finetune专题

使用 VisionTransformer(VIT) FineTune 训练驾驶员行为状态识别模型
一、VisionTransformer(VIT) 介绍 大模型已经成为人工智能领域的热门话题。在这股热潮中,大模型的核心结构 Transformer 也再次脱颖而出证明了其强大的能力和广泛的应用前景。Transformer 自 2017年由Google提出以来,便在NLP领域掀起了一场革命。相较于传统的循环神经网络(RNN)和长短时记忆网络(LSTM), Transformer 凭借自注意力机制

pytorch Finetune和各层定制学习率
文章目录 一、Finetune之权值初始化 第一步:保存模型参数 第二步:加载模型 第三步:初始化 二、不同层设置不同的学习率 补充: 我们知道一个良好的权值初始化,可以使收敛速度加快,甚至可以获得更好的精度。而在实际应用中,我们通常采用一个已经训练模型的模型的权值参数作为我们模型的初始化参数,也称之为Finetune,更宽泛的称之为迁移学习。迁移学习中的Finetune技术,本质上就是让我们新

prompt,RAG,finetune,从零训练大模型对比
Prompt Engineering RAG 微调 从零训练大模型通过提供少量示例提供尽可能多的上下文,使基础模型更好地了解用例增加了直接来自向量化信息存储的特定于用例的上下文在特定领域的数据上更新模型权重模型是在用例特定数据上从零开始训练的准确性与其他方法相比,它产生的结果最不准确与Prompt Engineering相比,它产生的结果大大改善,而且产生幻觉的可能性非常低也提供了相当精确的结果

【Python】科研代码学习:八 FineTune PretrainedModel (用 trainer,用 script);LLM文本生成
【Python】科研代码学习:八 FineTune PretrainedModel [用 trainer,用 script] LLM文本生成 自己整理的 HF 库的核心关系图用 trainer 来微调一个预训练模型用 script 来做训练任务使用 LLM 做生成任务可能犯的错误,以及解决措施 自己整理的 HF 库的核心关系图 根据前面几期,自己整理的核心库的使用/继承关系
Prompt Engineering、Finetune、RAG:OpenAI LLM 应用最佳实践
一、背景 本文介绍了 2023 年 11 月 OpenAI DevDay 中的一个演讲,演讲者为 John Allard 和 Colin Jarvis。演讲中,作者对 LLM 应用落地过程中遇到的问题和相关改进方案进行了总结。虽然其中用到的都是已知的技术,但是进行了很好的总结和串联,并探索了一条改进 LLM 应用的切实可行的路线,提供了一个最佳实践。 对应的 YouTube 视频:A Surv
Axolotl:一款极简的大模型微调(Finetune)开源框架
今天给大家分享一款工具,Axolotl[1] 是一个旨在简化各种AI模型的微调过程的工具,支持多种配置和架构。 特点: 可训练各种 Huggingface 模型,如 llama、pythia、falcon、mpt支持 fullfinetune、lora、qlora、relora 和 gptq使用简单的 yaml 文件或 CLI 覆盖来自定义配置加载不同的数据集格式,使用自定义格式,或使用您自己

pytorch11:模型加载与保存、finetune迁移训练
目录 一、模型加载与保存1.1 序列化与反序列化概念1.2 pytorch中的序列化与反序列化1.3 模型保存的两种方法1.4 模型加载两种方法 二、断点训练2.1 断点保存代码2.2 断点恢复代码 三、finetune3.1 迁移学习3.2 模型的迁移学习3.2 模型微调步骤3.2.1 模型微调步骤3.2.2 模型微调训练方法 3.3 迁移训练实验 一、模型加载与保存 1

3 文本分类入门finetune:bert-base-chinese
项目实战: 数据准备工作 `bert-base-chinese` 是一种预训练的语言模型,基于 BERT(Bidirectional Encoder Representations from Transformers)架构,专门用于中文自然语言处理任务。BERT 是由 Google 在 2018 年提出的一种革命性的预训练模型,通过大规模的无监督训练,能够学习到丰富的语言表示
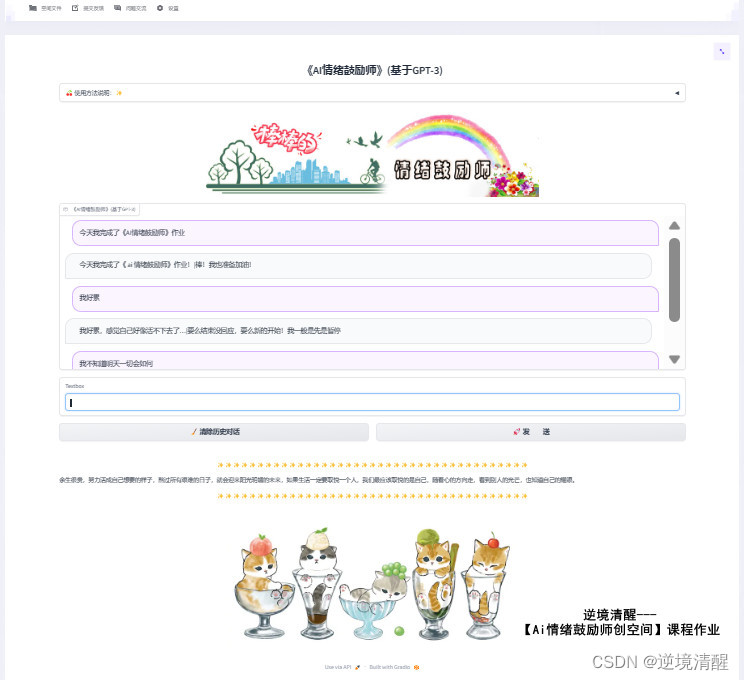
心情不好时,帮自己训练个AI情绪鼓励师吧(基于PALM 2.0 finetune)
心情不好时,帮自己训练个AI情绪鼓励师吧 (基于PALM 2.0 finetune) 目录 一、写在前面的话 二、前言 三、获取用于finetune的“夸夸”数据集 四、 获取并finetune PALM 2.0 预训练生成模型 模型 五、模型调用应用 一、写在前面的话 从小我就是极端内向和社恐的孩子,我普通之极并不出色,不想被人拿来比较,所以喜欢

利用caffe-ssd对钢材表面缺陷数据集(NEUDataset)进行finetune训练和测试
本篇博客主要讲述如何使用ssd在Caffe下针对自己的数据集进行finetune训练 NEUDataset介绍LMDB数据集制作将数据集分为trainval和test获得trainval.txt和test.txt修改labelmap文件生成LMDB数据集 使用caffe-ssd进行网络训练代码修改网络说明及修改实验结果 本篇博客主要讲解如何使用在VOC0712数据集下训练好的