detach专题

C++中detach的作用、使用场景及注意事项
《C++中detach的作用、使用场景及注意事项》关于C++中的detach,它主要涉及多线程编程中的线程管理,理解detach的作用、使用场景以及注意事项,对于写出高效、安全的多线程程序至关重要,下... 目录一、什么是join()?它的作用是什么?类比一下:二、join()的作用总结三、join()怎么
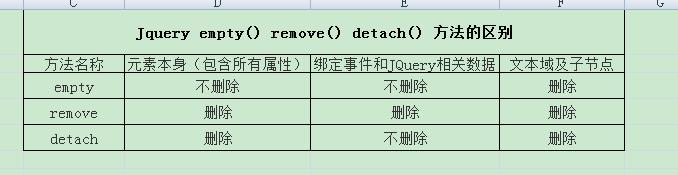
Jquery empty() remove() detach() 方法的区别
引言: 最近项目中用到了这几个方法,感觉很大程度上有些相似,查了Jquery的api,同时也找了很多博客文章,发现还是理解不到区别。最后在很多材料和自己的事例验证中,终于找到了区别,不敢独占特拿出来分享。 方法简介: empty() This method removes not only child (and other descendant)
pthread_join和pthread_detach的作用
每一个线程在任何情况,要么是可结合的状态(joinable),要么是可分离的状态(detached)。 先将这两个函数的原型列一下 int pthread_join(pthread_t tid, void ** pthread_return); int pthread_detach(pthread_t tid); 当我们的线程运行结束后,最后显示的调用被回收。这样就出现两种回收方式。 1

fragment中的attach/detach方法说明
使用add()加入fragment时将触发onAttach(),使用attach()不会触发onAttach() 使用replace()替换后会将之前的fragment的view从viewtree中删除 触发顺序: detach()->onPause()->onStop()->onDestroyView() attach()->onCreateView()->onActivityCreat

(四)成员函数做线程函数的使用方法,线程传参详解 detach()大坑
1、用类做可调用对象创建线程 注意: 需要定义operater()操作符成员函数 使这个类成为一个可以调用的对象。 2、成员函数做线程函数 3、detach大坑 使用detach时不要传递指针变量,容易出现主线程释放了指针,子线程还在访问导致内存泄漏的问题。 如果thread执行的函数的参数是类的对象,那么需要显示的强制类型转换,避免隐式转换,才能确保使用detach时,会
Linux alarm signal (SIGALRM) to detach process isAlive
题记 最近做项目遇到的问题,程序跑了多个process,每个process都是相互独立的,为了解耦,类似于微服务的架构,我们要求系统可以detach 到 主线程跑飞,死循环等其他bug 问题,最初的设计方案是:每个process 都会给每一个monitor的process 去发送keep alive 消息,由monitor去收集每个module的keep alive消息,然后去判断是否proce
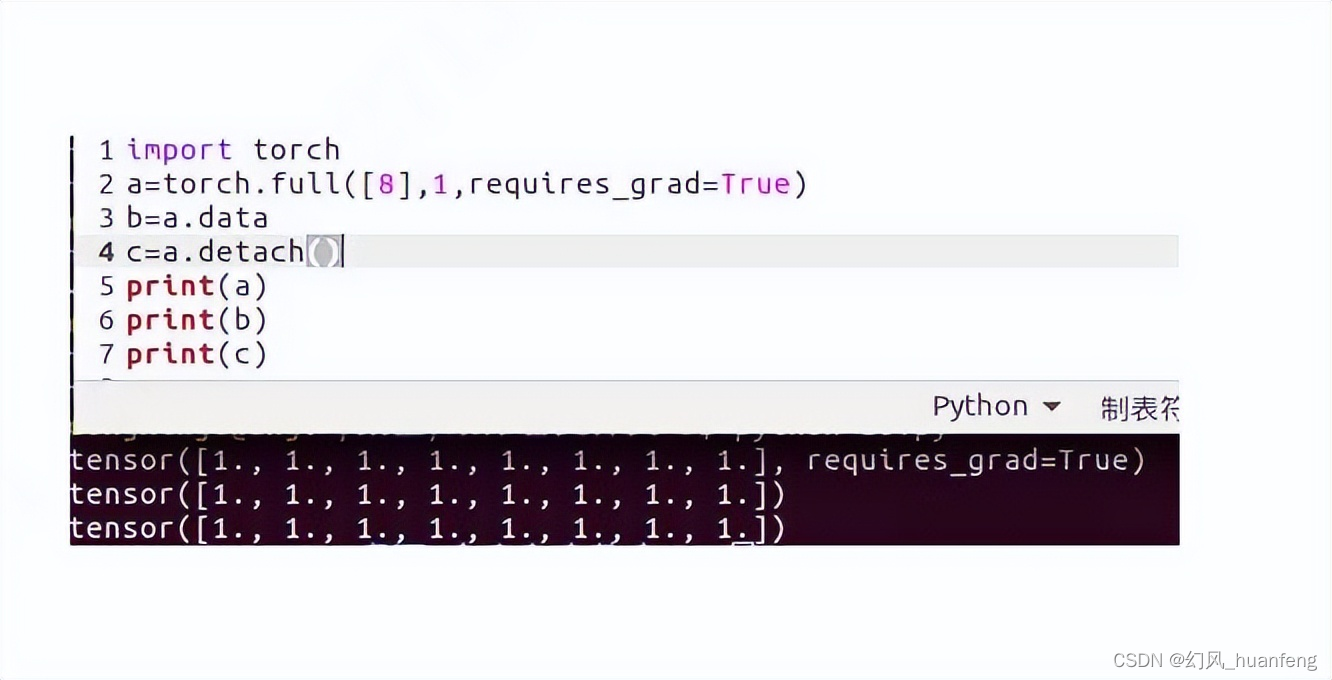
深度学习框架pytorch:tensor.data和tensor.detach()的区别
本文重点 本文我们区别一下tensor.data和tensor.detach(),我们所讲解的都是pytorch的1.0版本的情况 官方解释 返回一个新的张量,它与当前图形分离。结果永远不需要梯度。返回的张量与原始张量共享相同的存储空间。将看到对其中任何一个的就地修改,并且可能在正确性检查中触发错误。 代码一 import torcha=torch.full([8],1,requ
pycharm debug 的时候 waiting for process detach
当你使用pycharm debug或者run的时候,突然出现了点不动,然后一直显示:waiting for process detach 可能是以下问题: 1、需要设置Gevent compatible pycharm一直没显示运行步骤,只是出现waiting for process detach-CSDN博客 2、你的pycharm版本不是很行 我用的pycharm 2024版
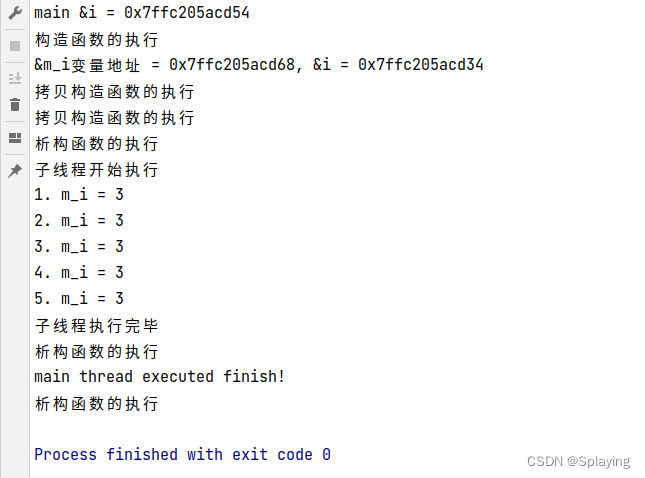
C++多线程:线程的创建、join、detach、joinable方法(二)
1、线程的开始与结束 程序运行起来,生成一个进程,该进程所持有的主线程开始自动运行,main主线程运行完所有的代码从main函数中返回表示整个进程运行完毕,标志着主线程和进程的死亡,等待操作系统回收资源,因为有可能成为孤儿或者僵尸进程所以需要等待。如果创建自己的线程,也需要从一个函数开始运行(初始函数),一旦运行完毕就代表着这个线程运行结束。当主线程运行结束,子线程并没有执行完毕也会被操作系统强

理论学习:outputs_cls.detach()的什么意思
在PyTorch中,.detach()方法的作用是将一个变量从当前计算图中分离出来,返回一个新的变量,这个新变量不会要求梯度(requires_grad=False)。这意味着使用.detach()方法得到的变量不会在反向传播中被计算梯度,也就是说,对这个变量的任何操作都不会影响到梯度的计算和模型的参数更新。 在上下文outputs_cls.detach()中的具体意义是: output
《C++ Concurrency in Action》笔记1 join和detach
先看一段程序: void f() { } void call_f() { thread t(f); //做一些事情 t.join();//或者detach //做一些事情 } int main() { call_f(); system("pause"); return 0; } 在本程序中, t.join();后call_f的代码将不再

MayaNurbs建模:detach报错
奇怪,难道只有我遇到这个狗B问题吗,为什么我百度搜不到,当我分离一个nurbs曲线的时候会报错 // 警告: line 0: 对于该命令,历史将禁用,因为“保持原始”为禁用且某个选定项目没有历史。 // // 警告: line 0: detachCurve1 (分离曲线): 无法分离具有多个内部结的曲线。 // // 警告: line 0: detachCurve1 (分离曲线): 无法分

12-----关于调试SRS和follow-fork-mode,detach-on-fork的说明
1 follow-fork-mode,detach-on-fork 看下面的图表。 follow-fork-modedetach-on-fork说明parenton只调试主进程( GDB 默认)childon只调试子进程parentoff同时调试两个进程, gdb 跟主进程, 子进程 block 在 fork 位置childoff同时调试两个进程, gdb 跟子进程, 主进程 block 在

【pytorch】tensor.detach()和tensor.data的区别
文章目录 序言相同点不同点测试实例应用 序言 .detach()和.data都可以用来分离tensor数据,下面进行比较pytorch0.4及之后的版本,.data仍保留,但建议使用.detach() 相同点 x.detach()和x.data返回和x相同数据的tensor,这个新的tensor和原来的tensor共用数据,一者改变,另一者也会跟着改变新分离得到的ten
PyTorch detach():深入解析与实战应用
PyTorch detach():深入解析与实战应用 🌵文章目录🌵 🌳引言🌳🌳一、计算图与梯度传播🌳🌳二、detach()函数的作用🌳🌳三、detach()与requires_grad🌳🌳四、使用detach()的示例🌳🌳五、总结与启示🌳🌳结尾🌳 🌳引言🌳 在PyTorch中,detach()函数是实现计算图灵活控制的关键。通过理解其背后
【Python】torch中的.detach()函数详解和示例
在PyTorch中,.detach()是一个用于张量的方法,主要用于创建该张量的一个“离断”版本。这个方法在很多情况下都非常有用,例如在缓存释放、模型评估和简化计算图等场景中。 .detach()方法用于从计算图中分离一个张量,这意味着它创建了一个新的张量,与原始张量共享数据,但不再参与任何计算图。这意味着这个新的张量不依赖于过去的计算值。 下面是.detach()函数的优点: **缓存释放
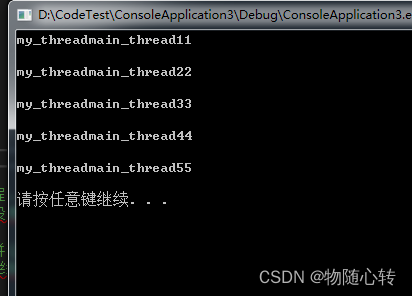
C++多线程join,detach
一、介绍 在声明一个std::thread对象之后,都可以使用detach和join函数来启动一个线程,区别在于两者是否阻塞主线程。 (1)当使用join()函数时,主线程阻塞,等待被调用的线程终止,然后主线程回收被调用线程的资源,并继续运行; (2)当使用detach()函数时,主线程继续运行,被调拥的线程驻留后台运行,主线程无法再取得该被调线程的控制权。当主线程结束时,由操作系统运行时库
【C++多线程编程】(五)之 线程生命周期管理join() 与 detach()
在C++中,std::thread 类用于创建和管理线程。std::thread 提供了两种主要的方法来控制线程的生命周期:join 和 detach。 detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。join方式,等待启动的线程完成,才会继续往下执行。 需要注意的是,一旦线程被分离,就无法再对其调用 join 方法,否则会导致程序终止。因此,在使用 de
【C++多线程编程】(五)之 线程生命周期管理join() 与 detach()
在C++中,std::thread 类用于创建和管理线程。std::thread 提供了两种主要的方法来控制线程的生命周期:join 和 detach。 detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。join方式,等待启动的线程完成,才会继续往下执行。 需要注意的是,一旦线程被分离,就无法再对其调用 join 方法,否则会导致程序终止。因此,在使用 de
pytorch 中detach() 和 with torch.no_grad()和eval()
detach() 和 torch.no_grad() 都可以实现相同的效果,只是前者会麻烦一点,对每一个变量都要加上,而后者就不用管了: - detach() 会返回一个新的Tensor对象,不会在反向传播中出现,是相当于复制了一个变量,将它原本requires_grad=True变为了requires_grad=False - torch.no_grad() 通常是在推断(inference
Pytorch 网络冻结的三种方法区别:detach、requires_grad、with_no_grad
1、requires_grad requires_grad=True # 要求计算梯度;requires_grad=False # 不要求计算梯度; 在pytorch中,tensor有一个 requires_grad参数,如果设置为True,那么它会追踪对于该张量的所有操作。在完成计算时可以通过调用backward()自动计算所有的梯度,并且,该张量的所有梯度会自动累加到张量的.grad属
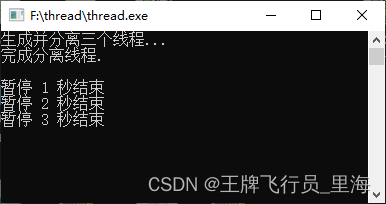
C\C++ Thread 分析线程detach()
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan 简介: 分离线程detach(),下面的例子创建三个线程并分离,主线程等待三个线程5秒时间。 注意主线程结束会调用exit(),此函数将整个进程结束,所有的线程都会退出。 线程分离后不可接合并且可以安全地销毁。 效果: 代码: #include <iost
R语言使用detach函数接触dataframe数据的绑定(解除绑定后使用$符号访问数据列)
R语言使用detach函数接触dataframe数据的绑定(解除绑定后使用$符号访问数据列) 目录 R语言使用detach函数接触dataframe数据的绑定(解除绑定后使用$符号访问数据列)
Pytorch截断计算图:detach操作
官方解析: torch.Tensor.detach(): Returns a new Tensor, detached from the current graph. The result will never require gradient. 举个例子: 在GAN训练中,训练判别器D时,无需调整生成器G的参数。 fake_image = Generato
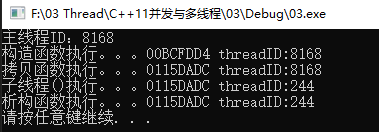
线程传参详解,detach()大坑,成员函数做线程函数
一、传递临时对象作为线程参数 1.1 要避免的陷阱1 #include<iostream>#include<thread>using namespace std;void myprint(const int &i,char* pmybuf) {cout << i << endl;cout << pmybuf << endl;return;}int main() {int mvar = 6