本文主要是介绍Axolotl:一款极简的大模型微调(Finetune)开源框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给大家分享一款工具,Axolotl[1] 是一个旨在简化各种AI模型的微调过程的工具,支持多种配置和架构。
特点:
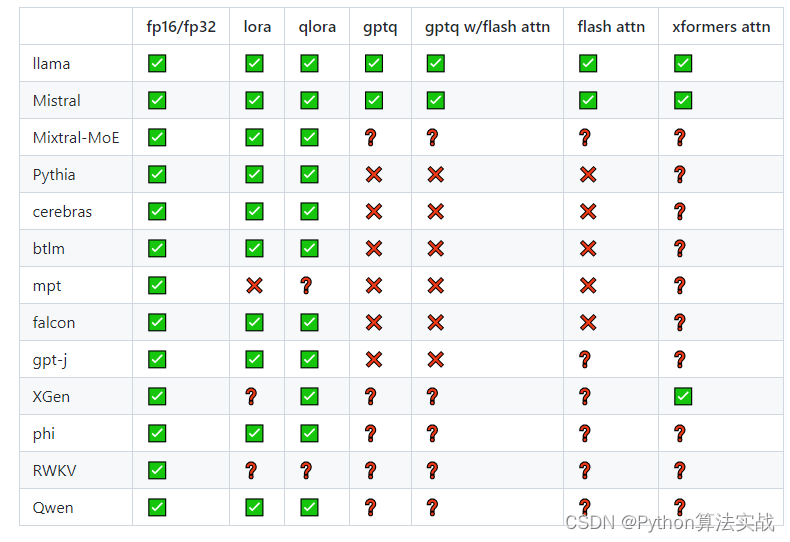
- 可训练各种 Huggingface 模型,如 llama、pythia、falcon、mpt
- 支持 fullfinetune、lora、qlora、relora 和 gptq
- 使用简单的 yaml 文件或 CLI 覆盖来自定义配置
- 加载不同的数据集格式,使用自定义格式,或使用您自己的分词数据集
- 集成了 xformer、flash attention、rope scaling 和 multipacking
- 可通过 FSDP 或 Deepspeed 在单个 GPU 或多个 GPU 上运行
- 可在本地或云端轻松使用 Docker 运行
- 记录结果并可选择将检查点保存到 wandb
- 还有更多功能!
支持的模型
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

什么是 fine-tuning?
预训练模型主要获得的是一般的语言知识,而缺乏对特定任务或领域的具体知识。为了弥补这一差距,接下来进行微调的步骤。
微调使我们能够专注于预训练模型的能力,并优化其在下游特定任务上的性能。
Fine-tuning 意味着对一个预训练模型进行进一步训练,使用新的任务和新的数据。通常,这意味着对整个预训练模型进行训练,包括其所有的部分和设置。但是这可能需要大量的计算资源和时间,特别是对于大型模型来说。
参数高效微调(Parameter-efficient fine-tuning),另一方面,是一种仅关注预训练模型部分设置的微调方式。在训练过程中,它会找出对于新任务最重要的参数,并仅对其进行修改。这使得参数高效微调更快,因为它不需要处理模型的所有参数。
实施堆栈
- Runpod:RunPod[2] 是一个云计算平台,主要用于人工智能和机器学习应用,提供GPU实例、无服务器GPU和AI终端。我们使用了1个NVIDIA 80GB GPU。
- Axolotl:用于简化各种人工智能模型微调的工具。
- Dataset:teknium/GPT4-LLM-Cleaned[3]
- LLM:openlm-research/open_llama_3b_v2 模型[4]
微调实现
安装所需依赖
!git clone https://github.com/OpenAccess-AI-Collective/axolotl.git
切换到axolotl文件夹
%cd axolotl ####### RESPONSE ###############
/workspace/axolotl
/usr/local/lib/python3.10/dist-packages/IPython/core/magics/osm.py:417: UserWarning: using dhist requires you to install the `pickleshare` library. self.shell.db['dhist'] = compress_dhist(dhist)[-100:]
!pip install packaging
!pip install -e .'[flash-attn,deepspedd]'
安装完依赖项后,请查看示例文件夹。其中包含几个带有相应lora配置文件的LLM模型。在这里,我们使用openllama 3b作为基础LLM。我们将查看它的配置文件 ./axolot/examples[5]/openllama-3b[6]/lora.yml。lora.yaml文件包含了微调基础模型所需的配置。
什么是LoRA?
它是一种旨在加速LLM(Language Learning Model)训练过程的训练方法。•它通过引入一对秩分解权重矩阵来帮助减少内存消耗。它将LLM的权重矩阵分解为低秩矩阵。这减少了需要训练的参数数量,同时仍保持原始模型的性能。•这些权重矩阵被添加到已存在的权重矩阵(预训练的)中。
与LoRA相关的重要概念
- 预训练权重的保留:LoRA保留了冻结层的先前训练权重。这有助于防止灾难性遗忘现象的发生。LoRA不仅保留了模型的现有知识,还能很好地适应新数据。
- 训练权重的可移植性:LoRA中使用的排名分解矩阵具有显著较少的参数。这使得训练后的LoRA权重可以在其他环境中被利用和转移。
- 与注意力层的整合:LoRA权重矩阵基本上被整合到原始模型的注意力层中。这允许对模型调整到新数据的上下文进行控制。
- 内存效率高,因为它将微调过程的计算减少了3倍。
- lora.yaml文件中的配置。我们可以通过在lora.yaml文件中的base_model和datasets参数指定相应的值来设置基础模型和训练数据集。
base_model: openlm-research/open_llama_3b_v2model_type: LlamaForCausalLMtokenizer_type: LlamaTokenizerload_in_8bit: trueload_in_4bit: falsestrict: falsepush_dataset_to_hub:datasets:- path: teknium/GPT4-LLM-Cleanedtype: alpacadataset_prepared_path:val_set_size: 0.02adapter: loralora_model_dir:sequence_len: 1024sample_packing: truelora_r: 8lora_alpha: 16lora_dropout: 0.0lora_target_modules:- gate_proj- down_proj- up_proj- q_proj- v_proj- k_proj- o_projlora_fan_in_fan_out:wandb_project:wandb_entity:wandb_watch:wandb_name:wandb_log_model:output_dir: ./lora-outgradient_accumulation_steps: 1micro_batch_size: 2num_epochs: 4optimizer: adamw_bnb_8bittorchdistx_path:lr_scheduler: cosinelearning_rate: 0.0002train_on_inputs: falsegroup_by_length: falsebf16: falsefp16: truetf32: falsegradient_checkpointing: trueearly_stopping_patience:resume_from_checkpoint:local_rank:logging_steps: 1xformers_attention:flash_attention: truegptq_groupsize:gptq_model_v1:warmup_steps: 20evals_per_epoch: 4saves_per_epoch: 1debug:deepspeed:weight_decay: 0.1fsdp:fsdp_config:special_tokens:bos_token: "<s>"eos_token: "</s>"unk_token: "<unk>"
Lora超参数
-
lora_r: 它决定了在权重矩阵上应用多少个等级分解矩阵,以减少内存消耗和计算需求。根据LoRA论文,默认或最小等级值为8。
-
更高的等级会导致更好的结果,但需要更高的计算能力。
-
随着训练数据复杂性的增加,需要更高的等级。
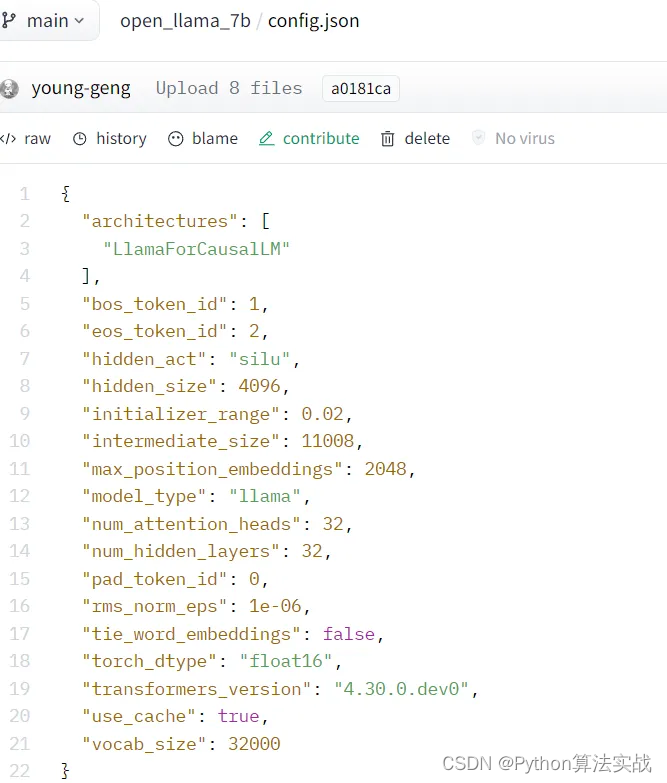
-
要与完整的微调匹配,权重矩阵的等级应与基础模型的隐藏层数量相匹配。可以从config.json中找到模型的隐藏大小(“num_hidden_layers”:32)。
lora_alpha: LoRA的缩放因子决定了模型在训练过程中调整矩阵更新的贡献程度。
- 较低的alpha值更重视原始数据,并更大程度上保持模型的现有知识,即更倾向于模型的原始知识。
lora_target_modules:它确定要训练的特定权重和矩阵。最基本的是q_proj(查询向量)和v_proj(值向量)。
- Q投影矩阵应用于transformers块中注意机制中的查询向量。它将隐藏状态转换为所需的维度,以实现有效的查询展示。•V投影矩阵将隐藏状态转换为所需的维度,以实现有效的值表示。
Lora Fine-tune
! accelerate launch -m axolotl.cli.train examples/openllama-3b/lora.yml
The following values were not passed to `accelerate launch` and had defaults used instead: `--num_processes` was set to a value of `1` `--num_machines` was set to a value of `1` `--mixed_precision` was set to a value of `'no'` `--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations warnings.warn(
[2024-01-01 08:31:18,370] [INFO] [datasets.<module>:58] [PID:2201] PyTorch version 2.0.1+cu118 available.
[2024-01-01 08:31:19,417] [INFO] [axolotl.validate_config:156] [PID:2201] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 08:31:19,417] [WARNING] [axolotl.validate_config:176] [PID:2201] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
config.json: 100%|█████████████████████████████| 506/506 [00:00<00:00, 2.10MB/s]
[2024-01-01 08:31:19,656] [INFO] [axolotl.normalize_config:150] [PID:2201] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc) dP dP dP 88 88 88 .d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88 88' `88 `8bd8' 88' `88 88 88' `88 88 88 88. .88 .d88b. 88. .88 88 88. .88 88 88 `88888P8 dP' `dP `88888P' dP `88888P' dP dP [2024-01-01 08:31:19,660] [WARNING] [axolotl.scripts.check_user_token:342] [PID:2201] [RANK:0] Error verifying HuggingFace token. Remember to log in using `huggingface-cli login` and get your access token from https://huggingface.co/settings/tokens if you want to use gated models or datasets.
tokenizer_config.json: 100%|███████████████████| 593/593 [00:00<00:00, 2.69MB/s]
tokenizer.model: 100%|███████████████████████| 512k/512k [00:00<00:00, 36.7MB/s]
special_tokens_map.json: 100%|█████████████████| 330/330 [00:00<00:00, 1.01MB/s]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:31:20,716] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>~~[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 08:31:20,717] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:147] [PID:2201] [RANK:0] Unable to find prepared dataset in last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:148] [PID:2201] [RANK:0] Loading raw datasets...
[2024-01-01 08:31:20,717] [INFO] [axolotl.load_tokenized_prepared_datasets:153] [PID:2201] [RANK:0] No seed provided, using default seed of 42
Downloading readme: 100%|███████████████████████| 501/501 [00:00<00:00, 343kB/s]
/usr/local/lib/python3.10/dist-packages/huggingface_hub/repocard.py:105: UserWarning: Repo card metadata block was not found. Setting CardData to empty. warnings.warn("Repo card metadata block was not found. Setting CardData to empty.")
Downloading data: 100%|████████████████████| 36.0M/36.0M [00:01<00:00, 27.0MB/s]
Downloading data: 100%|████████████████████| 4.91M/4.91M [00:00<00:00, 9.16MB/s]
Generating train split: 54568 examples [00:00, 187030.30 examples/s]
Map (num_proc=64): 13%|█▍ | 7057/54568 [00:11<03:55, 202.13 examples/s][2024-01-01 08:31:39,365] [WARNING] [axolotl._tokenize:66] [PID:2275] [RANK:0] Empty text requested for tokenization.
Map (num_proc=64): 100%|█████████| 54568/54568 [00:17<00:00, 3180.11 examples/s]
[2024-01-01 08:31:45,017] [INFO] [axolotl.load_tokenized_prepared_datasets:362] [PID:2201] [RANK:0] merging datasets
[2024-01-01 08:31:45,023] [INFO] [axolotl.load_tokenized_prepared_datasets:369] [PID:2201] [RANK:0] Saving merged prepared dataset to disk... last_run_prepared/f9e5091071bf5ab6f7287bd5565a5f24
Saving the dataset (1/1 shards): 100%|█| 54568/54568 [00:00<00:00, 524866.32 exa
Filter (num_proc=64): 100%|█████| 53476/53476 [00:02<00:00, 20761.86 examples/s]
Filter (num_proc=64): 100%|████████| 1092/1092 [00:00<00:00, 2586.61 examples/s]
Map (num_proc=64): 100%|████████| 53476/53476 [00:02<00:00, 19739.44 examples/s]
Map (num_proc=64): 100%|███████████| 1092/1092 [00:00<00:00, 2167.35 examples/s]
[2024-01-01 08:31:54,825] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 188373
[2024-01-01 08:31:54,833] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 38104`
[2024-01-01 08:32:01,085] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 188373
[2024-01-01 08:32:01,085] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 181
[2024-01-01 08:32:01,085] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.9017549402573529]
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: None
[2024-01-01 08:32:01,086] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 181
[2024-01-01 08:32:01,132] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_tokens: 10733491
[2024-01-01 08:32:01,495] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] `total_supervised_tokens: 6735490`
[2024-01-01 08:32:01,663] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 1.0 total_num_tokens per device: 10733491
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] data_loader_len: 10376
[2024-01-01 08:32:01,664] [INFO] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est across ranks: [0.8623549818747429]
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] sample_packing_eff_est: 0.87
[2024-01-01 08:32:01,664] [DEBUG] [axolotl.log:60] [PID:2201] [RANK:0] total_num_steps: 10376
[2024-01-01 08:32:01,671] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:185] [PID:2201] [RANK:0] EOS: 2 / </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:186] [PID:2201] [RANK:0] BOS: 1 / <s>~~[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:187] [PID:2201] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 08:32:01,945] [DEBUG] [axolotl.load_tokenizer:188] [PID:2201] [RANK:0] UNK: 0 / <unk>
[2024-01-01 08:32:01,946] [INFO] [axolotl.load_tokenizer:193] [PID:2201] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 08:32:01,946] [DEBUG] [axolotl.train.log:60] [PID:2201] [RANK:0] loading model and peft_config...
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:239] [PID:2201] [RANK:0] patching with flash attention for sample packing
[2024-01-01 08:32:02,058] [INFO] [axolotl.load_model:285] [PID:2201] [RANK:0] patching _expand_mask
pytorch_model.bin: 100%|████████████████████| 6.85G/6.85G [01:01<00:00, 111MB/s]
generation_config.json: 100%|███████████████████| 137/137 [00:00<00:00, 592kB/s]
[2024-01-01 08:33:13,199] [INFO] [axolotl.load_model:517] [PID:2201] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.952GB misc)
[2024-01-01 08:33:13,204] [INFO] [axolotl.load_model:540] [PID:2201] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 08:33:13,208] [INFO] [axolotl.load_model:552] [PID:2201] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:2201] CUDA extension not installed.
[2024-01-01 08:33:13,238] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:2201] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 08:33:13,490] [INFO] [axolotl.load_model:582] [PID:2201] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.099GB cache, +1.952GB misc)
[2024-01-01 08:33:13,526] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Pre-saving adapter config to ./lora-out
[2024-01-01 08:33:13,529] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Starting trainer...
[2024-01-01 08:33:13,935] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
[2024-01-01 08:33:13,982] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491 0%| | 0/1490 [00:00<?, ?it/s][2024-01-01 08:33:14,084] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 10733491
{'loss': 1.3828, 'learning_rate': 1e-05, 'epoch': 0.0} 0%| | 1/1490 [00:05<2:05:44, 5.07s/it][2024-01-01 08:33:19,125] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,322] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,323] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 0%| | 0/208 [00:00<?, ?it/s][2024-01-01 08:33:19,510] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 1%|▍ | 2/208 [00:00<00:19, 10.70it/s][2024-01-01 08:33:19,697] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:33:19,878] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 2%|▊ | 4/208 [00:00<00:29, 6.83it/s][2024-01-01 08:33:20,056] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.76it/s][2024-01-01 08:33:54,274] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.76it/s][2024-01-01 08:33:54,436] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 {'eval_loss': 1.7242642641067505, 'eval_runtime': 35.3126, 'eval_samples_per_second': 30.924, 'eval_steps_per_second': 30.924, 'epoch': 0.0} 0%| | 1/1490 [00:40<2:05:44, 5.07s/it] 99%|████████████████████████████████████████▍| 205/208 [00:35<00:00, 5.87it/s] [2024-01-01 08:33:58,624] [INFO] [axolotl.callbacks.on_step_end:124] [PID:2201] [RANK:0] GPU memory usage while training: 3.502GB (+1.607GB cache, +2.321GB misc)
{'loss': 1.4792, 'learning_rate': 2e-05, 'epoch': 0.0}
{'loss': 1.3653, 'learning_rate': 3e-05, 'epoch': 0.0}
{'loss': 1.3331, 'learning_rate': 4e-05, 'epoch': 0.0}
......
{'loss': 1.1553, 'learning_rate': 0.00017301379386534054, 'epoch': 0.25}
{'loss': 1.0537, 'learning_rate': 0.0001728675966533755, 'epoch': 0.25} 25%|█████████▌ | 373/1490 [26:25<1:17:08, 4.14s/it][2024-01-01 08:59:39,715] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:39,894] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:39,894] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 0%| | 0/208 [00:00<?, ?it/s][2024-01-01 08:59:40,062] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 1%|▍ | 2/208 [00:00<00:17, 11.94it/s][2024-01-01 08:59:40,232] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 08:59:40,400] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 2%|▊ | 4/208 [00:00<00:27, 7.47it/s][2024-01-01 08:59:40,568] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.82it/s][2024-01-01 09:00:14,117] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.75it/s][2024-01-01 09:00:14,286] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 {'eval_loss': 1.0763916969299316, 'eval_runtime': 34.5726, 'eval_samples_per_second': 31.586, 'eval_steps_per_second': 31.586, 'epoch': 0.25} 25%|█████████▌ | 373/1490 [27:00<1:17:08, 4.14s/it] 99%|████████████████████████████████████████▍| 205/208 [00:34<00:00, 5.81it/s]
{'loss': 1.2005, 'learning_rate': 0.00017272106662911973, 'epoch': 0.25}
{'loss': 1.1717, 'learning_rate': 0.0001725742044618282, 'epoch': 0.25}
......
{'loss': 1.0863, 'learning_rate': 0.00010235063511836416, 'epoch': 0.5}
{'loss': 1.0656, 'learning_rate': 0.00010213697517873015, 'epoch': 0.5}
{'loss': 1.1216, 'learning_rate': 0.00010192330547876871, 'epoch': 0.5} 50%|████████████████████ | 746/1490 [52:57<51:59, 4.19s/it][2024-01-01 09:26:11,256] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,436] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,437] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 0%| | 0/208 [00:00<?, ?it/s][2024-01-01 09:26:11,607] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 1%|▍ | 2/208 [00:00<00:17, 11.79it/s][2024-01-01 09:26:11,779] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:26:11,947] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 ......
98%|████████████████████████████████████████ | 203/208 [00:34<00:00, 5.92it/s][2024-01-01 09:26:45,864] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.89it/s][2024-01-01 09:26:46,027] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 {'eval_loss': 1.0423786640167236, 'eval_runtime': 34.7727, 'eval_samples_per_second': 31.404, 'eval_steps_per_second': 31.404, 'epoch': 0.5} 50%|████████████████████ | 746/1490 [53:31<51:59, 4.19s/it] 99%|████████████████████████████████████████▍| 205/208 [00:34<00:00, 5.95it/s]
{'loss': 1.1375, 'learning_rate': 0.00010170962699438553, 'epoch': 0.5}
{'loss': 1.0644, 'learning_rate': 0.00010149594070152638, 'epoch': 0.5}
......
{'loss': 1.1636, 'learning_rate': 2.9972614456474536e-05, 'epoch': 0.75}
{'loss': 1.0501, 'learning_rate': 2.9820209711600854e-05, 'epoch': 0.75} 75%|███████████████████████████▊ | 1119/1490 [1:19:31<25:59, 4.20s/it][2024-01-01 09:52:45,791] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:45,977] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:45,978] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 0%| | 0/208 [00:00<?, ?it/s][2024-01-01 09:52:46,154] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 1%|▍ | 2/208 [00:00<00:18, 11.37it/s][2024-01-01 09:52:46,333] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
[2024-01-01 09:52:46,505] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 2%|▊ | 4/208 [00:00<00:28, 7.18it/s][2024-01-01 09:52:46,679] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373
......
98%|████████████████████████████████████████▏| 204/208 [00:34<00:00, 5.82it/s][2024-01-01 09:53:21,107] [INFO] [axolotl.utils.samplers.multipack._len_est:178] [PID:2201] [RANK:0] packing_efficiency_estimate: 0.87 total_num_tokens per device: 188373 {'eval_loss': 1.023378849029541, 'eval_runtime': 35.318, 'eval_samples_per_second': 30.919, 'eval_steps_per_second': 30.919, 'epoch': 0.75} 75%|███████████████████████████▊ | 1119/1490 [1:20:07<25:59, 4.20s/it] 99%|████████████████████████████████████████▍| 205/208 [00:35<00:00, 5.88it/s]
{'loss': 1.0606, 'learning_rate': 2.966812550284803e-05, 'epoch': 0.75}
{'loss': 0.9497, 'learning_rate': 2.9516362524838846e-05, 'epoch': 0.75}
......
{'loss': 1.0027, 'learning_rate': 9.134702554591811e-10, 'epoch': 1.0}
{'loss': 0.9021, 'learning_rate': 2.283678246284282e-10, 'epoch': 1.0}
{'loss': 1.1726, 'learning_rate': 0.0, 'epoch': 1.0}
{'train_runtime': 6355.7444, 'train_samples_per_second': 8.414, 'train_steps_per_second': 0.234, 'train_loss': 1.0881121746245646, 'epoch': 1.0}
100%|█████████████████████████████████████| 1490/1490 [1:45:55<00:00, 4.27s/it]
[2024-01-01 10:19:09,776] [INFO] [axolotl.train.log:60] [PID:2201] [RANK:0] Training Completed!!! Saving pre-trained model to ./lora-out
•训练在Nividia A 100 80 GB GPU上花费了1小时45分钟•训练检查点会保存在lora.yaml文件中指定的lora-out文件夹中,这是输出目录。•适配器文件也会保存在lora.yaml文件中指定的输出目录中。•可以通过在lora.yaml文件中的push_dataset_to_hub参数中指定repoid和文件夹详细信息来将训练好的模型推送到huggingface存储库。
使用gradio进行交互式推理
gradio
!accelerate launch -m axolotl.cli.inference examples/openllama-3b/lora.yml --lora_model_dir="./lora-out" --gradio
The following values were not passed to `accelerate launch` and had defaults used instead: `--num_processes` was set to a value of `1` `--num_machines` was set to a value of `1` `--mixed_precision` was set to a value of `'no'` `--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
/usr/local/lib/python3.10/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations warnings.warn(
[2024-01-01 10:43:34,869] [INFO] [datasets.<module>:58] [PID:5297] PyTorch version 2.0.1+cu118 available. dP dP dP 88 88 88 .d8888b. dP. .dP .d8888b. 88 .d8888b. d8888P 88 88' `88 `8bd8' 88' `88 88 88' `88 88 88 88. .88 .d88b. 88. .88 88 88. .88 88 88 `88888P8 dP' `dP `88888P' dP `88888P' dP dP [2024-01-01 10:43:35,772] [INFO] [axolotl.validate_config:156] [PID:5297] [RANK:0] bf16 support detected, but not enabled for this configuration.
[2024-01-01 10:43:35,772] [WARNING] [axolotl.validate_config:176] [PID:5297] [RANK:0] `pad_to_sequence_len: true` is recommended when using sample_packing
[2024-01-01 10:43:36,062] [INFO] [axolotl.normalize_config:150] [PID:5297] [RANK:0] GPU memory usage baseline: 0.000GB (+0.811GB misc)
[2024-01-01 10:43:36,064] [INFO] [axolotl.common.cli.load_model_and_tokenizer:49] [PID:5297] [RANK:0] loading tokenizer... openlm-research/open_llama_3b_v2
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:185] [PID:5297] [RANK:0] EOS: 2 / </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:186] [PID:5297] [RANK:0] BOS: 1 / <s>~~[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:187] [PID:5297] [RANK:0] PAD: 2 /~~ </s>
[2024-01-01 10:43:36,345] [DEBUG] [axolotl.load_tokenizer:188] [PID:5297] [RANK:0] UNK: 0 / <unk>
[2024-01-01 10:43:36,345] [INFO] [axolotl.load_tokenizer:193] [PID:5297] [RANK:0] No Chat template selected. Consider adding a chat template for easier inference.
[2024-01-01 10:43:36,345] [INFO] [axolotl.common.cli.load_model_and_tokenizer:51] [PID:5297] [RANK:0] loading model and (optionally) peft_config...
[2024-01-01 10:43:44,496] [INFO] [axolotl.load_model:517] [PID:5297] [RANK:0] GPU memory usage after model load: 3.408GB (+0.334GB cache, +1.850GB misc)
[2024-01-01 10:43:44,501] [INFO] [axolotl.load_model:540] [PID:5297] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-01-01 10:43:44,505] [INFO] [axolotl.load_model:552] [PID:5297] [RANK:0] converting modules to torch.float16 for flash attention
[2024-01-01 10:43:44,506] [DEBUG] [axolotl.load_lora:670] [PID:5297] [RANK:0] Loading pretained PEFT - LoRA
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda.<module>:16] [PID:5297] CUDA extension not installed.
[2024-01-01 10:43:44,533] [WARNING] [auto_gptq.nn_modules.qlinear.qlinear_cuda_old.<module>:15] [PID:5297] CUDA extension not installed.
trainable params: 12,712,960 || all params: 3,439,186,560 || trainable%: 0.36965020007521776
[2024-01-01 10:43:44,851] [INFO] [axolotl.load_model:582] [PID:5297] [RANK:0] GPU memory usage after adapters: 3.455GB (+1.148GB cache, +1.850GB misc)
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://87eb53a4929499e106.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
结论
在这里,我们探讨了如何利用Axolotl,并使用gradio对经过微调的模型进行几乎没有代码微调和推理。
本文整理自:https://medium.aiplanet.com/no-code-llm-fine-tuning-using-axolotl-2db34e3d0647
https://github.com/OpenAccess-AI-Collective/axolotl
核心目的是向大家分享更多AI相关的知识,让更多的人能够对AI有一个清晰的认识。
如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
References
[1] Axolotl: https://github.com/OpenAccess-AI-Collective/axolotl
[2] RunPod: https://www.runpod.io/console/gpu-cloud
[3] teknium/GPT4-LLM-Cleaned: https://huggingface.co/datasets/teknium/GPT4-LLM-Cleaned
[4] openlm-research/open_llama_3b_v2 模型: https://huggingface.co/openlm-research/open_llama_3b_v2
[5] examples: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples
[6] openllama-3b: https://github.com/OpenAccess-AI-Collective/axolotl/tree/main/examples/openllama-3b
这篇关于Axolotl:一款极简的大模型微调(Finetune)开源框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







