ddpg专题
【强化学习-Mode-Free DRL】深度强化学习如何选择合适的算法?DQN、DDPG、A3C等经典算法Mode-Free DRL算法的四个核心改进方向
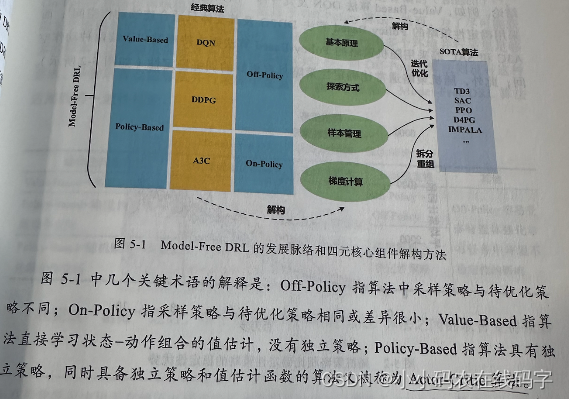
【强化学习-DRL】深度强化学习如何选择合适的算法? 引言:本文第一节先对DRL的脉络进行简要介绍,引出Mode-Free DRL。第二节对Mode-Free DRL的两种分类进行简要介绍,并对三种经典的DQL算法给出其交叉分类情况;第三节对Mode-Free DRL的四个核心(改进方向)进行说明。第四节对DQN的四个核心进行介绍。 DRL的发展脉络 DRL沿着Mode-Based和Mode

【RL】(task4)DDPG算法、TD3算法
note 文章目录 note一、DDPG算法二、TD3算法时间安排Reference 一、DDPG算法 DDPG(Deep Deterministic Policy Gradient)算法 DDPG算法是一种结合了深度学习和确定性策略梯度的算法。它主要解决的是在连续动作空间中,智能体(agent)如何通过不断尝试来学习到一个最优策略,使得在与环境交互的过程中获得最大的回报。
MATLAB - 比较 DDPG Agent 和 LQR 控制器
系列文章目录 前言 本示例展示了如何训练深度确定性策略梯度(DDPG)Agent,以控制 MATLAB® 中建模的二阶线性动态系统。该示例还将 DDPG Agent 与 LQR 控制器进行了比较。 有关 DDPG 代理的更多信息,请参阅深度确定性策略梯度 (DDPG) 代理。有关如何在 Simulink® 中训练 DDPG agent 的示例,请参阅训练 DDPG agent 向上摆

ddpg/Continuous control with deep reinforcement learning
文章目录 总结细节 总结 融合dqn buffer+actor/critic分别2个网络,连续的action(更新时不是 ∇ θ π ( a ∣ s ) \nabla_\theta\pi(a|s) ∇θπ(a∣s)了,而是 ∇ θ μ ( s ) \nabla_\theta\mu(s) ∇θμ(s), μ \mu μ是actor网络)、连续的states 细节 之前的方法

【八】强化学习之DDPG---PaddlePaddlle【PARL】框架{飞桨}
相关文章: 【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学 【二】-Parl基础命令 【三】-Notebook、&pdb、ipdb 调试 【四】-强化学习入门简介 【五】-Sarsa&Qlearing详细讲解 【六】-DQN 【七】-Policy Gradient 【八】-DDPG 【九】-四轴飞行器仿真
【八】强化学习之DDPG---PaddlePaddlle【PARL】框架{飞桨}
相关文章: 【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学 【二】-Parl基础命令 【三】-Notebook、&pdb、ipdb 调试 【四】-强化学习入门简介 【五】-Sarsa&Qlearing详细讲解 【六】-DQN 【七】-Policy Gradient 【八】-DDPG 【九】-四轴飞行器仿真
强化学习--DDPG
DDPG 强化学习 DDPGDPGDDPG DPG DQN算法的一个主要缺点就是不能用于连续动作空间,这是因为在DQN算法中动作是通过贪心策略或者说argmax的方式来从Q函数间接得到,这里Q函数就相当于DDPG算法中的Critic。 而要想适配连续动作空间,我们干脆就将选择动作的过程变成一个直接从状态映射到具体动作的函数。 DDPG 在DPG算法 的基础上,再结合一

初探强化学习(5)DDPG算法。包含逐行分析Pytorch代码和算法分析
这个博客适合老鸟来看,讲得很清楚。但是不详细。 有没有循环神经网络的感觉?这个博客都是这种图,很有意思 本文代码参考这个博客点击博客两字即可跳转。。 主要从这个博客搬来的https://zhuanlan.zhihu.com/p/111257402 还有这个博客讲的很清楚https://blog.csdn.net/weixin_43316082/article/details/89467208
DDPG强化学习pytorch代码
DDPG强化学习pytorch代码 参照莫烦大神的强化学习教程tensorflow代码改写成了pytorch代码。 具体代码如下,也可以去我的GitHub上下载 '''torch = 0.41'''import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport gym
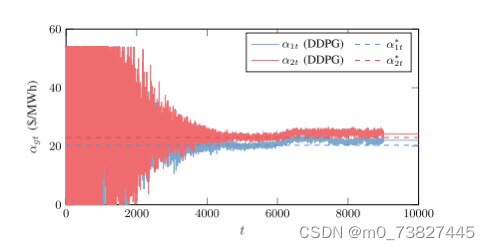
基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究 关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价 代码主要研究的是多个售电公司的竞标以及报价策略
python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究 关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价 说明文档:完美复现英文文档,可找我看文档 主要内容: 代码主要研究的是多个售电公司的竞标以及报价策略,属于电力市场范畴,目前常用博弈论方法寻求电力市场均衡,但是此类方法局限于信息完备的简单市场环境,难以直观地反映竞争性的市场环境,因此,本代码通过深度确定性梯
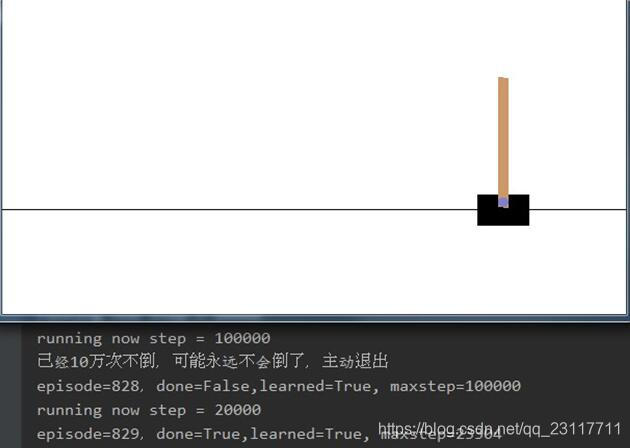
使用DDPG算法实现cartpole 100万次不倒
DDPG的全称是Deep Deterministic Policy Gradient,一种Actor Critic机器增强学习方法。 CartPole是http://gym.openai.com/envs/CartPole-v0/ 这个网站提供的一个杆子不倒的测试环境。 CartPole环境返回一个状态包括位置、加速度、杆子垂直夹角和角加速度。玩家控制左右两个方向使杆子不倒。杆子倒了或超出水平位置

深度强化学习(文献篇)—— 从 DQN、DDPG、NAF 到 A3C
自己第一篇 paper 就是用 MDP 解决资源优化问题,想来那时写个东西真是艰难啊。 彼时倒没想到这个数学工具,如今会这么火,还衍生了新的领域——强化学习。当然现在研究的内容已有了很大拓展。 这段时间会做个深度强化学习的专题,包括基础理论、最新文献和实践三大部分。 DRL 的核心思想是,用神经网络来表征值函数或者参数化 policy,从而使用梯度优化方法来优化损失。 本篇介绍近年来 D
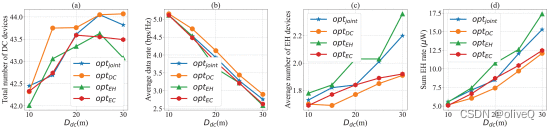
论文阅读—基于扩展DDPG算法的无人机辅助无线物联网网络多目标优化(点|多)
文章目录 摘要贡献 介绍系统模型—具有双天线无人机和单天线物联网设备物联网设备无人机Channel能量收集 问题定义DQN不行---要连续动作 无人机辅助数据采集和能量传输的MODDPG算法Environmental Modelstate spaceaction spaceReward MODDPG Algorithm 实验参数设置展示了所提出的MODDPG算法的有效性和收敛性策略性能对比