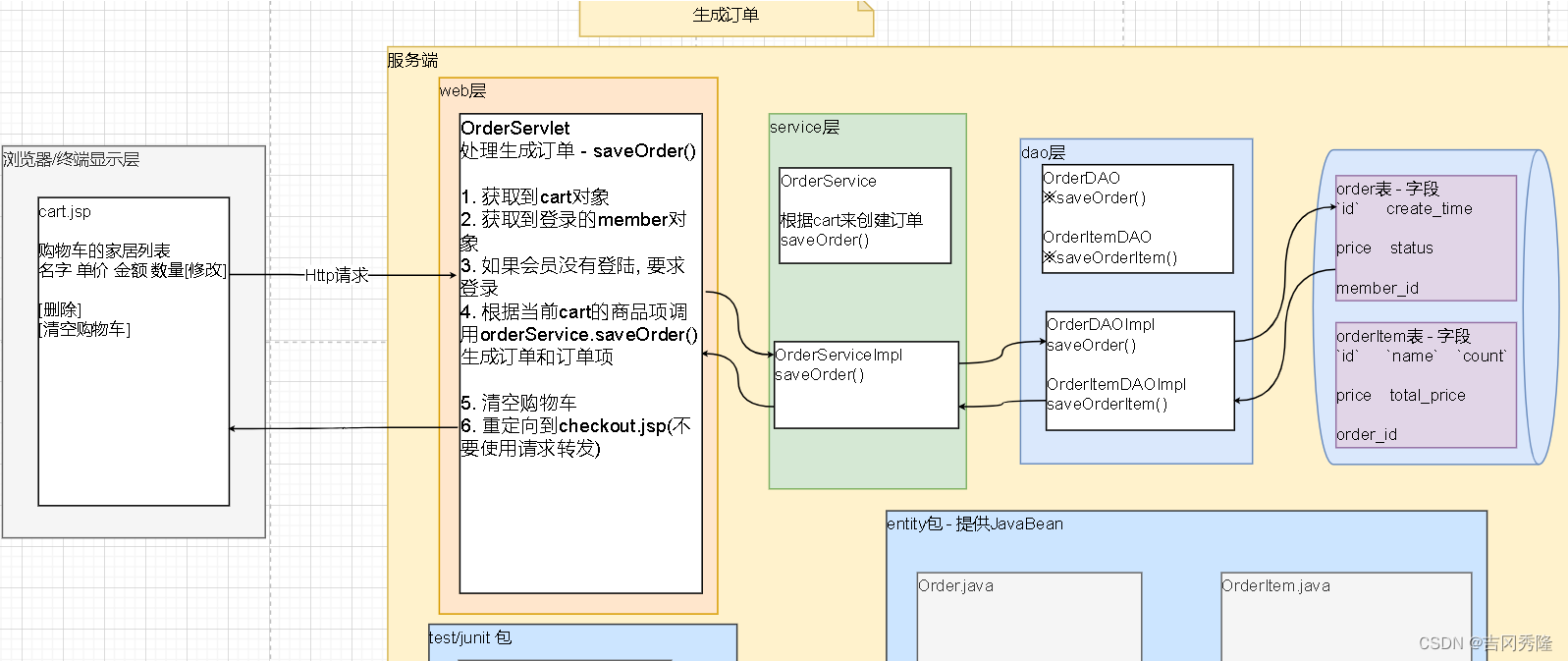
本文主要是介绍斯坦福大学NLP课程CS224N课第一次作业第三部分(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
斯坦福大学NLP课程CS224N课第一次作业第三部分(上)
CS224N课程还是有点难度的,第一次作业就需要手写word2vec了,不过如果知道wordvec的原理的话,写起来还是比较简单的,主要工作其实都在求导上,我们下面从Word2vec的原理层一点点的解开word2vec的神秘面纱。
1. word2vec原理
可能很多人都用过word2vec的包,但是还不知道原理,可能有的人觉得没有必要知道原理,会用就行。当然会用自然可以,但是我们我们只是会用的层次,那么我们遇到问题之后我们就不知道如何修改。word2vec是一种word embedding模型,而word embedding的结果一般是下游模型(如神经网络,机器学习模型等)的输入,如果我们最后发现结果不好或者特别好,我们又怎么解释这个好或者不好呢,我们把这种结果归功于我们的word embedding还是归结于我们下游模型选的好呢。就像打红警或者魔兽一样,地图有很多黑的地方,我们对那些地方一无所知,我们只有不断弄懂这些模型的原理,才能将神经网络看的更透彻,才能解开它神秘的面纱,直抵本质。
1. 原始的skip-gram和CBOW模型
word2vec包括两个模型,分别是skip-gram模型和cbow模型,这是Tomas Mikolov等人2013年提出的模型,原文地址。在这篇文章中并没有详细介绍skip-gram和cbow模型,只是分析了他们的复杂度和给了模型的基本结构图。我觉得这篇论文出彩的地方一个是两个模型,一个是作者关于这两个模型所做的大量实验。我们首先看看skip-gram模型:

这是原文中的图,我们先只看右边的skip-gram模型,模型是什么意思呢,输入时一个词向量,然后通过这个输入来预测上边(或者左边)两个词的向量和下边(或者右边)两个词的向量。
再次提一下什么是word embedding(词嵌入),一般的机器学习模型包括神经网络的输入都是数值型的,所以如果要处理词,首先需要将词转化成数值型的向量。最初的想法是构建词汇表V,然后将每一个词转化成一个1*V的一个one-hot向量,one-hot向量中文翻译就是独热,也叫独热编码,就是向量中只有一个1,其他元素都为0。但是很快研究者发现这样的表示不仅得到了大量的非常稀疏的向量或者矩阵,并且丢失了很多信息。1957年,Firth提出了一个词的意思是由他所处的环境或者说他周围的词所提供,也就是我们通常说的上下文。于是共现矩阵的理论就被提出了,共现矩阵的每个元素Xij便是单词i和单词j共同出现的次数,关于共同出现我们可以定义一个距离,当距离小于一直阈值可以判断为共同出现。这种方法的表示比one-hot表示方法多了很多信息,效果也比one-hot好,但是还是存在稀疏的问题,并且由于词汇的数目极大,共现矩阵也特别特别大,于是svd分解被提出了,svd分解是是用于矩阵降维的方法,可以将一个大矩阵降维成一个比较小的矩阵,这样每个词可以表示成一个几百或者几千维的向量,至此,词表示的方法就变成了将每个词转化成一个向量,并且每个向量大概50-2000维左右。
2003年,NLP大牛Bengio提出了使用神经网络基于N-gram模型预测后一个词并进行了词向量的训练,论文是A Neural Probabilistic Language Model,网络结构为:

这这篇论文中Bengio提出了每个词对应一个词向量,并通过神经网络和随机梯度下降来训练这些低维的词向量。而word embedding的思想就是将所有的词向量嵌入到低维空间,每个词都是低维空间中的一个点,这样每个词就表示成一个低维的向量,一般为50-2000维。
2013年,word2vec提出,相对一以往的词向量的训练,结果得到的很大的提升,使用神经网络来训练词向量也称为一种通用做法。
skip-gram算法使用中心词来预测周围词,具体做法是使用两个词的内积作为评价两个词相似度的准则(之后提出的fastText方法就只是换了个相似度计算方法),然后使用softmax来计算预测的概率并使用随机梯度下降进行更新。

其中Uo是需要预测的周围词向量,Vc是中心词向量,Uw是所有的词向量,一般在处理时我们使用两个矩阵,即每个词有两个向量,作为中心向量时,取中心矩阵中对于的向量,作为窗口的预测向量时,取窗口矩阵中对于的向量。每个词的词向量表示的最终结果为两个词向量的和。

这是CS224N的图,第一个矩阵W就是中心矩阵,第二个W`就是窗口向量。
而CBOW模型和skip-gram模型基本一样,只是CBOW模型中是使用周围词来预测中心词,预测时将周围词的向量相加取平均之后表示为周围向量,然后通过这个周围向量来预测中间向量:
同样的图在CBOW中,Uo表示为中心向量,Vc为周围词向量求和平均,Uw为所有的词向量。
同样有两个矩阵,每个词有两个向量,最终结果为两个向量的和。
2. 改进的基于负采样的skip-gram和CBOW模型
在2013年,Tomas Mikolov等人还发表了另外一篇论文,主要是在上一篇论文的基础上做了一些改进,论文题目是Distributed Representations of Words and Phrases and their Compositionality。在这篇论文中介绍了之后提出的skip-gram模型和CBOW模型的缺点,那就是softmax求解过程过于慢了,因为softmax分母的求解需要使用所有的词向量,而词向量是特别多的,所以这一步的求解就特别特别慢,所以如果能不适用softmax那么会对速度有很大的提升。
文中提出了两种方法,一种是Hierarchical Softmax方法,可以将O(n)复杂度降低到O(log(n))复杂度。另外一种是负采样,直接不需要计算softmax,我们作业中使用的负采样的方法,所以我们只讲解负采样的方法。
我们的目的是最大化向量词的相似度,这里相似度用内积表示,也就是最大化相邻词的内积,同理也就是最小化不相邻词的内积。所以我们可以将问题转化为二值分类问题,即对于一个向量词,同时随机在词汇中取K个词作为负样本,损失函数为:
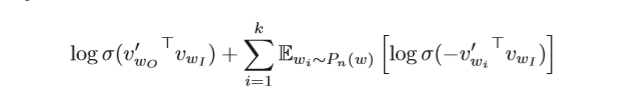
即最大化相邻词的内积并且将负采样的词内积最小化,使用随机梯度下降进行更新。
欢迎评论交流,也欢迎关注,会将CS224N的所有作业写成博客的。
这篇关于斯坦福大学NLP课程CS224N课第一次作业第三部分(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!