datanode专题

【Hadoop|HDFS篇】DataNode
1. DataNode的工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 2)DataNode启动后向NameNode注册,通过后,周期性(6h)的向NameNode上报所有块信息。 DN向NN汇报当前解读信息的时间间隔,默认6小时。 DN扫描自己节点块信息列表的时间,默认为

DataNode 和 NameNode
在 Apache Hadoop 的分布式文件系统 (HDFS) 中,DataNode 和 NameNode 是两个核心组件,它们共同协作以实现大规模数据存储和管理的功能。下面我将详细介绍这两个组件的作用和职责。 NameNode NameNode 是 HDFS 的主节点 (Master node),负责管理文件系统的命名空间和元数据。它的主要职责包括: 元数据管理: NameNode 存储

Hadoop的namenode的管理机制,工作机制和datanode的工作原理
Hadoop的namenode的管理机制,工作机制和datanode的工作原理 HDFS前言: 1) 设计思想 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析; 2)在大数据系统中作用: 为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务 3)重点概念:文件切块
hadoop集群运行jps命令以后Datanode节点未启动的解决办法
hadoop集群运行jps命令以后Datanode节点未启动的解决办法 出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。 1:其实网上已经有解决办法了,这里自己脑补一下,也可以让别人看到我

hadoop datanode未启动
查看日志,报错 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in /usr/hadoop-1.2.1/hdfs/data: namenode namespaceID = 697999702; datanode namespaceID =
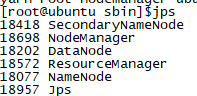
Hadoop 启动后使用JPS查看没有DataNode
报错:RemoteException(java.io.IOException): File /tmp/new/data.txt could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this
hadoop sbin/start-dfs.sh报错 ERROR: Cannot set priority of datanode process
错误信息: hadoop-3.1.3 启动HDFS时报错,具体错误信息如下: [root@hadoop10 hadoop-3.1.3]# sbin/start-dfs.shStarting namenodes on [hadoop10]上一次登录:四 12月 10 12:11:50 CST 2020pts/1 上hadoop10: namenode is running as proce
hadoop其中一个节点坏了,用其他节点克隆的教程+datanode正常显示,但master只有1个livenodes
如果一个slave出了非常棘手的问题,还是用其他slave克隆吧,很快的。 克隆教程: 1.克隆后只需要:sudo gedit /etc/network/interfaces,把ip地址改好。 2.ssh不需要重新设置,其他东西也都不需要重新进行设置 其他节点不需要做任何的改动,不要乱删,更不要乱重新format你的hadoop,有可能会id不一致导致hadoop启动不出来。 3.去克隆
hadoop中datanode无法启动
摘要:该文档解决了多次格式化文件系统后,datanode无法启动的问题 一、问题描述 当我多次格式化文件系统时,如 grid@masternode:~/hadoop$ bin/hadoop namenode -format 会出现datanode无法启动,查看slave节点的日志,发现包含如下信息: 2012-09-07 05
hadoopnbsp;datanode启动不起来
原文地址:hadoop datanode启动不起来 作者:老四 hadoop datanode启动不起来转自:http://book.51cto.com/art/201110/298602.htm 如果大家在安装的时候遇到问题,或者按步骤安装完后却不能运行Hadoop,那么建议仔细查看日志信息,Hadoop记录了详尽的日志信息,日志文件保存在logs文件夹内。 无论是启动,还
在搭建好Hadoop集群后,namenode与datanode两个过程不能起来,或者一个启动之后另一个自动关闭
故障现像: 此故障可以算是在换电脑搭集群后最多的故障了,首先是从节点上相关进程都没起来,后来又是进程起来后从节点上datanode节点没起来,最后是datanode进程起来之后,主节点上namenode进程又没起来。此故障看起来一波三折,实际上在理解好相关原理后,解决起来要比第一个故障轻松一些。 解决思路: 原理为先:首先要找到对应关系,主节点上namenod
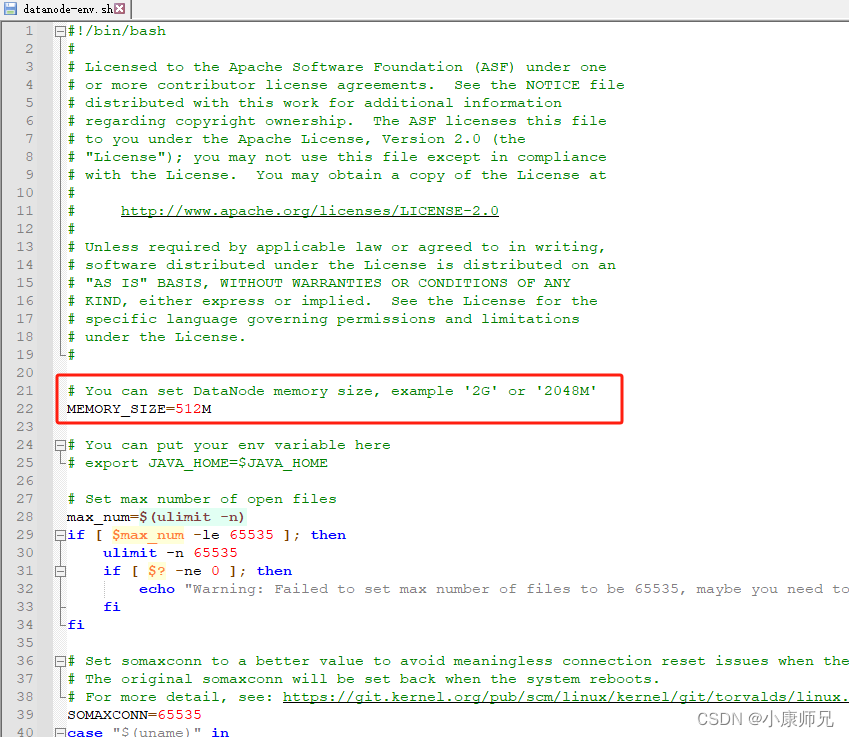
IoTDB 入门教程 问题篇①——内存不足导致datanode服务无法启动
文章目录 一、前文二、发现问题三、分析问题四、继续分析五、解决问题 一、前文 IoTDB入门教程——导读 二、发现问题 执行启动命令,但是datanode服务却无法启动,查询不到6667端口 bash sbin/start-standalone.sh 进而导致数据库连接也同样失败 [root@iZ2ze30dygwd6yh7gu6lskZ apache-io
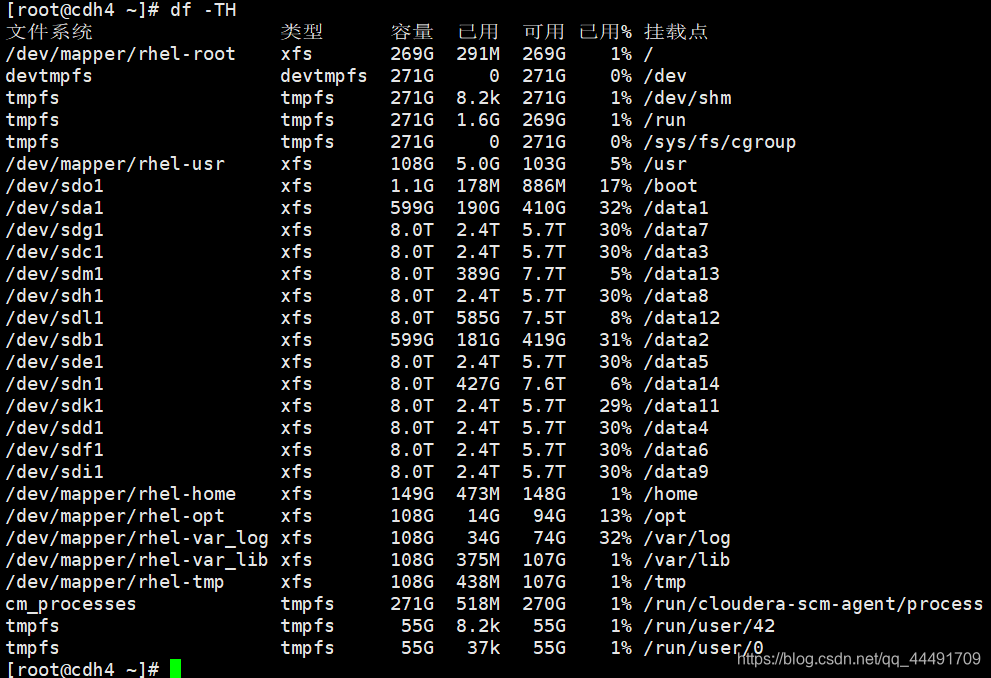
cdh cm界面HDFS爆红:不良 : 该 DataNode 当前有 1 个卷故障。 临界阈值:任意。(Linux磁盘修复)
一、表现 1.cm界面 报错卷故障 检查该节点,发现存储大小和其他节点不一致,少了一块物理磁盘 2.查看该磁盘 目录无法访问 dmesg检查发现错误 dmesg | grep error 二、解决办法 移除挂载 umount /data10 #可以移除挂载盘,或者移除挂载目录均可。 umount -vl /data10 # 如果出现目录忙,请加参数 df

Hadoop集群动态添加datanode节点步骤
总结一下在Hadoop集群动态添加datanode节点相关步骤。 1. 在新节点安装好hadoop,并把namenode的有关配置文件复制到该节点 2. 修改namenode节点的masters和slaves文件,增加该节点 3. 设置各节点ssh免密码进出该节点,设置IP映射 4. 单独启动该节点上的Datanode和Nodemanager
hadoop生产集群离线datanode(遇到的问题及解决方法)
1、修改namenode节点的hdfs-site.xml(master主机) <property> <name>dfs.hosts.exclude</name> <value>file_path</value> </property> 2、file_path文件中存储要离线的几点名称 3、执行命令 hdfs dfsadmin -refreshNodes 问题:执

由于多次初始化,导致Hadoop集群jps命令缺少DataNode解决方案
hadoop集群由于多次初始化导致所有集群缺少DataNode解决方法 原因: 解决命令:cd /opt/bigdata/hadoop/hadoop260/dfs/ rm -rf data/ 然后 启动hadoop就解决了
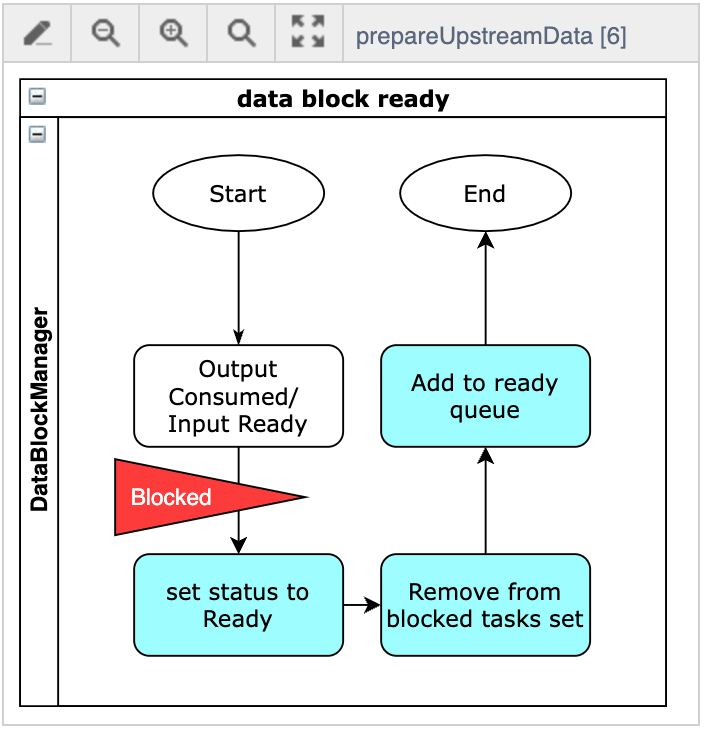
Apache IoTDB 查询引擎源码阅读——DataNode 上 DriverTask 调度与执行
背景 Apache IoTDB 查询引擎目前采用 MPP 架构,一条查询 SQL 大致会经历下图几个阶段: FragmentInstance 是分布式计划被拆分后实际分发到各个节点进行执行的实例。由于每个节点会同时接收来自于多个并发 Query 的多个 FragmentInstance,这些 FragmentInstance 在执行时可能由于等待上游数据而处于阻塞状态、或者数据就绪
HDFS 系列六:DataNode 工作机制
文章目录 6. HDFS 其他功能6.1 集群间数据拷贝6.2 Hadoop 存档6.2.1 理论概述6.2.2 案例实操 6.3 快照管理6.3.1 基本语法6.3.2 案例实操 6.4 回收站6.4.1 默认回收站6.4.2 启用回收站6.4.3 查看回收站6.4.4 修改访问垃圾回收站用户名称6.4.5 进入回收站6.4.6 恢复回收站数据6.4.7清空回收站 6. HD
hadoop 未启动datanode
分别运行 start-dfs.sh, start-yarn.sh jps后未发现 datanode 有 java.io.IOException: Incompatible clusterIDs in /opt/hadoop/hadoop-2.2.0/dfs/data: namenode clusterID = CID-b829ee60-d27d-4886-a39c-971c127f35b
绝对完美解决hdfs datanode数据和磁盘数据分布不均调整(hdfs balancer )——经验总结
Hadoop集群Datanode数据倾斜,个别节点hdfs空间使用率达到95%以上,于是新增加了三个Datenode节点,由于任务还在跑,数据在不断增加中,这几个节点现有的200GB空间估计最多能撑20小时左右,所以必须要进行balance操作。 通过观察磁盘使用情况,发现balance的速度明显跟不上新增数据的速度!!! 跟踪了一下balance的日志,发现两个问题:一是balance时
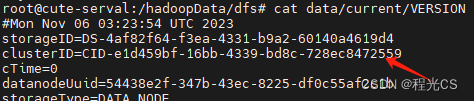
yarn集群HDFS datanode无法启动问题排查
一、问题场景 hdfs无法访问,通过jps命令查看进程,发现namenode启动成功,但是所有datanode都没有启动,重启集群(start-dfs.sh)后仍然一样 二、原因分析 先看下启动的日志有无报错。打开Hadoop的日志目录 cd $HADOOP_HOME/logs 按时间排序找出最新的datanode日志文件 查看日志文件末尾的100行 cat hadoop-ro

HDFS读写数据流程、NameNode与DataNode工作机制
文章目录 HDFS 写数据流程HDFS 读数据流程HDFS 节点距离计算HDFS 机架感知HDFS NN和2NN工作机制HDFS FsImage镜像文件HDFS Edits编辑日志HDFS 检查点CheckPoint时间设置HDFS 退役旧数据节点HDFS DataNode多目录配置HDFS DataNode工作机制HDFS 数据完整性HDFS 掉线时限参数设置 HDFS 写数据
DataNode: Exception in BPOfferService for Block pool BP解决方法
问题描述: hadoop启动hdfs的时候namenode和datanode进程都存在,但是感觉不到datanode的存在,也就是Live Nodes和Dead Nodes 都是0,异常信息: datanode.DataNode: Exception in BPOfferService for Block pool BP 解决方式: 清空:hadoop.tmp.dir
Hadoop分布式时远程Datanode无法启动的解决
blog迁移至 :http://www.micmiu.com [color=blue][size=medium]问题的基本现象:[/size][/color] 在测试Hadoop的分布式环境搭建时,在namenode启动时信息如下: [quote][michael@shnap hadoop]$ [color=blue]bin/start-all.sh [/color] startin

解决Hadoop种datanode无法启动问题,8088页面启动不了问题解决办法
解决Hadoop种datanode无法启动问题 首先进入/home/hadoop这各文件夹,进入/data/里面,进入/tmp/文件夹,进入/dfs/文件夹,里面有,data和name两个文件夹。 文件夹:cd /home/hadoop/data/tmp/dfs/ 如果是datanode启动不了就把启动不了的节点的data里面的/current/里面文件都删除,用:rm -rf 文件名,然后
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER.
Hadoop启动时警告,但不影响使用,强迫症的我还是决定寻找解决办法 WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER. 原因是Hadoop安装配置于root用户下,对文件需要进一步的配置,应该是由于新版