cs224n专题

CS224N连载系列_word2vec作业的解析(2)
所有的语言模型的发展都离不开最基础的模型,统计语言模型是最重要的一环,word2vec也是如此,统计语言模型是用来计算一个句子的概率的概率模型,通常是基于一个语料库来构建,那什么叫一个句子的概率呢? 1、softmax softmax 函数通常处理机器学习分类问题的输出层的激活函数,它的输入是一个实数向量,输出向量的长度是与输入向量相同,但所有的取值范围是(0,1),且所有元素的和为1,输出向
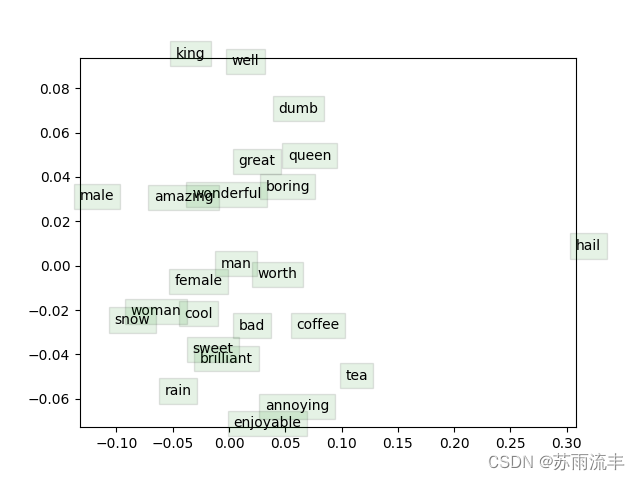
CS224N第二课作业--word2vec与skipgram
文章目录 CS224N: 作业2 word2vec (49 Points)1. Math: 理解 word2vec计算 J n a i v e − s o f t m a x ( v c , o , U ) J_{naive-softmax}(v_c, o, U) Jnaive−softmax(vc,o,U) 关于 v c v_c vc 的偏导数计算 J n a i v e −
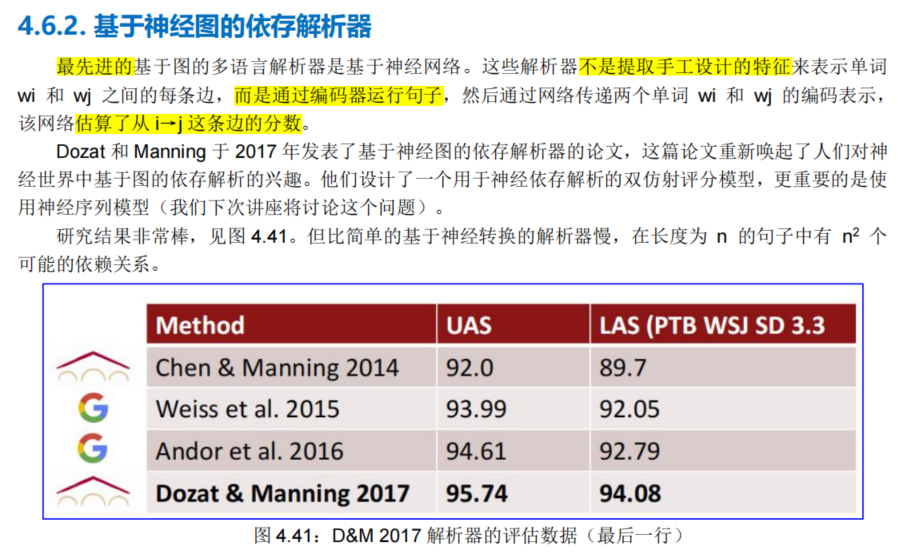
2021斯坦福CS224N课程笔记~4
4. 依存解析 Dependency Parsing 参考文档: https://zhuanlan.zhihu.com/p/420736640 https://www.showmeai.tech/article-detail/237 https://zhuanlan.zhihu.com/p/147321515 https://zhuanlan.zhihu.com/p/49992664 htt

【2019斯坦福CS224N笔记】(4)反向传播
csdn:https://blog.csdn.net/abcgkj github:https://github.com/aimi-cn/AILearners 上节课我们主要讲述了神经网络的一些基础知识和命名实体识别。但到目前为止,我们还没有对训练过程中的参数做出过多的描述。那么我们是如何对参进行更新的呢?这就是本文的主题——反向传播。 那么什么是反向传播呢?维基百科上是这样定义的: 反

CS224n | (2) Word Vectors and Word Senses
原文地址 cs224n系列博客笔记主要基于cs224n-2019,后续也会新增 CS224n-2020 里的更新部分:CS224n-2020 并未更新 Note 部分,但课程的部分课件进行了教学顺序上的调整与修改(Suggested Readings 也相应变动),需要注意的是三个 Guest Lecture 都是全新的。 本文为 Lecture 02 Word Vectors and Wor

斯坦福CS224n课程笔记1-introduction and Word vectors 2019
Human language and word meaning 语言是一个低带宽的信息传输方式,相比于5G,这决定了语言的熵会很高。 How do we have usable meaning in a computer? one-hot的字词表示: 词语维度是很高的,而且有很多衍生的词语,接近于无限的维度。词语之间没有相似度,即one-hot向量是正交的,相似词语和不相似词语之间都是正交

CS224n笔记12 语音识别的end-to-end模型
本文转自:http://www.hankcs.com/nlp/cs224n-end-to-end-asr.html 这次斯坦福请到了深度学习教父Hinton的弟子Navdeep来讲语音识别,他正在英伟达工作,怪不得N卡在深度学习中的地位如此之高。而他本人也在用Dell的搭载了N卡的XPS跑Ubuntu,一改以往“讲台必定信仰灯”的局面。 Automatic Speech Recognitio
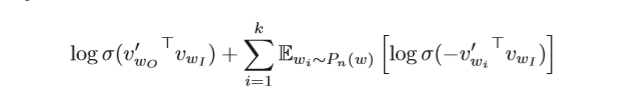
斯坦福大学NLP课程CS224N课第一次作业第三部分(上)
斯坦福大学NLP课程CS224N课第一次作业第三部分(上) CS224N课程还是有点难度的,第一次作业就需要手写word2vec了,不过如果知道wordvec的原理的话,写起来还是比较简单的,主要工作其实都在求导上,我们下面从Word2vec的原理层一点点的解开word2vec的神秘面纱。 1. word2vec原理 可能很多人都用过word2vec的包,但是还不知道原理,可能有的人觉得没有

【2019斯坦福CS224N笔记】(6)RNN和与语言模型
csdn:https://blog.csdn.net/abcgkj github:https://github.com/aimi-cn/AILearners 一、传统的语言模型 1.什么是语言模型 语言建模是一项基准测试任务,它帮助我们衡量我们在理解语言方面的进展。语言建模是许多NLP任务的子组件,特别是那些涉及生成文本或估计文本概率的任务:预测输入、语音识别、手写识别、拼写/语法修正

cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结
生成词向量的方法 以前大致有两种方法: ①是Matrix Factorization Method,主要代表是SVD Based的LSA等方法,核心是对共现矩阵(co-occurence)进行SVD(奇异值)分解,得到词向量。 ②是Iteration Based Method(Shallow window-based),主要代表是上节课讲到的Skip-Gram和CBOW。核心是概率,通过设置

【NLP CS224N笔记】Lecture 2 - Word Vectors2 and Word Senses
本次梳理基于Datawhale 第12期组队学习 -CS224n-预训练模块 详细课程内容参考(2019)斯坦福CS224n深度学习自然语言处理课程 1. 写在前面 自然语言处理( NLP )是信息时代最重要的技术之一,也是人工智能的重要组成部分。NLP的应用无处不在,因为人们几乎用语言交流一切:网络搜索、广告、电子邮件、客户服务、语言翻译、医疗报告等。近年来,深度学习方法在许多不同的NLP任

【CS224n】笔记45 Word Window分类与神经网络和反向传播
这节课介绍了根据上下文预测单词分类的问题,推导了对权值矩阵和词向量的梯度,初步展示了深度学习与传统机器学习方法不一样的风格。 笔记概要 1、分类的一些主要符号 2、主要思想 2.1、机器学习角度的分类 2.2、基于softmax分类器的定义 2.3、softmax分类器损失函数定义 2.4、需要更新的参数 2.5、参数过多导致的过拟合&&正则化解决方式 2.6、softmax分类器损失函数

CS224N学习笔记(十七)Multitask learning
Multitask指多任务学习,大致意思是一个NLP的模型可以完成多种任务。 一、单任务学习的局限和特点 由于{dataset,task,model,metric}等的发展,近年来single-task取得了很好的效果当训练集足够大,能够很容易局部最优对于通常更常用的AI,需要针对single-model的持续的学习(continus-learning),即很多时候不需要从头开始,顺着上次的结
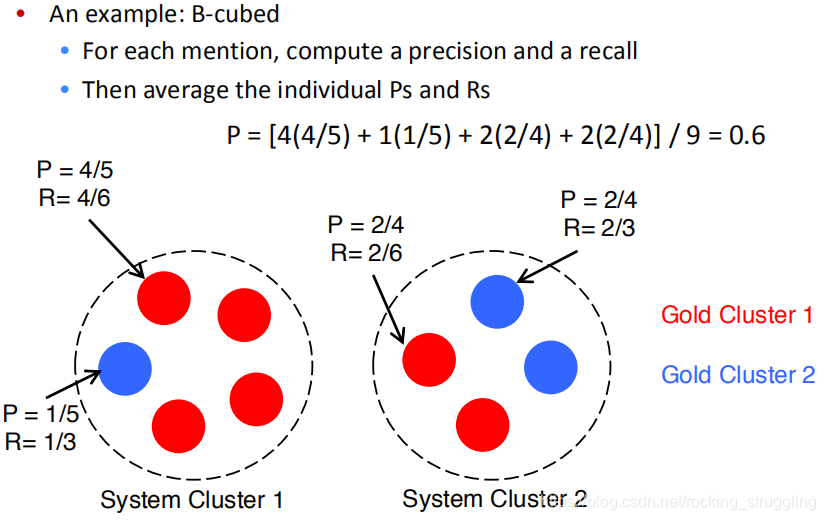
CS224N学习笔记(十六)Coreference Resolution
1.What is Coreference Resolution? Coreference Resolution 共指消解,一种语言中的语法现象,表示句子中多个指示(mention)指代同一个世界中的实体的情况,比如在下面的英文中,红色都指代奥巴马,黄色都指代希拉里,这种现象称为共指(coreference)。 Applications 共指能够影响对句子的理解,因此在很多地方都有应用: