本文主要是介绍基于确定有穷自动机(DFA算法)实现敏感词过滤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
该文章已同步收录到我的博客网站,欢迎浏览我的博客网站,xhang’s blog
1.DFA算法简介
DFA(Deterministic Finite Automaton) 是一种非递归自动机,也称为确定有穷自动机。它是通过event和当前的state得到nextstate,即event+state=nextstate。
确定:状态以及引起状态转换的事件都是可确定的。
有穷:状态以及引起状态转换的事件的数量都是可穷举的。
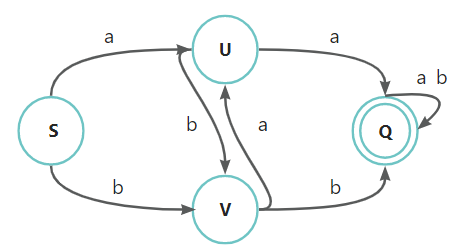
对于以下状态转换图:
(S,a) -> U
(S,b) -> V
(U,a) -> Q
(U,b) -> V
(V,a) -> U
(V,b) -> Q
(Q,a) -> Q
(Q,b) -> Q
我们可以将每个文本片段作为状态,例如“匹配关键词”可拆分为“匹”、“匹配”、“匹配关”、“匹配关键”和“匹配关键词”五个文本片段。

过程:
- 初始状态为空,当触发事件“匹”时转换到状态“匹”;
- 触发事件“配”,转换到状态“匹配”;
- 依次类推,直到转换为最后一个状态“匹配关键词”。
再让我们考虑多个关键词的情况,例如“匹配算法”、“匹配关键词”以及“信息抽取”。

可以看到上图的状态图类似树形结构,也正是因为这个结构,使得 DFA 算法在关键词匹配方面要快于关键词迭代方法(for 循环)。
2.Java对DFA算法的实现思路
在Java中实现敏感词过滤的关键就是DFA算法的实现。
我们可以认为,通过S query U、V,通过U query V、P,通过V query U P。通过这样的转变我们可以将状态的转换转变为使用Java集合的查找。
如果有以下词为敏感词:日本人、日本鬼子
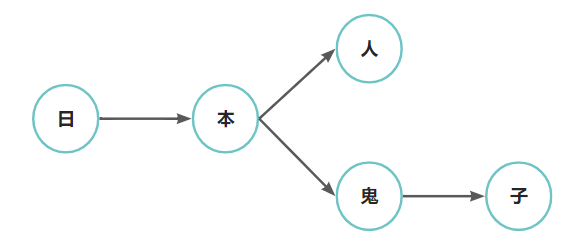
这样我们就将我们的敏感词库构建成了一个类似与一颗一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
但是如何来判断一个敏感词已经结束了呢?利用标识位来判断。
所以对于这个关键是如何来构建一棵棵这样的敏感词树。下面我以Java中的HashMap为例来实现DFA算法。以日本人,日本鬼子为例,具体过程如下:
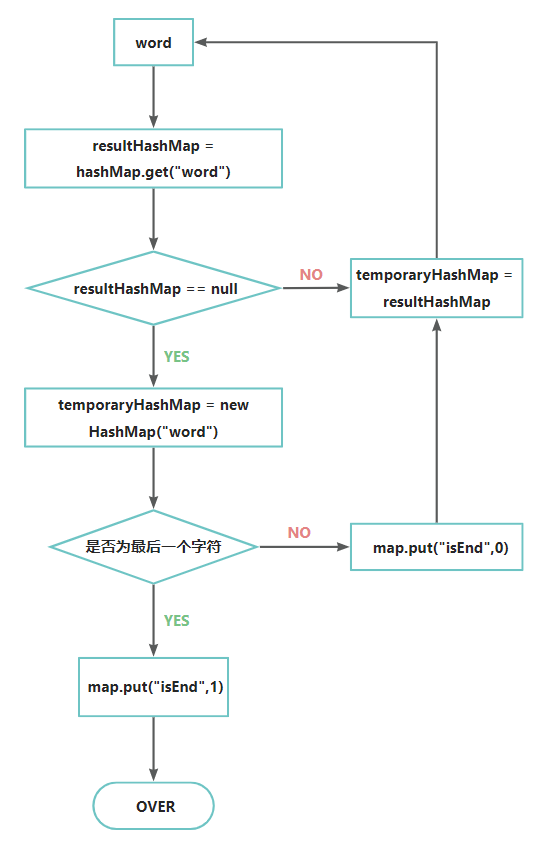
- 首先获取到根节点HashMap,判断“日”是否存在于根节点当中,如果不存在,则表示该敏感词还不存在。则以“日”为key,创建新的HashMap为value做为根节点。
- 如果存在,则表示已经存在含有以“日”开头的敏感词。设置hashMap = hashMap.get(“日”),接着依次匹配“本”、“人”。
- 判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isEnd = 1,否则设置标志位isEnd = 0;
3.Java对DFA算法的实现案例
假如以“日本人”和“日本鬼子”为敏感词,以下为实现过程

代码实现:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;public class DFAHashMap {public void createDFAHashMap(List<String> strings) {
// 1.创建dfaHashMap,此HashMap就表示一个树形结构。
// 指定容量为集合strings的长度,避免dfaHashMap在添加的数据的时候动态扩容HashMap<String, Object> dfaHashMap = new HashMap<>(strings.size());
// 2.创建temporaryHashMap,用于装载临时HashMap数据HashMap<String, Object> temporaryHashMap = new HashMap<>(strings.size());
// 3.遍历字符串for (String string : strings) {
// 3.1对于每个字符串,首个temporaryHashMap就是dfaHashMap,就是树型结构的根节点,
// 即temporaryHashMap首先指向根节点dfaHashMap的内存地址。temporaryHashMap = dfaHashMap;
// 4.遍历字符串中的每个字符for (int i = 0; i < string.length(); i++) {
// 5.查询在当前temporaryHashMap当中是否存在当前字符String word = String.valueOf(string.charAt(i));HashMap<String, Object> resultHashMap = (HashMap<String, Object>) temporaryHashMap.get(word);if (resultHashMap == null) {
// 6.如果当前dfaHashMap当中不存在当前字符,就以当前字符为key,新建HashMap作为ValueresultHashMap = new HashMap<String, Object>();
// 6.1由于temporaryHashMap指向的就是dfaHashMap的内存地址,所以dfaHashMap当中存储了该值temporaryHashMap.put(word, resultHashMap);}
// 7.将temporaryHashMap的地址指向下一个HashMaptemporaryHashMap = resultHashMap;
// 8.判断是否跳过本次循环
// 如果temporaryHashMap里面已经有isEnd,并且为1,说明时树形结构中已经存在的敏感词,就不再设置isEnd
// 如日本和日本鬼子,先设置日本
// 在日本鬼子设置的时候,本对应的map有isEnd=1,如果这时对它覆盖,就会isEnd=0,导致日本这个关键字失效if(temporaryHashMap.containsKey("isEnd")&&temporaryHashMap.get("isEnd").equals(1)){continue;}
// 8.封装temporaryHashMap
// 8.1判断当前字符是否为字符串的最后一个字符if (i == string.length() - 1) {temporaryHashMap.put("isEnd", 1);} else {temporaryHashMap.put("isEnd", 0);}}}System.out.println(dfaHashMap);}public static void main(String[] args) {List<String> strings = new ArrayList<>();strings.add("日本人");strings.add("日本鬼子");new DFAHashMap().createDFAHashMap(strings);}
}
结果如下:

{日={本={人={isEnd=1}, 鬼={子={isEnd=14}, isEnd=0}, isEnd=0}, isEnd=0}}
4.综合实战
4.1敏感词库初始化类
该类的作用主要是读取敏感词文件,并使用DFA算法初始化敏感词库。
public HashMap<String, Object> getSensitiveWordHashMap():
调用
readSensitiveWordFile()方法获取到敏感词集合,再调用initSensitiveHashMap()方法使用DFA算法初始化敏感词库。private Set readSensitiveWordFile()
读取敏感词文件,返回敏感词集合
private Map initSensitiveHashMap(Set strings):
将敏感词集合封装为
HashMap<String,Object>类型,初始化敏感词库。
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.io.ClassPathResource;import java.io.*;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;/*** 敏感词库初始化** @date 2023/06/02*/
@Slf4j
public class SensitiveWordInitialize {// 字符编码private String ENCODING = "UTF-8";/*** 敏感词库变量*/private HashMap<String, Object> sensitiveWordHashMap = null;/*** 获取到敏感词库** @return {@link HashMap}<{@link String}, {@link Object}>* @throws IOException ioexception*/public HashMap<String, Object> getSensitiveWordHashMap() throws IOException {log.info("敏感词库初始化");Set<String> strings = readSensitiveWordFile();System.out.println(strings.size());sensitiveWordHashMap = (HashMap<String, Object>) initSensitiveHashMap(strings);return sensitiveWordHashMap;}/*** 敏感词文件读取** @return {@link Set}<{@link String}>*/private Set<String> readSensitiveWordFile() {Set<String> wordSet = null;ClassPathResource classPathResource = new ClassPathResource("sensitive_words.txt");
// 1.获取文件字节流InputStream inputStream = null;InputStreamReader inputStreamReader = null;try {inputStream = classPathResource.getInputStream();
// 2.实现字节流和字符流之间的转换inputStreamReader = new InputStreamReader(inputStream, ENCODING);wordSet = new HashSet<>();
// 3.使用缓冲流进行读取BufferedReader bufferedReader = new BufferedReader(inputStreamReader);String txt = null;while ((txt = bufferedReader.readLine()) != null) {wordSet.add(txt);}} catch (IOException e) {throw new RuntimeException(e);} finally {if (inputStreamReader != null) {try {inputStreamReader.close();} catch (IOException e) {e.printStackTrace();}}if (inputStream != null) {try {inputStream.close();} catch (IOException e) {e.printStackTrace();}}}return wordSet;}/*** 基于DFA算法初始化敏感词库** @param strings 字符串*/private Map initSensitiveHashMap(Set<String> strings) {sensitiveWordHashMap = new HashMap<>(strings.size());
// 1.创建temporaryHashMap用于存储临时数据HashMap<String, Object> temporaryHashMap = new HashMap<>();
// 2.遍历敏感词列表for (String string : strings) {
// 3.对于temporaryHashMap,其初始值就是为根节点sensitiveWordHashMaptemporaryHashMap = sensitiveWordHashMap;
// 4.遍历每个字符for (int i = 0; i < string.length(); i++) {String word = String.valueOf(string.charAt(i));
// 4.1判断根据点是否存在该字符HashMap<String, Object> resultHashMap = (HashMap<String, Object>) temporaryHashMap.get(word);
// 4.2如果为空就创建节点if (resultHashMap == null) {resultHashMap = new HashMap<String, Object>();
// 4.3以当前字符为key,new HashMap为value创建节点temporaryHashMap.put(word, resultHashMap);}
// 5.temporaryHashMap指向下一个HashMaptemporaryHashMap = resultHashMap;
// 6.判断是否跳过本次循环
// 如果temporaryHashMap里面已经有isEnd,并且为1,说明时树形结构中已经存在的敏感词,就不再设置isEnd
// 如日本和日本鬼子,先设置日本
// 在日本鬼子设置的时候,本对应的map有isEnd=1,如果这时对它覆盖,就会isEnd=0,导致日本这个关键字失效if (temporaryHashMap.containsKey("isEnd") && temporaryHashMap.get("isEnd").equals(1)) {continue;}
// 7.封装temporaryHashMap
// 7.1判断当前字符是否为字符串的最后一个字符if (i == string.length() - 1) {temporaryHashMap.put("isEnd", 1);} else {temporaryHashMap.put("isEnd", 0);}}}return sensitiveWordHashMap;}
}
4.2敏感词工具类
该类的采用单例模式获取到敏感词库,并对字符串进行敏感词过滤替换。
public void init():
@PostConstruct注解表示该方法在对象实例化后执行,进行敏感词库初始化。public String replaceSensitiveWord(String string, int matchType):
替换字符串当中的敏感词。首先调用
getSensitiveWord()方法获取到当前字符串当中的敏感词集合,并遍历敏感词集合。调用getReplaceString方法根据敏感词长度生成对应的替代词。替换当前敏感词。private String getReplaceString(int length)
根据敏感词长度生成对应的替换字符串。
public Set getSensitiveWord(String string, int matchType):
获取到敏感词集合。在该方法中根据用户输入的字符串,调用
getStringLength()方法获取到敏感词在此字符串当中的索引位置。截取敏感词并添加到敏感词集合中返回。public int getStringLength(String string, int beginIndex, int matchType):
返回敏感词长度。在该方法中获取到敏感词库,根据敏感词库检查文字中是否包含敏感字符,如果存在,则返回敏感词字符的长度,不存在返回0。
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.io.IOException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;/*** 敏感词过滤工具类** @author Xu huaiang* @date 2023/06/02*/
@Component
public class SensitiveReplaceUtil {/*** 敏感词过滤器:利用DFA算法 进行敏感词过滤*/private static HashMap<String, Object> sensitiveWordHashMap = null;/*** 最小匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国]人*/public static int minMatchType = 1;/*** 最大匹配规则,如:敏感词库["中国","中国人"],语句:"我是中国人",匹配结果:我是[中国人]*/public static int maxMatchType = 2;/*** 敏感词替换词*/public static String replaceChar = "*";/*** 初始化敏感词库** @throws IOException ioexception*/@PostConstructpublic void init() throws IOException {sensitiveWordHashMap = new SensitiveWordInitialize().getSensitiveWordHashMap();}/*** 替换字符串当中的敏感词** @param string 字符串* @param matchType 匹配类型* @return {@link String}*/public String replaceSensitiveWord(String string, int matchType) {String resultString = string;
// 1.获取到当前字符串中的敏感词集合Set<String> sensitiveWord = getSensitiveWord(string, matchType);
// 2.迭代遍历敏感词集合for (String word : sensitiveWord) {
// 2.1获取到敏感词// 2.2根据敏感词长度创建替代字符串String replaceString = getReplaceString(word.length());
// 2.3替换字符串resultString = resultString.replaceAll(word, replaceString);}return resultString;}/*** 根据敏感词长度创建替代字符串** @param length 长度* @return {@link String}*/private String getReplaceString(int length) {StringBuilder replaceString = new StringBuilder();
// 根据敏感词长度创建替代字符串for (int i = 0; i < length; i++) {replaceString.append(replaceChar);}return replaceString.toString();}/*** 获取到字符串中的敏感词集合** @param string 字符串* @param matchType 匹配类型* @return {@link Set}<{@link String}>*/public Set<String> getSensitiveWord(String string, int matchType) {Set<String> set = new HashSet<>();
// 1.遍历字符串中的每一个字符for (int i = 0; i < string.length(); i++) {int length = getStringLength(string, i, matchType);
// 2.如果length大于0表示存在敏感词,将敏感词添加到集合中if (length > 0) {set.add(string.substring(i, i + length));}}return set;}/*** 检查文字中是否包含敏感字符,检查规则如下:* 如果存在,则返回敏感词字符的长度,不存在返回0** @param string 字符串* @param beginIndex 开始下标* @param matchType 匹配类型* @return int*/public int getStringLength(String string, int beginIndex, int matchType) {
// 1.当前敏感词长度,用作累加int nowLength = 0;
// 2.最终敏感词长度int resultLength = 0;
// 3.获取到敏感词库HashMap<String, Object> temporaryHashMap = sensitiveWordHashMap;
// 4.遍历字符串for (int i = beginIndex; i < string.length(); i++) {
// 5.判断当前字符是否为敏感词库中的首个字母String word = String.valueOf(string.charAt(i));temporaryHashMap = (HashMap<String, Object>) temporaryHashMap.get(word);
// 5.1如果为空表示当前字符并不为敏感词if (temporaryHashMap == null) {break;} else {nowLength++;
// 5.2判断是否为最后一个敏感词字符if (temporaryHashMap.get("isEnd").equals(1)) {resultLength = nowLength;
// 5.3判断匹配原则,如果为2表示最大匹配原则,继续匹配,为1结束匹配if (matchType == minMatchType) {break;}}}}return resultLength;}
}4.3测试
测试类测试:
import com.xha.utils.SensitiveReplaceUtil;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import javax.annotation.Resource;@SpringBootTest
public class SensitiveWordTest {@Resourceprivate SensitiveReplaceUtil sensitiveReplaceUtil;@Testpublic void SensitiveWordFilter() {String string = "我是成人视频,打跑日本鬼子";String replaceSensitiveWord = sensitiveReplaceUtil.replaceSensitiveWord(string, 2);System.out.println(string + "->" + replaceSensitiveWord);}
}查看控制台打印:

参考博客1
参考博客2
这篇关于基于确定有穷自动机(DFA算法)实现敏感词过滤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


