cs229专题

斯坦福CS229机器学习中文速查笔记.pdf
斯坦福CS229是一门经典的机器学习课程,算是机器学习领域的明星课,相信不少人在B站上看过这门课的视频。 这门课主要介绍了机器学习和统计模式识别。内容包括:监督学习(生成/鉴别学习,参数/非参数学习,神经网络,支持向量机);无监督学习(聚类,降维,核方法);学习理论(偏见/方差权衡,VC理论);强化学习和自适应控制。还有对机器学习最新应用的讨论,例如机器人控制,数据挖掘,自主导航,生物信息学,

斯坦福CS229(吴恩达授)学习笔记(5)
CS229-notes3 说明正文Problem Set #2: Kernels, SVMs, and Theory1. Kernel ridge regression2. ℓ 2 \ell _2 ℓ2 norm soft margin SVMs3. SVM with Gaussian kernel4. Naive Bayes and SVMs for Spam Classificati
斯坦福CS229(吴恩达授)学习笔记(6)
CS229-notes4 说明正文Problem Set #2: Kernels, SVMs, and Theory5. Uniform convergence 说明 此笔记 是cs229-notes4讲义中的学习内容,与B站上的“09 经验风险最小化”视频对应,主要是该部分对应的习题解答。 课程相关视频、讲义等资料可参照《斯坦福CS229(吴恩达授)学习笔记(1)》 获取。

斯坦福CS229(吴恩达授)学习笔记(3)
CS229-notes1-part3 说明正文Problem Set #1: Supervised learning1. Newton's method for computing least squares5. Exponential family and the geometric distribution 说明 此笔记 是cs229-notes1讲义中的第二部分学习内容
![[斯坦福CS229课程整理] Machine Learning Autumn 2016](/front/images/it_default.gif)

斯坦福CS229机器学习笔记-Lecture3 局部加权线性回归和 logistic regression
声明:此系列博文根据斯坦福CS229课程,吴恩达主讲 所写,为本人自学笔记,写成博客分享出来 博文中部分图片和公式都来源于CS229官方notes。 CS229的视频和讲义均为互联网公开资源 Lecture3 Lecture3的主要内容 · Locally weighted linear regression(局部加权线性回归)

斯坦福CS229机器学习笔记-Lecture2-线性回归+梯度下降+正规方程组
声明:此系列博文根据斯坦福CS229课程,吴恩达主讲 所写,为本人自学笔记,写成博客分享出来 博文中部分图片和公式都来源于CS229官方notes。 CS229的视频和讲义均为互联网公开资源 Lecture 2 这一节主要讲的是三个部分的内容: ·Linear Regression(线性回归) ·Gradient Descent

斯坦福CS229机器学习笔记-Lecture1
声明:此系列博文根据斯坦福CS229课程,吴恩达主讲 所写,为本人自学笔记,写成博客分享出来 博文中部分图片和公式都来源于CS229官方notes。 CS229的视频和讲义均为互联网公开资源。 Lecture1 这一节课,吴老师基本就讲解了一下机器学习的基本概念,可以说是做了一点科普,并没有讲什么实质性的内容。所以我也没得什么可以记录
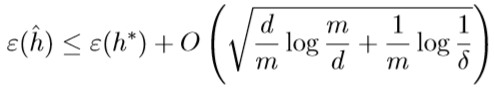
CS229 Machine Learning学习笔记:Note 4(学习理论)
偏置与方差的权衡 高偏置(high bias)与高方差(high variance)的概念在Coursera上Ng的机器学习课程中已经提过,这里不再赘述 预备知识 一致限(the union bound)/Boole不等式(Boole's inequality) \[P(A_1\cup \cdots \cup A_k)\leq P(A_1)+\cdots+P(A_k)\] k个事件中,至少一个事

因子分析、主成分分析(PCA)、独立成分分析(ICA)——斯坦福CS229机器学习个人总结(六)
因子分析是一种数据简化技术,是一种数据的降维方法。 因子分子可以从原始高维数据中,挖掘出仍然能表现众多原始变量主要信息的低维数据。此低维数据可以通过高斯分布、线性变换、误差扰动生成原始数据。 因子分析基于一种概率模型,使用EM算法来估计参数。 主成分分析(PCA)也是一种特征降维的方法。 学习理论中,特征选择是要剔除与标签无关的特征,比如“汽车的颜色”与“汽车的速度”无关; PCA中要处

K-means算法、EM算法——斯坦福CS229机器学习个人总结(五)
这一份总结的主题是无监督学习的EM算法。 在前面提到的逻辑回归、SVM、朴素贝叶斯等算法,他们的训练数据都是带有标签的(预分类结果),这样的算法被称为监督学习。当训练数据没有标签,只提供特征时,称为无监督学习。 EM算法(Expectation maxmization algorithm,最大期望算法)就是一种无监督学习算法,而它的名字本身就已经包含了这个算法的特点以及做法——“期望”、“最大
学习理论、模型选择、特征选择——斯坦福CS229机器学习个人总结(四)
这一份总结里的主要内容不是算法,是关于如何对偏差和方差进行权衡、如何选择模型、如何选择特征的内容,通过这些可以在实际中对问题进行更好地选择与修改模型。 1、学习理论(Learning theory) 1.1、偏差/方差(Bias/variance) 图一 对一个理想的模型来说,它不关心对训练集合的准确度,而是更关心对从未出现过的全新的测试集进行测试时的性能,即泛化能力(Ge

支持向量机(SVM)——斯坦福CS229机器学习个人总结(三)
鉴于我刚开始学习支持向量机(Support vector machines,简称SVM)时的一脸懵逼,我认为有必要先给出一些SVM的定义。 下面是一个最简单的SVM: 图一 分类算法:支持向量机(SVM)是一个分类算法(机器学习中经常把算法称为一个“机器”),它的目标是找到图中实线所表示的决策边界,也称为超平面(Hyperplane)支持向量(Support vectors

生成模型、高斯判别分析、朴素贝叶斯——斯坦福CS229机器学习个人总结(二)
1、生成学习算法(Generative Learning Algorithm) 1.1、判别模型与生成模型 判别模型:训练出一个总模型,把新来的样本放到这个总模型中,直接判断这个新样本是猫还是狗。 生成模型:先训练出一个猫的模型,再训练出一个狗的模型。把新来的样本放到猫的模型里,看它生成的概率是多少,再把它放到狗的模型里,看它生成的概率是多少。如果用猫的模型生成的概率比较大,就把新样本判断为

线性回归、logistic回归、广义线性模型——斯坦福CS229机器学习个人总结(一)
纪念我第一个博客的碎碎念 先前我花了四五个月的业余时间学习了Ng的机器学习公开课,学习的过程中我就在想,如果我能把这个课程啃完,就开始写一些博客,把自己的所得记录下来,现在是实现的时候了。也如刘未鹏的《暗时间》里所说,哪怕更新频率很低,也应该坚持(从现在开始)写博客,记录有价值的东西(思考的产物),好处多多。我没有大神的气场,只是觉得,就算没人看,作为自己的备忘也不错,侥幸能坚持很久的话,日积月

斯坦福大学cs229学习体会(1)-机器学习入门
斯坦福大学cs229学习体会(1)-机器学习入门 之前在上一家公司实习的时候做了一些和机器学习有关的内容,是一个朴素贝叶斯的分类预测。当时没有机器学习的基础,就自己一个人各种查阅资料,请教同事。总算是完成了一个基于朴素贝叶斯分类的预测算法的实现,并且准确度也很高。觉得整个项目很有意思,就自己开始自学机器学习的一些东西,看过cs229几节课也看过231,也看过台大的教授的课。但都因为自己的原因学到
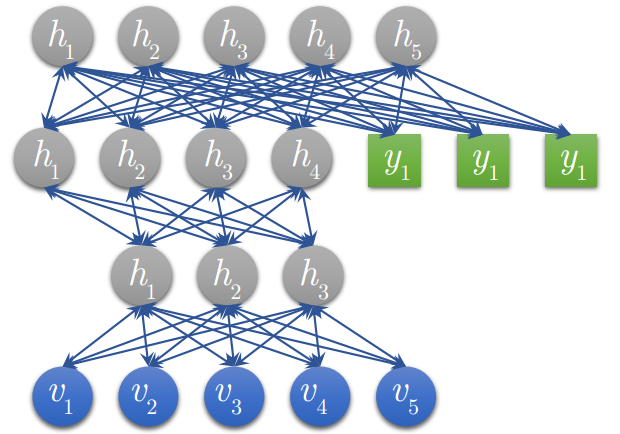
CS229 6.15 Neurons Networks Deep Belief Networks
Hintion老爷子在06年的science上的论文里阐述了 RBMs 可以堆叠起来并且通过逐层贪婪的方式来训练,这种网络被称作Deep Belife Networks(DBN),DBN是一种可以学习训练数据的高层特征表示的网络,DBN是一种生成模型,可见变量 与 个隐层的联合分布: 这里 x = h0,为RBM在第 k 层的隐层单元条件下的可见单元的条件分布, 是一个DBN顶部可见层与隐