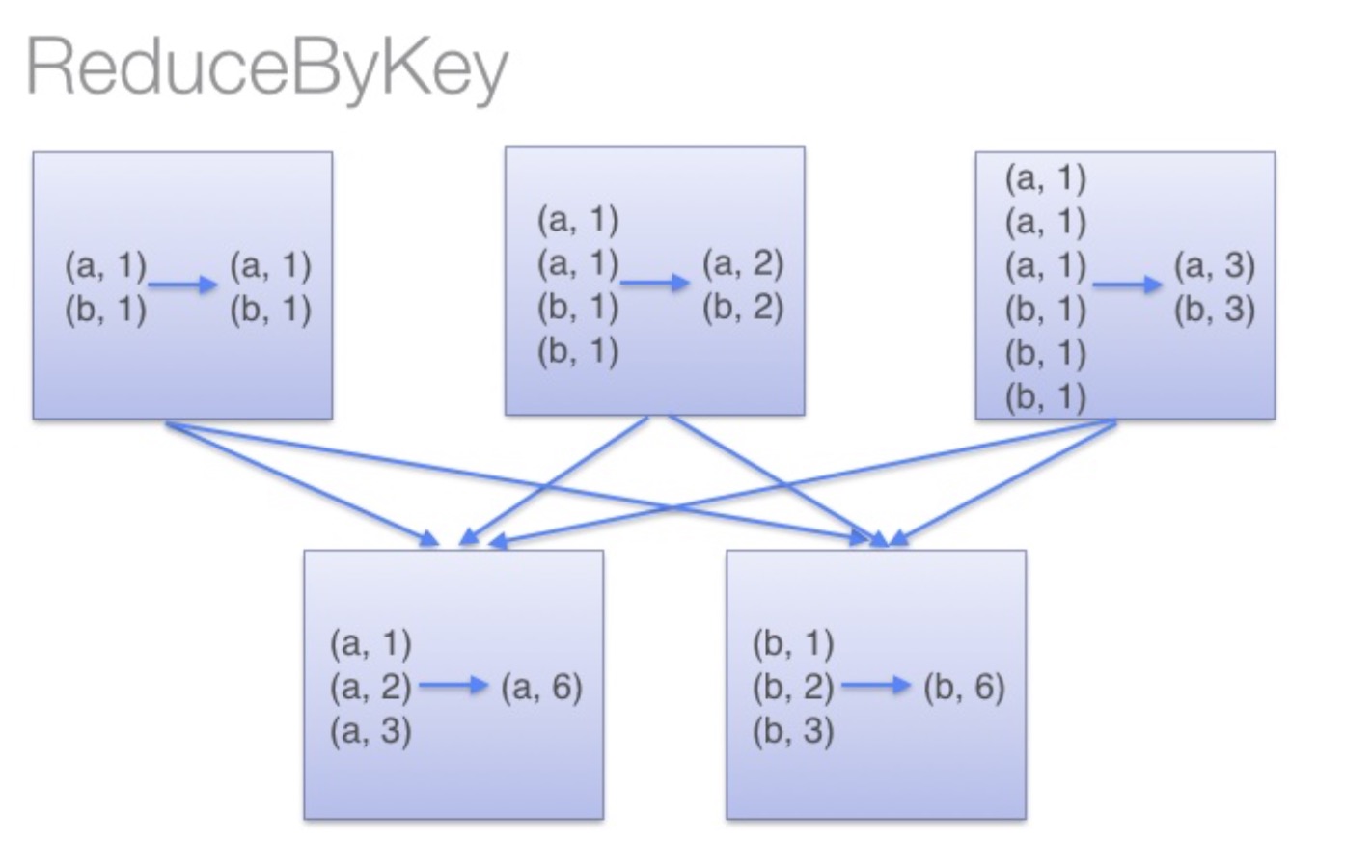
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
当调用 groupByKey时,所有的键值对都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
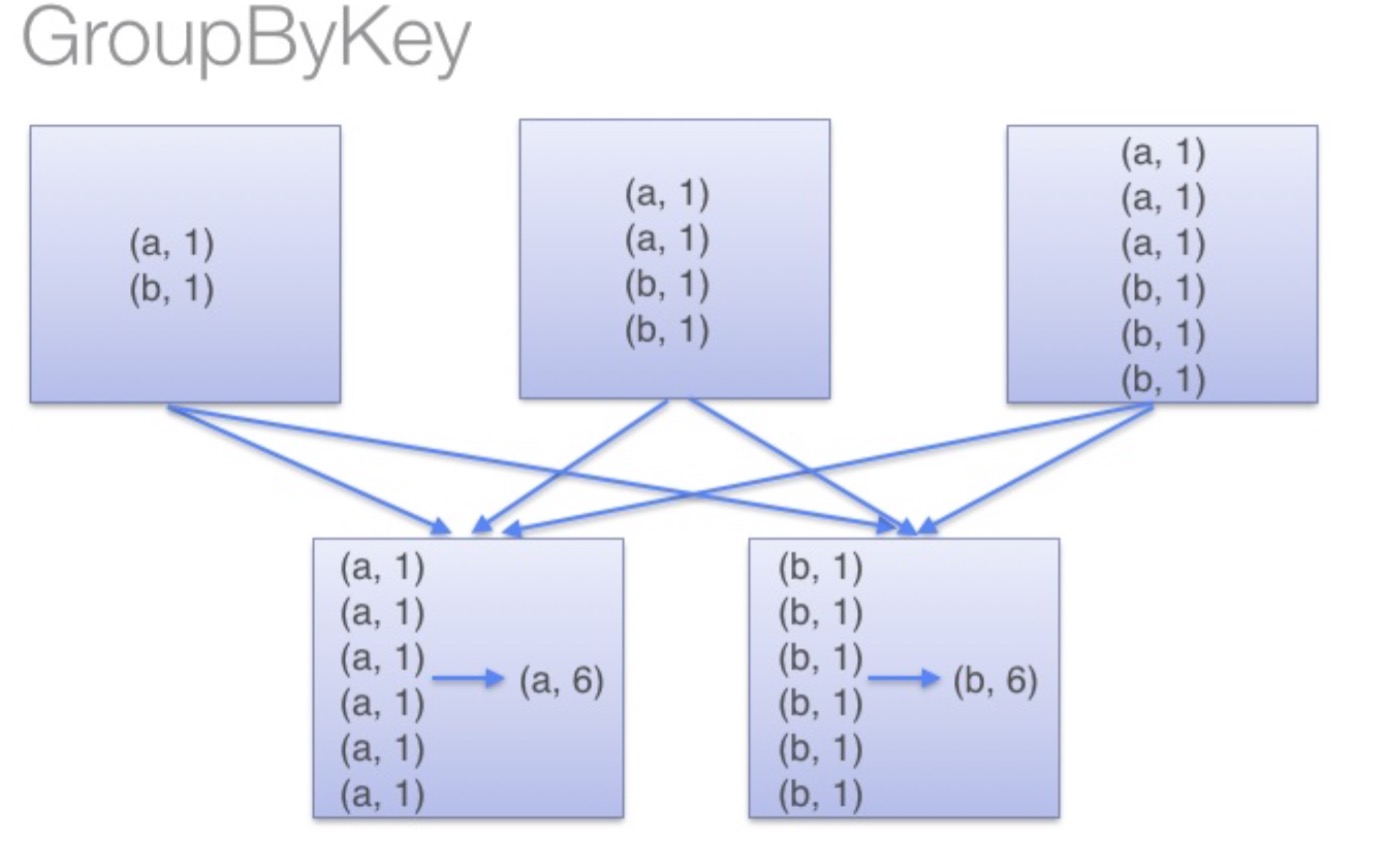
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
官方文档(spark2.1.1):
| groupByKey([numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. 如果要分组以便在每个键上执行聚合(如总和或平均值),则使用reduceByKey或aggregateByKey将会产生更好的性能。 默认情况下,输出中的并行级别取决于父RDD的分区数。您可以传递一个可选的numTasks参数来设置不同数量的任务。 |
| reduceByKey(func, [numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. 其中每个密钥的值使用给定的reduce函数func进行聚合,该函数必须是类型(V,V)=> V。与groupByKey类似,reduce任务的数量可以通过可选的第二个参数进行配置。 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. 其中每个键的值使用给定的组合函数和中性“零”值进行聚合。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。像groupByKey一样,reduce任务的数量可以通过可选的第二个参数进行配置。 |
这篇关于groupByKey与reduceByKey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!