dfa专题


DFA算法 敏感词过滤方案汇总以及高效工具sensitive-word
敏感词过滤方案汇总以及高效工具sensitive-word 导入pom文件 <dependency><groupId>com.github.houbb</groupId><artifactId>sensitive-word</artifactId><version>0.12.0</version></dependency> 接下来我们编写相关测试类,来测试对应方法 final Strin

【p10】DFA (NFA确定化) 以及DFA的最小化
终于到这里了 可能是最难的部分?反正是网课时长最长的部分 需要画表,所以最好还是跟着网课一边学一边操作,不然没啥印象,上完网课之后没啥效果 文章目录 画表通过终结符给新的集合编号新建表格结束根据表格画图DFA初态集和终态集某种操作覆盖操作 画表 表头是I,然后是有多少个终结符,再加多少个表头 I代表的是状态集合 从 I 0 I_0 I0 开始填, I I I 表示的

3.2-3.3 词法分析---NFA转换到DFA~DFA 最小化 Hopcroft 算法
子集构造算法: 因为NFA不适合直接用来做词法分析器的识别,是因为它的状态转移是不确定的,这种情况下写一个算法往往需要回溯,对于分析的效率影响会比较大,所以需要用子集构造算法由NFA将它转换成与它等价的DFA(因为DFA是确定有限状态自动机),最终转换成词法分析器可以使用的代码。 子集构造算法思想: a(b|c)* 下图是一个NFA,很明显它的转移边包含 ε 所以它的状态转移是不确定的,我们所要
【黑马头条】-day04自媒体文章审核-阿里云接口-敏感词分析DFA-图像识别OCR-异步调用MQ
文章目录 day4学习内容自媒体文章自动审核今日内容 1 自媒体文章自动审核1.1 审核流程1.2 内容安全第三方接口1.3 引入阿里云内容安全接口1.3.1 添加依赖1.3.2 导入aliyun模块1.3.3 注入Bean测试 2 app端文章保存接口2.1 表结构说明2.2 分布式id2.2.1 分布式id-技术选型2.2.2 雪花算法2.2.3 配置雪花算法 2.3 保存app端

2.14 构造一个DFA,它接受Σ = {0,1}上能被5整除的二进制数。
陈介平 PB14209115 编译原理作业题,题目如上,另老师还要求写出能被5整除的二进制串的正规式。 解析: 首先分析题目可知,一个数除以5,其余数(十进制)只能是0,1,2,3,4五种,因此我们以0,1,2,3,4分别表示这五种状态。因为要求得能被5整除的数,0 mod 5=0满足要求,故状态0既为初始状态,又为终结状态。 接着,考虑二进制数在其串后增添0或1时,状态的转化情况。在二进
软考进行时——DFA和NFA
1.历史: 引用 正则表达式萌芽于1940年代的神经生理学研究,由著名数学家Stephen Kleene第一个正式描述。具体地说,Kleene归纳了前述的神经生理学研究,在一篇题为《正则集代数》的论文中定义了“正则集”,并在其上定义了一个代数系统,并且引入了一种记号系统来描述正则集,这种记号系统被他称为“正则表达式”。在理论数学的圈子里被研究了几十年之后,1968年,后来发明了UNI

正规文法、正规式、确定的有穷自动机DFA、不确定的有穷自动机NFA 的概念、区分以及等价性转换【我直接拿下!】
文章目录 正规文法正规式有穷自动机确定的有穷自动机——DFA不确定的有穷自动机——NFADFA 与 NFA 的区分 正规式转换为正规文法正规文法转换为正规式NFA 转换为 DFANFA 最小化 NFA 转换为正规式正规式转换为 NFA正规文法转换为 NFANFA 转换为正规文法 前言: 在学习正规文法之前,需要先了解一下什么是文法,具体可以查看这篇文章,总结的比较好 —— 编

力扣面试150 只出现一次的数字Ⅱ 哈希 统计数位 DFA有穷自动机
Problem: 137. 只出现一次的数字 II 文章目录 思路💖 哈希💖 位数统计💖 DFA 状态机 思路 👨🏫 参考 💖 哈希 ⏰ 时间复杂度: O ( n ) O(n) O(n) 🌎 空间复杂度: O ( n ) O(n) O(n) class Solution {public int singleNumber(int[] nums)

OpenSource - 基于 DFA 算法实现的高性能 java 敏感词过滤工具框架
文章目录 sensitive-word创作目的特性变更日志更多资料敏感词控台敏感词标签文件 快速开始准备Maven 引入核心方法判断是否包含敏感词返回第一个敏感词返回所有敏感词默认的替换策略指定替换的内容自定义替换策略 IWordResultHandler 结果处理类使用实例 更多特性样式处理忽略大小写忽略半角圆角忽略数字的写法忽略繁简体忽略英文的书写格式忽略重复词 更多检测策略邮箱检测
DFA算法实现铭感词过滤(二)
前言 这里的项目实战, 我们使用的是 SpringBoot2.x+JDK1.8搭建的,核心思想是借助了Hutool工具类的 WordTree。想了解更多DFA算法的实现可以参考DFA算法的实现 实战案例 1. 引入Hutool的工具类 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><ve

DFA 算法实现敏感词过滤
背景 项目中APP端发帖,评论可能包含多个关键词,铭感词。此时需要对该内容进行过滤处理。此前都是在客户端层面操作,这样不仅带来了性能的损耗,而且新增铭感词时,需要客户端重新打包上架,显得十分不合理。所以应该在服务端层面进行算法数据处理。 DFA 算法 DFA 全称为: Deterministic Finite Automaton, 即确定有穷自动机。其特征为:有一个有效状态的集合和一些从一个
Hutool--DFA 敏感词工具类
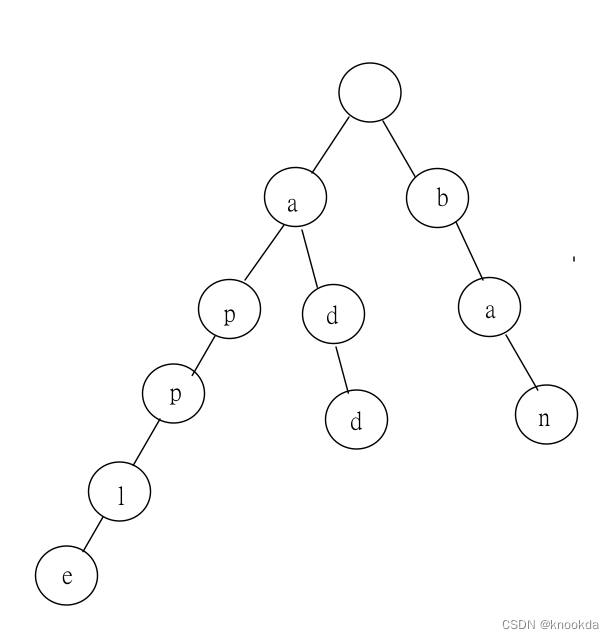
使用hutool的dfa工具类可以很好的帮助我们来实现敏感词过滤的功能,下面从用例入手来逐步地去j简单了解一下dfa工具类。 字典树 DFA算法的核心是建立了以敏感词为基础的许多敏感词树(字典树)。 它的基本思想是基于状态转移来检索敏感词。 字典树,是一种树形结构树形结构,主要用于统计,排序和保存大量的字符串。 主要思想:利用字符串的公共前缀来节约存储空间,很好地利用了串的公共前缀,节约了
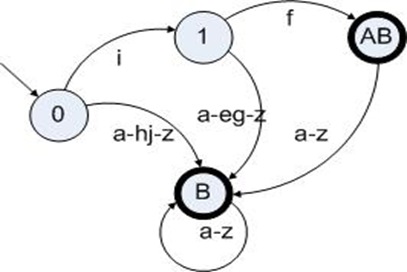
正则表达式DFA构造方法
陈梓瀚 vczh@163.com http://www.cppblog.com/vczh/ 1、问题概述 随着计算机语言的结构越来越复杂,为了开发优秀的编译器,人们已经渐渐感到将词法分析独立出来做研究的重要性。不过词法分析器的作用却不限于此。回想一下我们的老师刚刚开始向我们讲述程序设计的时候,总是会出一道题目:给出一个填入了四则运算式子的字符串,写程序计算该式子的结果。除此之外,我们有时候

LC8. 字符串转换整数 (atoi):DFA有限状态机
文章目录 题DFA 题 DFA class Automaton {string state = "start";unordered_map<string, vector<string>> table = {{"start", {"start", "signed", "in_number", "end"}},{"signed", {"end", "end", "i
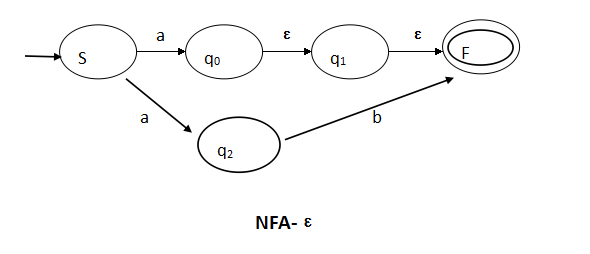
有限自动机NFA-ε到NFA再到DFA的转换
DFA(Deterministic Finite Automata),即确定的有限自动机,指的是对于每个状态得到确定的输入的字母表后都能得到唯一的下一个状态,而NFA(Nondeterminisic Finite Automata)则是不确定的有限自动机,指的是对于任何一个状态,当该状态获得输入的字母表后,有可能得到的状态不是一个,而是多个,即是一个状态的集合。从某种意义上来说,D
正规文法、正规式、确定的有穷自动机DFA、不确定的有穷自动机NFA 的概念、区分以及等价性转换【我直接拿下!】
文章目录 正规文法正规式有穷自动机确定的有穷自动机——DFA不确定的有穷自动机——NFADFA 与 NFA 的区分 正规式转换为正规文法正规文法转换为正规式NFA 转换为 DFANFA 最小化 NFA 转换为正规式正规式转换为 NFA正规文法转换为 NFANFA 转换为正规文法 前言: 在学习正规文法之前,需要先了解一下什么是文法,具体可以查看这篇文章,总结的比较好 —— 编
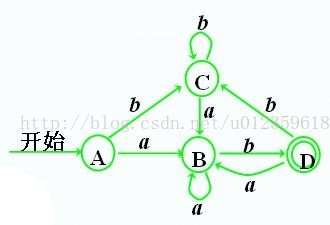
NFA转换位DFA 例子
NFA转换位DFA 1、求出初态 Q0 ε-closure(0)={0,1,2,4,7} ------------A ε-closure(A,a)= { 3 6 7 1 2 4 8 } = {1 2 3 4 6 7 8 } ---------------------B ε-closure(A,b)={ 5 6 7 1 2 4 } =
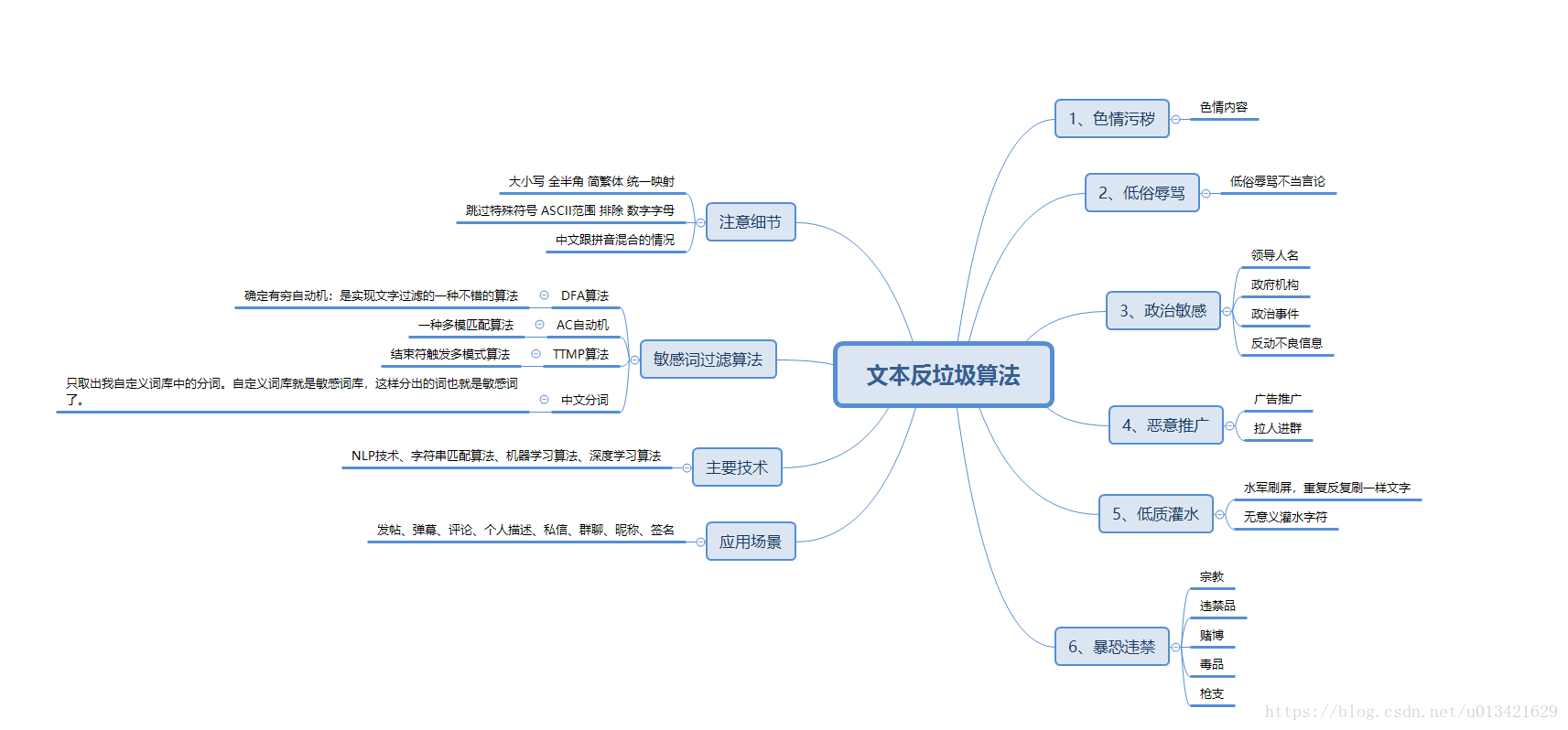
【python 走进NLP】两种高效过滤敏感词算法--DFA算法和AC自动机算法
一道bat面试题:快速替换10亿条标题中的5万个敏感词,有哪些解决思路? 有十亿个标题,存在一个文件中,一行一个标题。有5万个敏感词,存在另一个文件。写一个程序过滤掉所有标题中的所有敏感词,保存到另一个文件中。 1、DFA过滤敏感词算法 在实现文字过滤的算法中,DFA是比较好的实现算法。DFA即Deterministic Finite Automaton,也就是确定有穷自动机。 算法核心是

基于确定有穷自动机(DFA算法)实现敏感词过滤
该文章已同步收录到我的博客网站,欢迎浏览我的博客网站,xhang’s blog 1.DFA算法简介 DFA(Deterministic Finite Automaton) 是一种非递归自动机,也称为确定有穷自动机。它是通过event和当前的state得到nextstate,即event+state=nextstate。 确定:状态以及引起状态转换的事件都是可确定的。 有穷:状态以及引起状态

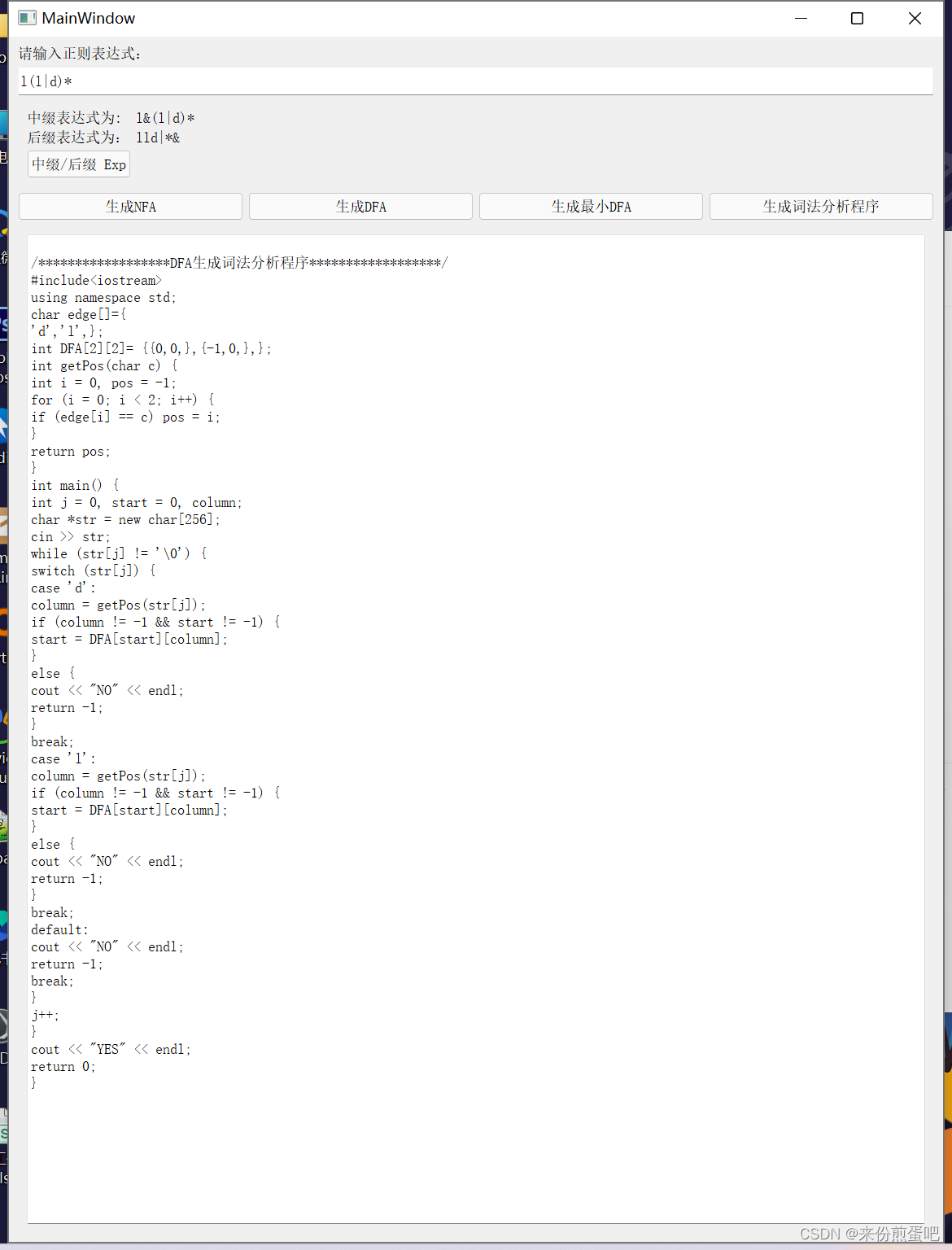
【编译原理】实验一——正则运算表达式的 DFA 构建
一、基本数据结构 1)字符集 public class CharSet {/*字符进行范围运算('a'~'z')、并运算(a|b)和差运算(-) 都返回一个新的字符集对象*//** 字符集id */private final int indexId;/** 字符集中的段 id。一个字符集可以包含多个段 */private final int segmentId;/** 段的起始字符 */priv
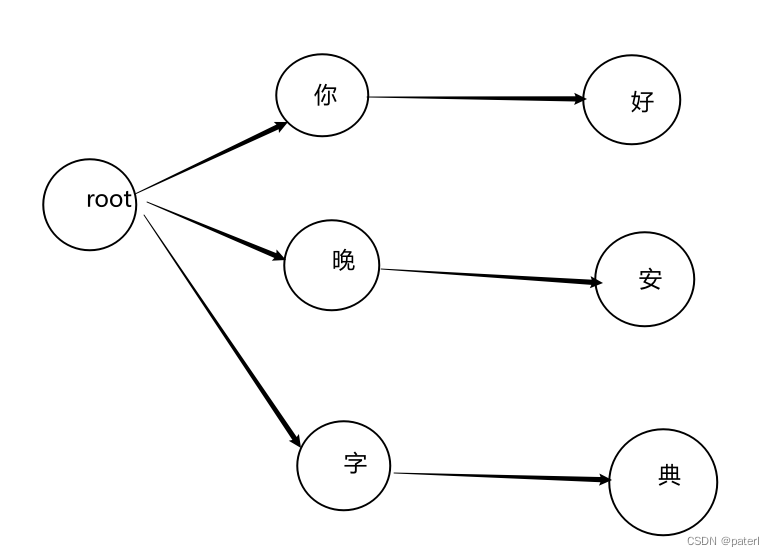
【Golang】DFA算法过滤敏感词Golang实现
什么是DFA算法 DFA全称:Deterministic Finite Automaton,翻译过来就是确定性有限自动机,其特征是,有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态,但是确定性有穷自动机不会从同一状态触发的两个边标志由相同的符号。 通俗的讲DFA算法就是把你要匹配的做成一颗字典树,然后对你输入的内容进行匹配的过程