本文主要是介绍CS224N学习笔记(十六)Coreference Resolution,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.What is Coreference Resolution?
Coreference Resolution 共指消解,一种语言中的语法现象,表示句子中多个指示(mention)指代同一个世界中的实体的情况,比如在下面的英文中,红色都指代奥巴马,黄色都指代希拉里,这种现象称为共指(coreference)。


Applications
共指能够影响对句子的理解,因此在很多地方都有应用:
- Full text understanding
- Machine translation
- Dialogue Systems
Coreference Resolution in Two Steps
Coreference Resolution就是在NLP中针对共指现象中的一类应用,包含以下两小类:
- Detect the mentions (easy):只是检测
- Cluster the mentions (hard):检测还要分类
2.mention dection
mention具体时之语句中的一段指代的一些实体。一共有三种类型的mention:
- Pronouns 代词:I, your, it, she, him, etc.
- Named entities:People, places, etc.
- Noun phrases名字短语:“a dog,” “the big fluffy cat stuck in the tree”
通过其他的NLP任务可以做到这三种方法的分类,分贝是:
- Pronouns:Use a part-of-speech tagger 词性标记
- Named entities: Use a NER system 命名题识别
- Noun phrases:Use a parser 句法分析
但是通过上述任务得到的并不完全是mention,如图ppt:

How to deal with these bad mentions?
- 可以训练一个分类器对所有的metion直接进行分类
- 把所有的mention视为“candidate mentions”,之后运行你的coreference系统进行配对,然后抛弃那些没有配对的singleton mentions。
这样就有两种主要的思路:
- train a classifier specifically for mention detection
- jointly do mention-detection and coreference resolution end-to-end instead of in two steps
3.coreference 相似的语法分析
有一种很相近的语法叫 anaphora(回指),就是回值词anaphor由前面的词antecedent决定,说英文定义是:when a term (anaphor) refers to another term (antecedent),如图所示:

anaphora和coreference的区别如图所示:

anaphora和coreference是一种交叉的关系,不是所有的anaphora都是coreferential。
比如:


这种非coreferential的anaphora叫bridging anaphora.,它们之间的关系如图所示:
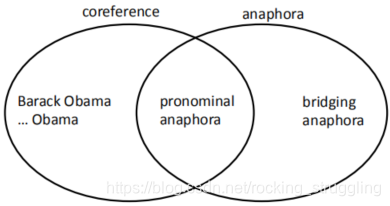
另外anaphora还有要给反义词叫Cataphora。
课程介绍了四类Coreference模型,如下:
- Rule-based (pronominal anaphora resolution)
- Mention Pair
- Mention Ranking
- Clustering
4.Traditional pronominal anaphora resolution
课程介绍了Hobbs’ naive algorithm,主要思想就是对语句进行结构的分析,然后用树状图去得到coreference关系,步骤挺多的,如图所示:


分析结构后得到的句子,如图:
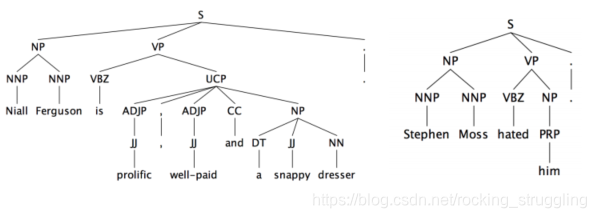
但是通过句子结构来分析并不能总是正确得到正确的coreference,如图看下面这个两个例子:


这两个例子的两个句子得结构都是相同的,但是句子中it和they显然不是指代同一个东西。因此完全从结构来分析mention是不合理,应该加入Knowledge-based部分。
5.Coreference Models: Mention Pair
模型目的是,将metion从句子中抽出来,然后分类如图所示:

模型的想法是训练一个两输入的二分类其,输入metion对 p ( m i , m j ) p(m_i,m_j) p(mi,mj),判断这个mention对是不是一个正常的mention对,如图所示:
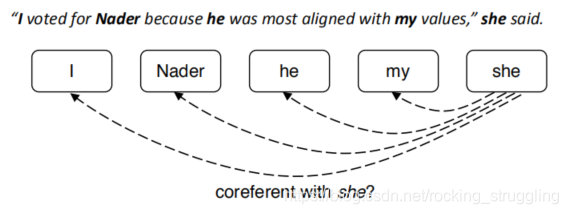
positive输出1,表示是一个metion pair,negtive输出0,表示不是mention pair。如图所示:
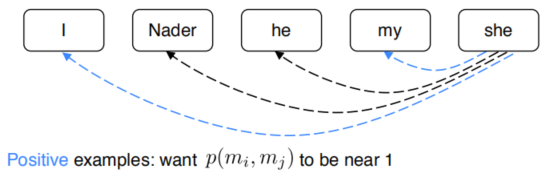
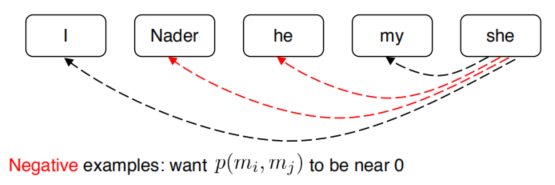
Mention Pair Training
训练的时候采用二分类的交叉熵代价函数,公式细节如ppt所示:
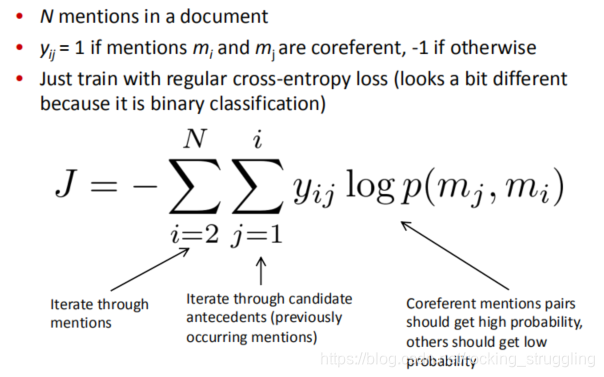
Mention Pair Training
Coreference resolution是一个聚类(cluster)问题,如何将metion pair转化成一个聚类问题?
可以设定一些阈值,将在这个阈值之上的相互的metion pair视为一个cluster,如图所示:
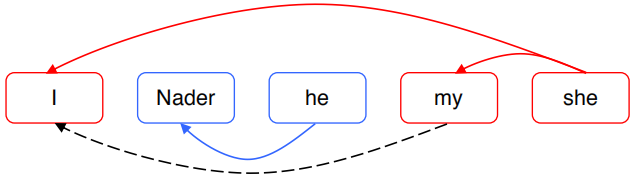
这样可以实现简单的聚类,但是容错率很低,如果发生错误,很可能将所有的聚为一类,如图所示:
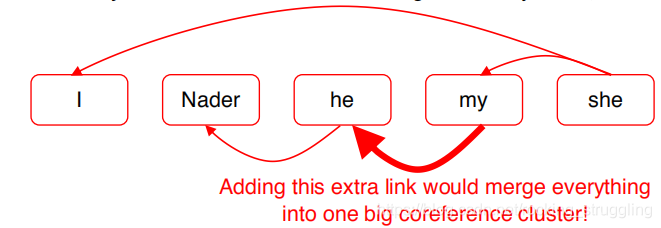
这种方法也由明显的去蹲点,如图:
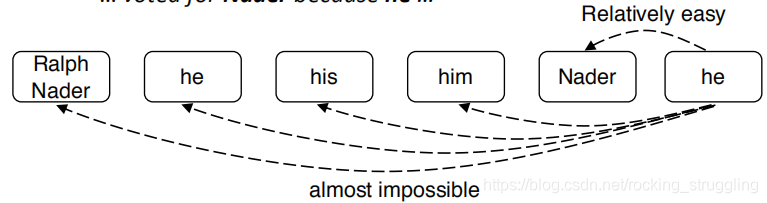
许多mentions有一个比较明显的antecedent,由许多不明显的antecedent,这个时候通过上述方式无差别的预测显然是不合理的,所以更好的是做一个不同的对比,ranking
6.Coreference Models: Mention Ranking
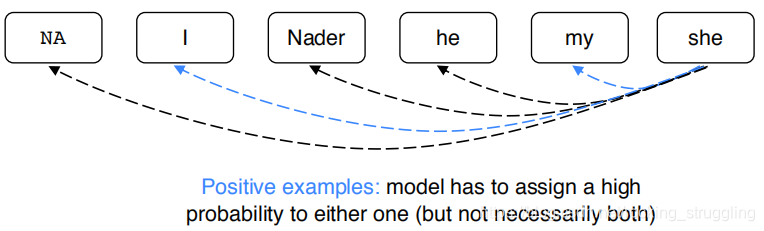
就是对每一个metion pair进行一个打分,根据score的大小确定最合适的coreference。为例保证程序的统一性,加了一个N/A项,给singleton和first metion也是其配成metion对,如图所示:
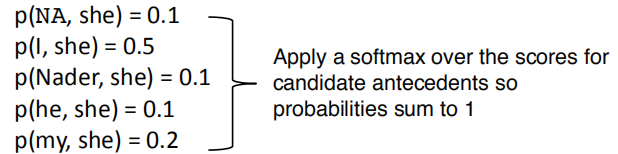
进行打分时,应用了softmax函数,使打分和为1,如图所示:
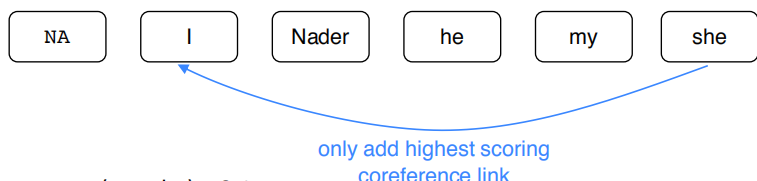
选择得分最高的作为correference link,如图:
Coreference Models: Training
这种模型的训练方式稍有不同,希望参考组(gold)对应的model pair取得的概率越大越好,得到如下公式(我没看明白):
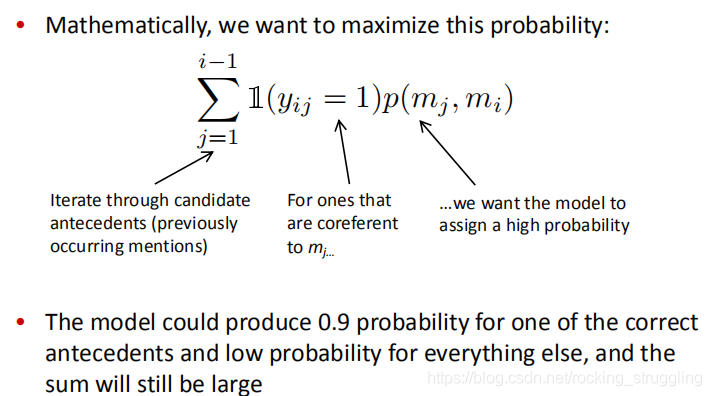
将这样一个公式转化为代价函数:
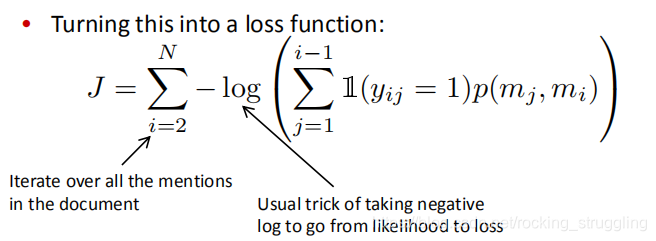
这个和model pair的模型很像,只不过只求出一个antecedent。
关键问题,怎么样计算概率?课程中说由三种主要的方法:
- Non-neural statistical classifier
- Simple neural network
- More advanced model using LSTMs, attention
A.Non-Neural Coref Model: Features
传统的非神经网络的方法直接给Mention一个特征,根据特征计算得分,如图所示:

B.Neural Coref Model
课程介绍了这种简单的神经网络模型如图所示:
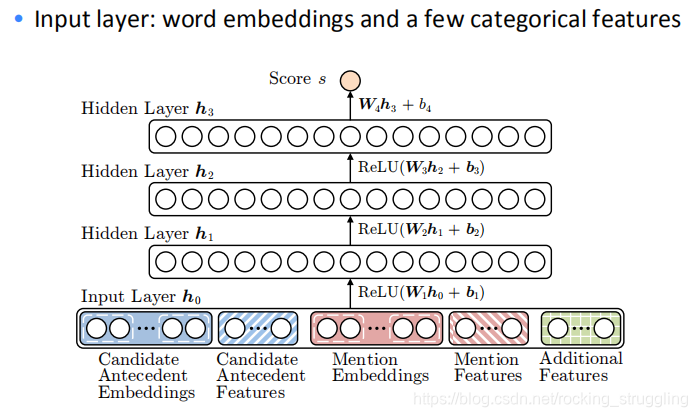
模型结构很简单,但是需要输入很多embedding和嵌入比如:Candidate Antecedent Embeddings、Candidate Antecedent Features等等,如图所示:

C. End-to-end Model
课程介绍了当前state-of-art的模型,也是一个mention ranking model,采用的是一种端到端的结构。它在普通的feed-forward NN 模型上做出了改进:
- Use an LSTM
- Use attention
- Do mention detection and coreference end-to-end
模型的结构如图所示:
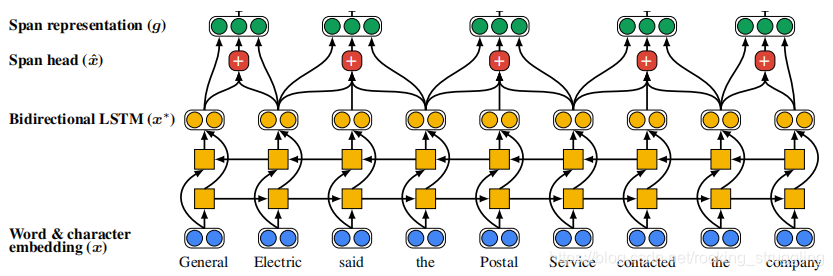
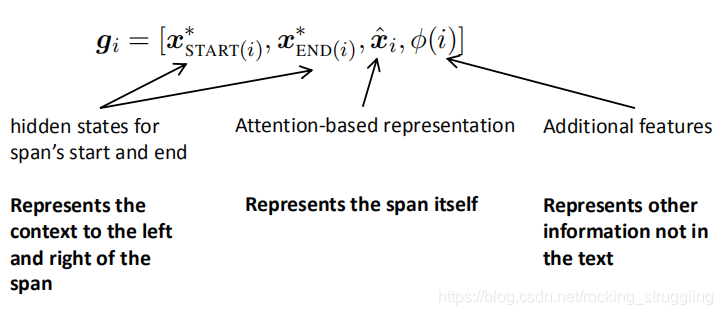
前面两层就是常规的embedding和encode层后面是一层特殊的span embedding层,如图:

span embedding由三部分构成,公式极其含义如下:
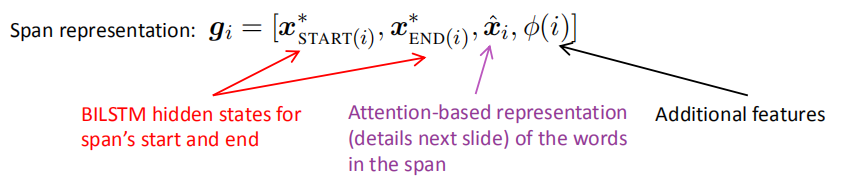
attention部分的计算如图所示:

课程也解释了span embedding层中各项的作用:
模型是这样计算分的:

模型有着非常明显的缺点,就是计算太复杂,需要对span进行修剪。
7.Coreference Models: Clustering-Based
另外一种coreference的分支,直接进行cluser。
课程这部分的内容基本上跳过了,详见ppt。
8.Coreference Evaluation
常用的评价指标有:MUC, CEAF, LEA, B-CUBED, BLANC。
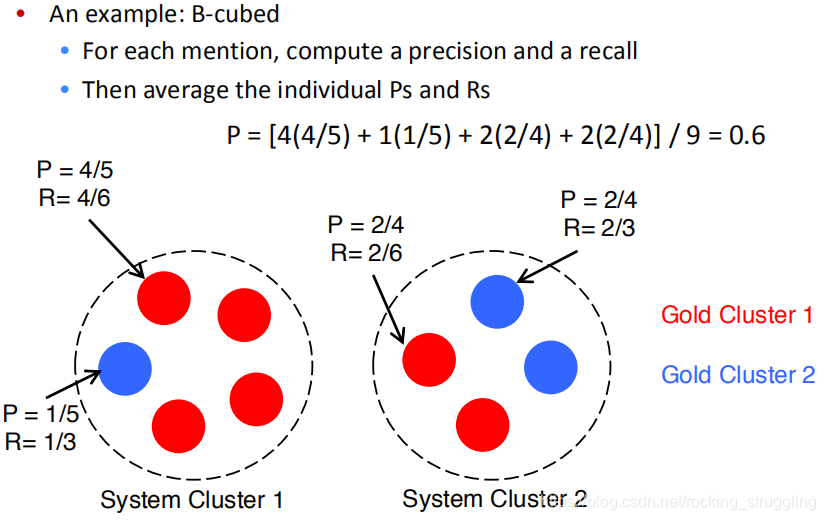
课程以B-cubed为例,首先计算每一个mention的precision和recall,然后根据这些计算B-cubed指标。
这篇关于CS224N学习笔记(十六)Coreference Resolution的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








