glue专题

掌握数据利器:AWS Glue与数据基盘概览
引言 随着数字化进程的不断推进,企业现在能够积累并分析海量且多样化的数据。这一优势使得许多企业开始采用数据驱动型经营(即基于数据的经营策略)。通过基于数据的客观判断,企业及其管理者可以获得诸多好处。 然而,要充分利用所积累的数据,就需要建立一个坚实的数据基础设施。然而,这并不是一次性完成的任务。随着企业日常运营中数据量和种类的不断增加,需要持续优化性能、调整设计,并引入适合的工具和解决方案。

aws glue配置读取本地kafka数据源
创建连接时填写本地私有ip地址,选择网络配置 配置任务选择kafka作为数据源 但是执行任务时日志显示连接失败 文档提到只能用加密通信 如果您希望与 Kafka 数据源建立安全连接,请选择 Require SSL connection (需要 SSL 连接),并在 Kafka private CA certificate location (Kafka 私有 CA 证书位置)

企业如何使用SNP Glue将SAP与Snowflake集成?
SNP Glue是SNP的集成技术,适用于任何云平台。它最初是围绕SAP和Hadoop构建的,现在已经发展为一个集成平台,虽然它仍然非常专注SAP,但可以将几乎任何数据源与任何数据目标集成。 我们客户非常感兴趣的数据目标之一是Snowflake。Snowflake是一个基于云的数据仓库平台,旨在处理和分析大量数据。它是一种软件即服务(SaaS)解决方案,允许组织使用云基础设施存储、管理和分析

R语言 glue 版本冲突
namespace ‘glue’ is imported by ‘tidyselect’, ‘dplyr’ so cannot be unloaded 报错原因是dplyr和tidyselect两个包所要求的glue版本不同。把glue更新到最新版本即可,可以需要源码编译。

NLP-预训练模型:迁移学习(拿已经训练好的模型来使用)【预训练模型:BERT、GPT、Transformer-XL、XLNet、RoBerta、XLM、T5】、微调、微调脚本、【GLUE数据集】
深度学习-自然语言处理:迁移学习(拿已经训练好的模型来使用)【GLUE数据集、预训练模型(BERT、GPT、transformer-XL、XLNet、T5)、微调、微调脚本】 一、迁移学习概述二、NLP中的标准数据集1、GLUE数据集合的下载方式2、GLUE子数据集的样式及其任务类型2.1 CoLA数据集【判断句子语法是否正确】2.2 SST-2数据集【情感分类】2.3 MRPC数据集【判断
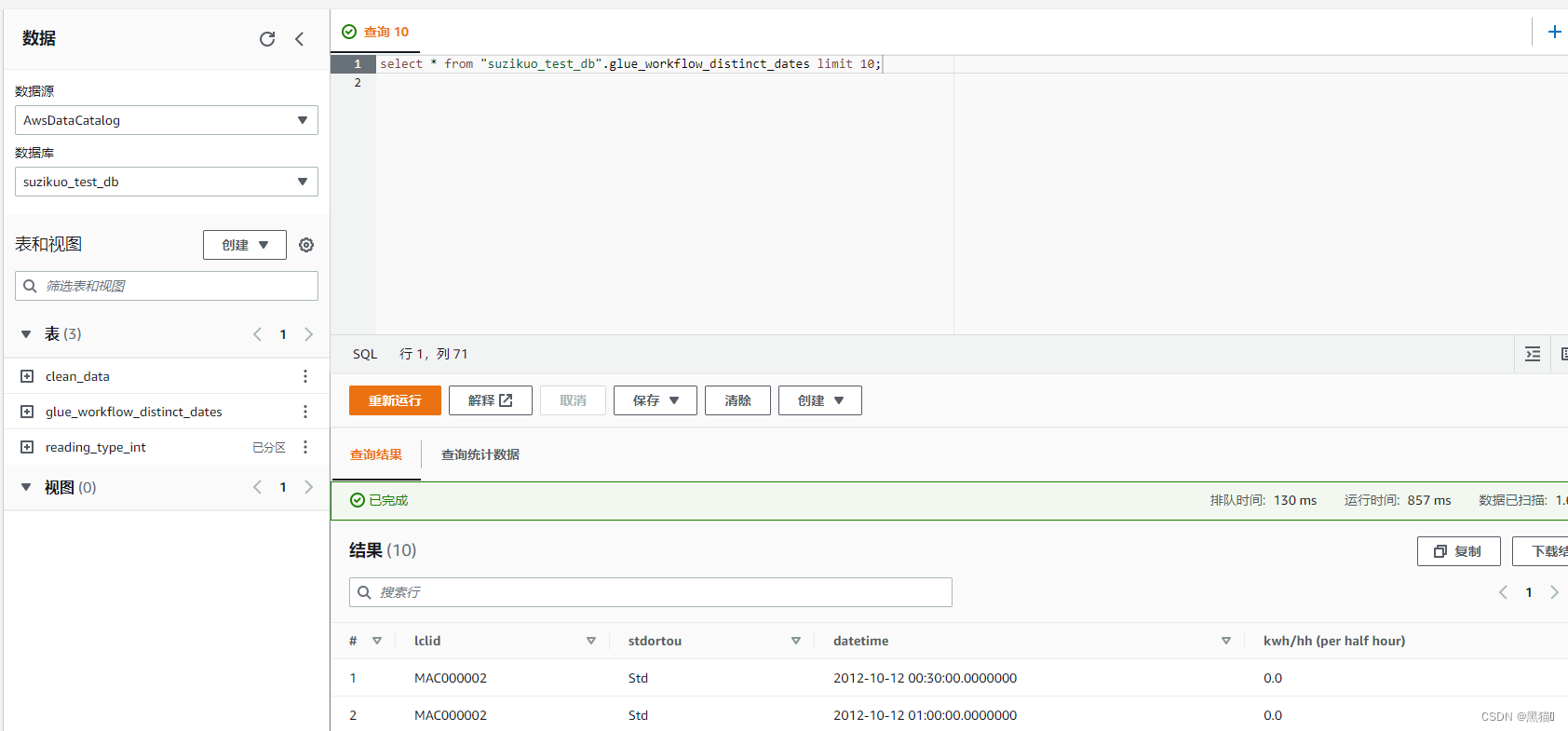
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(一)——创建Glue
1 通过Athena查询s3中的数据 此实验使用s3作为数据源 ETL: E extract 输入 T transform 转换 L load 输出 大纲 1 通过Athena查询s3中的数据1.1 架构图1.2 创建Glue数据库1.3 创建爬网程序1.4 创建表1.4.1 爬网程序创建表1.4.2 手动创建表

SNP推出新Glue软件Saas版本,助力云数据集成
最新Glue版本可作为软件即服务(SaaS)应用程序使用SAP数据和非SAP数据源之间的云原生集成大大简化了客户的企业数据集成SNP Glue通过应对AI和大数据计划中的关键挑战来增强云数据集成的价值 德国,海德堡 —— 2023年11月29日,作为SAP环境中数字化转型、自动化数据迁移和数据管理软件的领先供应商,SNP 推出了新的SNP Glue软件,作为CrystalBrid
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(二)——数据清洗、转换
2 数据清洗、转换 此实验使用S3作为数据源 ETL: E extract 输入 T transform 转换 L load 输出 大纲 2 数据清洗、转换2.1 架构图2.2 数据清洗2.3 编辑脚本2.3.1 连接数据源(s3)2.3.2. 数据结构转换2.3.2 数据结构拆分、定义2.3.3 清洗后的数据写入
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(一)——创建Glue
1 通过Athena查询s3中的数据 此实验使用s3作为数据源 ETL: E extract 输入 T transform 转换 L load 输出 大纲 1 通过Athena查询s3中的数据1.1 架构图1.2 创建Glue数据库1.3 创建爬网程序1.4 创建表1.4.1 爬网程序创建表1.4.2 手动创建表

ETL工具——AWS Glue、Glue的执行原理、ETL的三大组件
ETL的三大组件 一般来说,ETL分为3大核心组件: 输入 - E - extract转换 - T - transform输出 - L - load 输入 输入即ETL工作的源头。 转换 转换一般为ETL的核心,也就是我们从输入读取数据后,经过怎么样的操作,让数据变成我们想要的样子后,在输出。 输出 输出好理解,就是数据处理完毕后,写入到哪里。 根据项目架构图: 我们输入源

xxl-job(2.3.0)分布式任务bean模式,GLUE shell调度实践,源码debug
一、xxl-job分布式任务调度入门参考 1.分布式任务调度平台XXL-JOB官网文档 2.其它简单入门案例 二、调度中心简单的源码修改 1.源码git clone http://gitee.com/xuxueli0323/xxl-job 2.修改配置文件,修改了MYSQL EMAIL配置,新增钉钉配置。配置文件多环境支持application-test.properties、applica

XXL-Job使用GLUE(Java)调度REST接口
这里就不介绍xxl-job的使用教程了,很简单很好用。 本次仅仅分享使用xxl-job调用REST接口的过程。 首先xxl-job-admin你应该先跑起来,然后新建一个SpringBoot项目里面加上xxl-job的依赖,xxl-job的config等配置信息 Maven中加入xxl-job-core的依赖 <!-- ===========XXL-JOB-CORE============
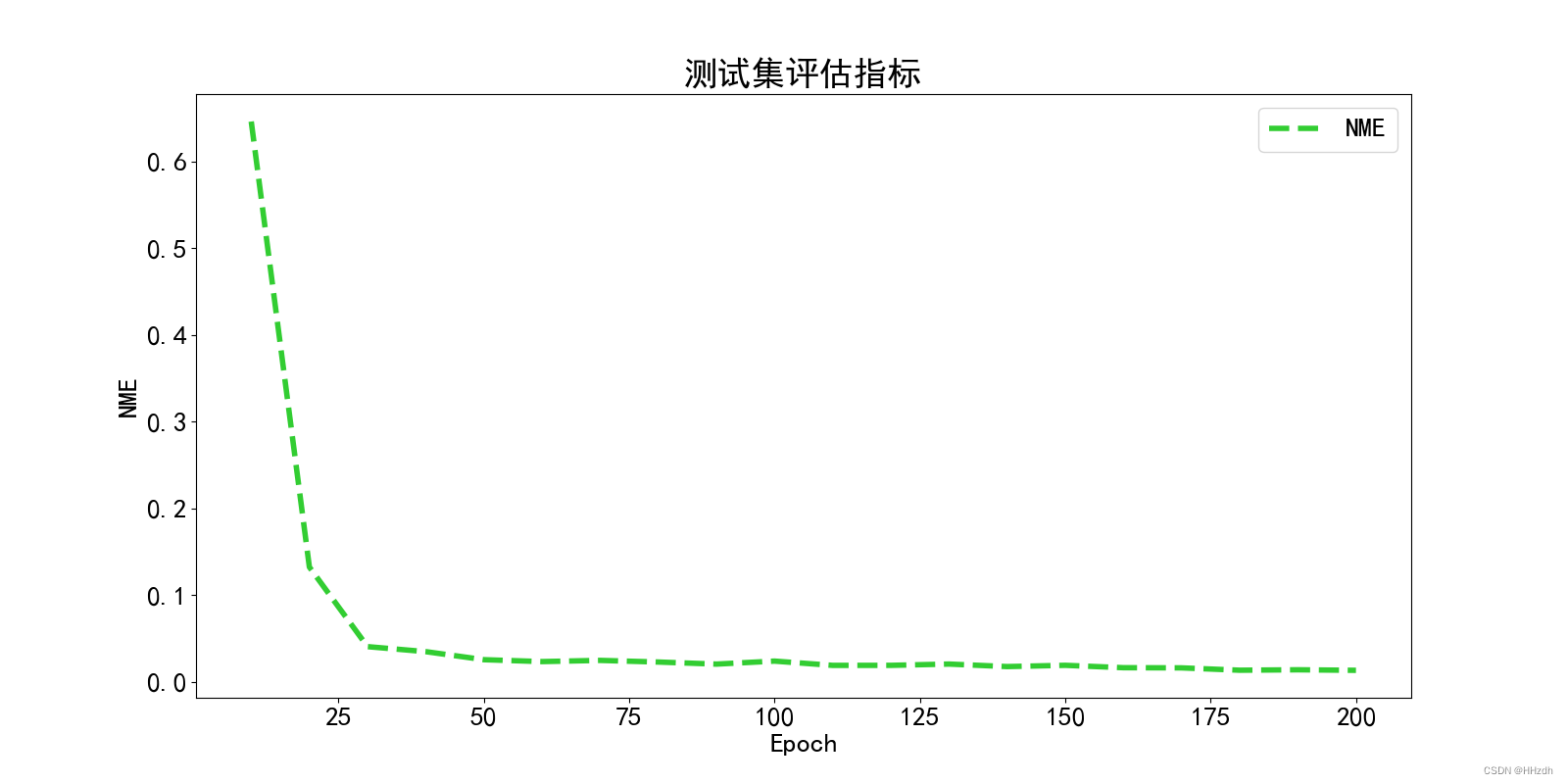
从零开始的目标检测和关键点检测(三):训练一个Glue的RTMPose模型
从零开始的目标检测和关键点检测(三):训练一个Glue的RTMPose模型 一、重写config文件二、开始训练三、ncnn部署 从零开始的目标检测和关键点检测(一):用labelme标注数据集 从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型 一、重写config文件 1、数据集类型即coco格式的数据集,在dataset_info声明classes

从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型
从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型 一、config文件解读二、开始训练三、数据集分析四、ncnn部署 从零开始的目标检测和关键点检测(一):用labelme标注数据集 从零开始的目标检测和关键点检测(三):训练一个Glue的RTMPose模型 在[1]用labelme标注自己的数据集中已经标注好数据集(关键点和检测框),通过labelme

Windows下使用Glue 生成 CSS spite
为什么80%的码农都做不了架构师?>>> ##Windows下使用Glue 生成 CSS spite 更多平台下的使用方法请参考官网 Glue官网 ###准备工作 如何本地没有安装Python2.7的话 需要安装一下. Python 2.7.2 Windows installer.安装 PIL(Python Imaging Library) (PIL-1.1.7 for Python

SNP Glue:SAP数据导入到其他系统的多种方式
SAP是一款功能强大的企业资源计划(ERP)软件,许多企业依赖SAP来管理和处理其核心业务数据。然而,有时候企业需要将SAP中的数据导入到其他系统中,以实现更广泛的数据共享和集成,便于企业实现数据智能。本文将介绍几种常见的方式,帮助企业了解如何将SAP数据导入到其他系统中。 批量导出与导入: 通过SAP的数据导出功能,可以将数据以批量方式导出为常见的数据格式,如CSV、Excel等。