checkpoint专题

是谁还不会flink的checkpoint呀~
1、State Vs Checkpoint State:状态,是Flink中某一个Operator在某一个时刻的状态,如maxBy/sum,注意State存的是历史数据/状态,存在内存中。 Checkpoint:快照点, 是Flink中所有有状态的Operator在某一个时刻的State快照信息/存档信息 一句话概括: Checkpoint就是State的快照 目的:假设作业停止了,下次启动的

Flink在大规模状态数据集下的checkpoint调优
今天接到一个同学的反馈问题,大概是: Flink程序运行一段时间就会报这个错误,定位好多天都没有定位到。checkpoint时间是5秒,20秒都不行。 Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs://HDFSaaaa/flink/PointWid
Flink CheckPoint奇技淫巧 | 原理和在生产中的应用
简介 Flink本身为了保证其高可用的特性,以及保证作用的Exactly Once的快速恢复,进而提供了一套强大的Checkpoint机制。Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-

Flink重点难点:Flink任务综合调优(Checkpoint/反压/内存)
在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》 《Flink重点难点:网络流控和反压》 《Flink重点难点:维表关联理论和Join实战》 《Flink重点难点:内存模型与内存结构》 《Flink重点难点:Flink Table&SQL必知必会(一)》 Flink重点难点:Flink Table&SQL必知必会(二) CheckPoint调优

Flink重点难点:状态(Checkpoint和Savepoint)容错与两阶段提交
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 在阅读本文之前,你应该阅读过的系列: 《Flink重点难点:时间、窗口和流Join》《Flink重点难点:网络流控和反压》《Flink重点难点:维表关联理论和Join实战》《Flink重点难点:内存模型与内存结构》《Flink重点难点:Flink Table&SQL必知必会(一)》Flink重点难点:Flink Table&SQL必

SYNTH_CHECKPOINT_MODE
在为Vivado IP集成块设计文件(.bd)生成输出产品时,您 可以选择如何与顶层设计协调地综合块设计。 请参阅《Vivado Design Suite用户指南:使用IP设计IP子系统》中的此链接 集成器(UG994)[参考27]以获取更多信息。使用SYNTH_CHECKPOINT_MODE 您可以指定块设计将作为顶层设计的一部分进行合成, 在全球综合过程中。通过将SYNTH_CHECKPOIN

spark从入门到放弃五十四:Spark Streaming(14)checkpoint
1.概述 每一个spark streaming 应用正常来说都要7*24小时运转的,这就是实时计算程序的特点。因为要持续不断的对数据进行计算。因此,对实时计算的要求,应该是必须能够与应用程序逻辑无关的失败,进行容错。 如果要实现这个目标,spark streaming 程序就必须将足够的信息checkpoint 到容错的存储系统上,从而让他能够从失败中进行恢复。有两种数据需要进行checkpo
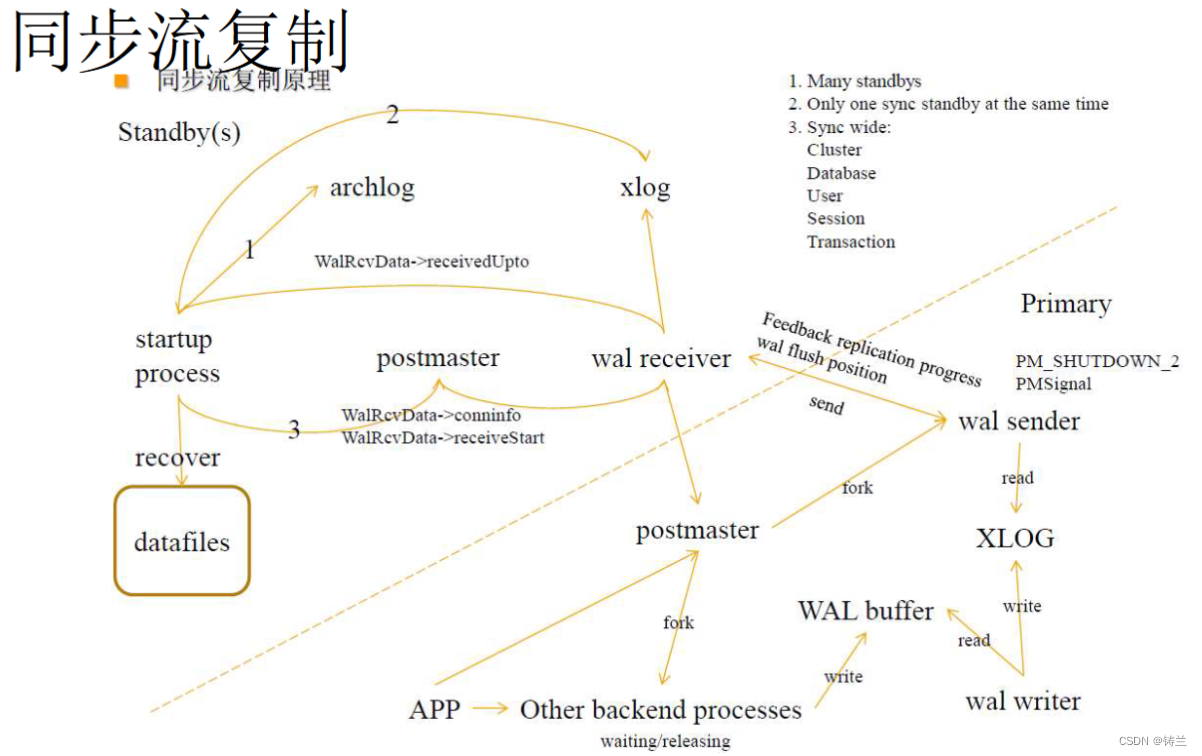
帮您理解PostgreSQL(WAL、XLOG、CheckPoint进程、LSN、PITR、SR)
文章目录 一、WAL、XLOG、LSN二、检查点进程与pg_control文件-负责脏页刷盘、数据库恢复三、基础备份与时间点恢复PITR四、原生复制功能与流复制(SR Streaming Replication) 一、WAL、XLOG、LSN 在计算机领域,WAL是Write Ahead Logging的缩写,指将变更、行为先写入事务日志的协议和规则。 在PostgreSQL中,
No module named ‘torch.distributed.checkpoint.format_utils问题解决
完整代码: Traceback (most recent call last):File "/data/user/BMLU-use/src/English_chat/qwen1.5.py", line 97, in <module>main(model_path=args.model_path,max_length=args.max_length,name=args.name)File "/da

checkpoint中保存了什么内容,理论与实践分析
https://github.com/hehuiyuan/myNote/blob/master/spark/checkpoint-understand.md 直接看原文吧,不想在写一遍了,主要涉及到图片,上传好麻烦的感觉!这里写个开头介绍,详细的看链接里面内容~! 针对spark streaming介绍checkpoint保存了什么? 比如checkpoint会把Checkpoint对象保存
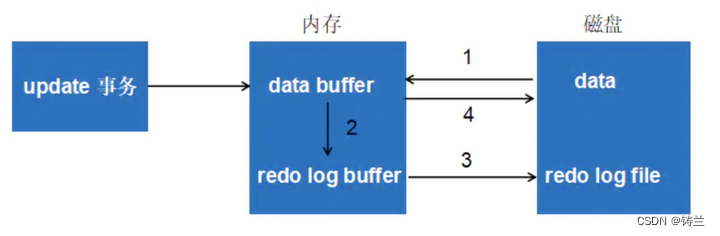
MYSQL部分术语及原理解释(缓冲池、LRU、redo log buffer、WAL、Checkpoint、LSN)
文章目录 一、缓冲池 Buffer Pool二、 LRU List、Free List、Flush List三、 重做日志缓存redo log buffer四、WAL与Checkpoint五、LSN 总结来自《MySQL技术内幕 InnoDB存储引擎》 第二版 一、缓冲池 Buffer Pool InnoDB存储引擎的MySQL是基于磁盘的数据库系统。缓冲池是一片内存区域,在
Flink CheckPoint状态点恢复与savePoint机制
Flink CheckPoint状态点恢复与savePoint机制 2019-01-21 22:40:41 大数据技术与架构 阅读数 203更多 分类专栏: Flink从入门到实践 转载自:https://blog.csdn.net/shenshouniu/article/details/84558874 欢迎加入大数据学习群: **Flink学习视频:**http://ed

大数据面试-20210308:hdfs ,Spark streaming, Flink三者中的checkpoint原理 hdfs checkpoint原理
每达到触发条件,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge (这个过程称为checkpoint),如下图所示: Checkpoint详细步骤 NameNode管理着元数据信息,其中有两类持久化元数据文件:edits操作日志文件和fsimage元数据镜像文件。新的操作日志不会立即与fsima
Spark Checkpoint写操作代码分析
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简
Spark Checkpoint读操作代码分析
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次介绍了RDD的Checkpint写过程(《Spark Checkpoint写操

ORACLE 数据库中v$datafile 与 v#datafile_header中的checkpoint_change#(scn号)的区别
v$datafile 查看该视图中的信息 SELECT FILE#,STATUS,NAME,CHECKPOINT_CHANGE# FROM V$DATAFILE; 这里的scn号是来自于控制文件 v$datafile_header SELECT FILE#,STATUS,NAME,CHECKPOINT_CHANGE# FROM V$DATAFILE_HEADER; 这里的
Flink报错:org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold
org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold 一、问题描述 flink执行任务报错 2022-01-11 15:10:49org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint
Oracle中全量CHECKPOINT和增量CHECKPOINT的区别与作用
全量CHECKPOINT和增量CHECKPOINT对用户都是透明的,而增量CHECKPOINT只不过是将全量CHECKPOINT要写的脏块分时间分批次写到数据文件中而已,此操作可以极大地减少对数据库性能的影响。 全量CHECKPOINT 全量CHECKPOINT是指DBWR进程将脏缓冲区列表中的脏块一次性地写入数据文件中。该操作可以简单地分为2个步骤(这里假设执行全量CHECKPOINT的时间点
Lab Checkpoint 3: the TCP sender
代码主要逻辑: 发送数据:push 函数根据窗口大小和待发送数据的情况,发送数据段(包括处理初始的 SYN、payload 和 FIN)。接收 ACK:receive 函数处理从接收端接收到的 ACK,更新窗口大小、确认号等,并释放已确认的数据段。重传逻辑:tick 函数处理定时器,检查是否需要重传未确认段,并调整重传超时时间。处理特殊情况:包括零窗口探测、处理初始 SYN、处理 FIN 段、调

Flink 原理与实现:Checkpoint
扫码关注公众号免费阅读全文:冰山烈焰的黑板报 众所周知,Flink 采用 Asynchronous Barrier Snapshotting(简称 ABS)算法实现分布式快照的。但是,本文着重介绍 Flink Checkpoint 工作过程,并且用图形化方式描述 Checkpoint 在 Flink 中的实现,Failure Recovery Mechanism(失败恢复机制),以及 Perf
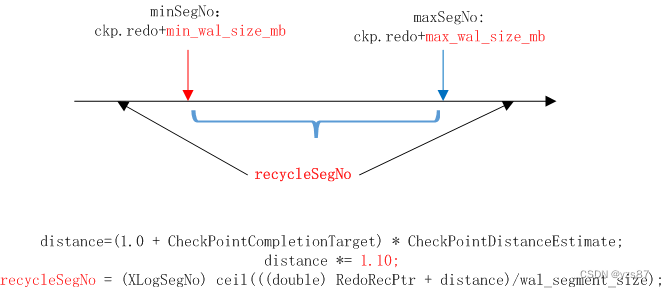
第二章 checkpoint机制 - 原理
1、介绍 每次检查点开始时,都会记录当前最新的WAL日志位置,当数据库恢复时,会从检查点开始回放WAL日志。 checkpoint.redo的位置是执行checkpoint时,当前WAL日志的lsn位置。由于checkpoint并不会影响用户请求,所以如上图所示,checkpoint.redo到Checkpoint WAL之间是checkpoint开始后用户请求产生的WAL日志。所以恢复时

第二章 checkpoint机制 - 介绍
Checkpoint介绍 1、介绍 PostgreSQL基于DRAM+HDD/SSD两层存储架构,所有读写都在DRAM中进行。由于数据写大部分都是随机的,为提高数据库性能,通过写前日志WAL将所有修改都记录到日志中,事务提交时,将日志持久化到磁盘即可,而脏数据页由后台进程异步刷写磁盘,从而将随机写转换成顺序写。 崩溃重启时通过WAL日志将修改回放出来,从而保证数据持久性和一致性,但是如果所有
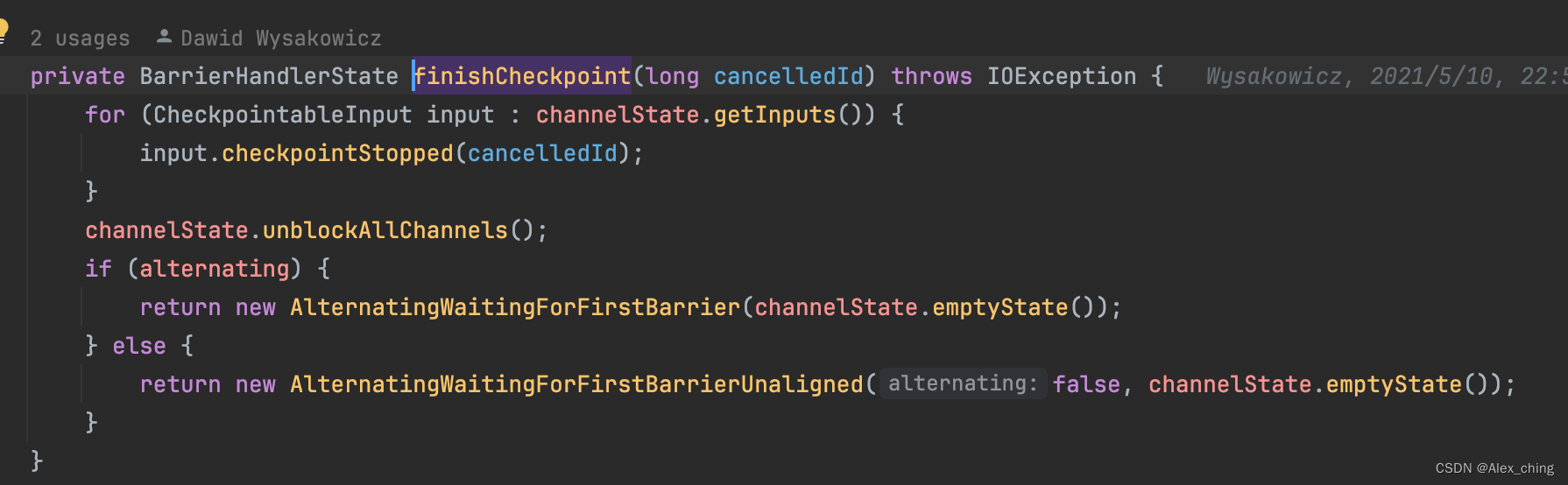
Flink checkpoint 源码分析- Checkpoint snapshot 处理流程
背景 在上一篇博客中我们分析了代码中barrier的是如何流动改的。Flink checkpoint 源码分析- Checkpoint barrier 传递源码分析-CSDN博客 最后跟踪到了代码org.apache.flink.streaming.runtime.io.checkpointing.CheckpointedInputGate#handleEvent 现在我们接着跟踪相应代码
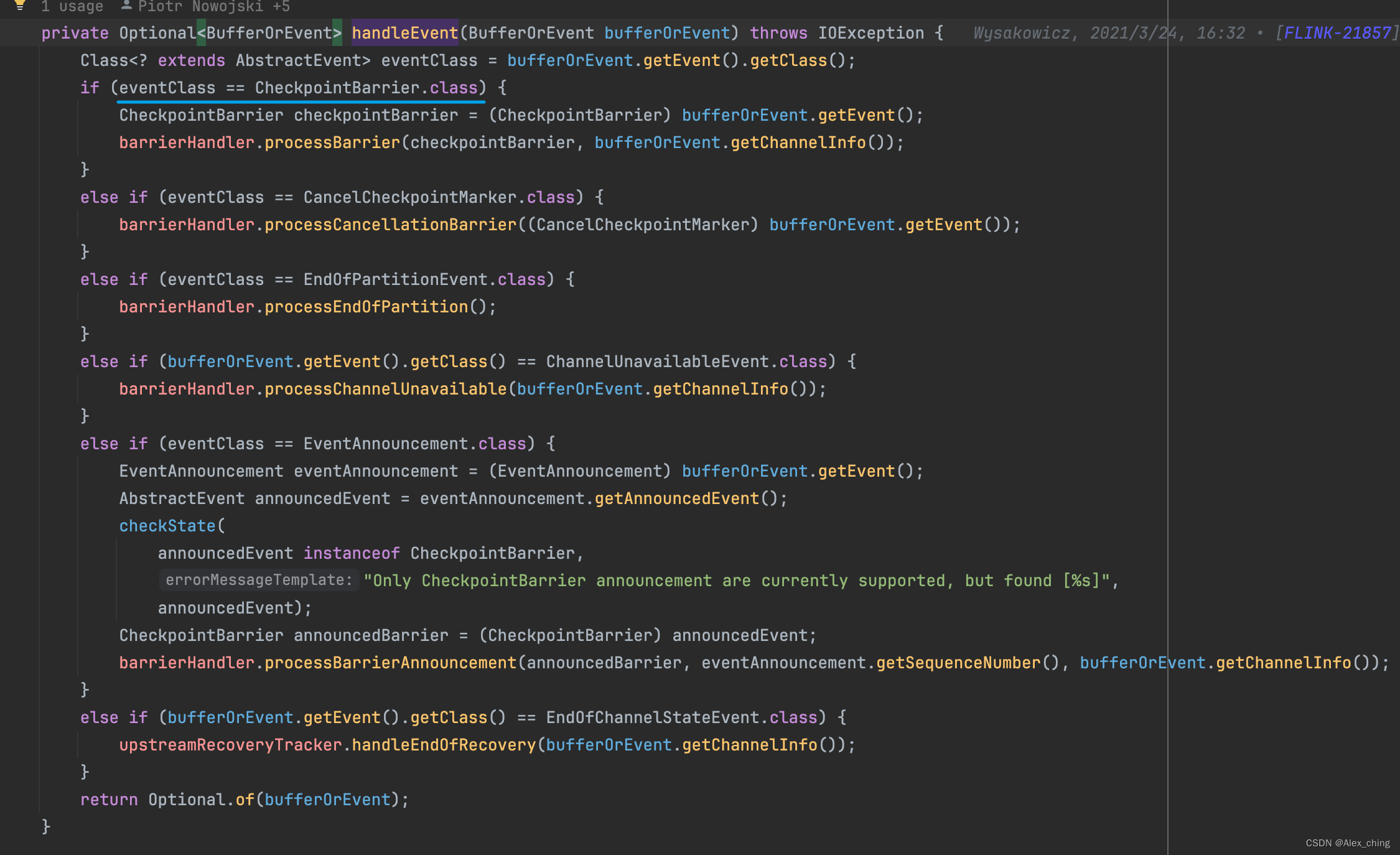
Flink checkpoint 源码分析- Checkpoint barrier 传递源码分析
背景 在上一篇的博客里,大致介绍了flink checkpoint中的触发的大体流程,现在介绍一下触发之后下游的算子是如何做snapshot。 上一篇的文章: Flink checkpoint 源码分析- Flink Checkpoint 触发流程分析-CSDN博客 代码分析 1. 在SubtaskCheckpointCoordinatorImpl中的checkpointState 主要进
Spark_Spark 中 checkpoint 的正确使用方式 以及 与 cache区别
1.Spark性能调优:checkPoint的使用 https://blog.csdn.net/leen0304/article/details/78718346 概述 checkpoint的意思就是建立检查点,类似于快照,例如在spark计算里面,计算流程DAG特别长,服务器需要将整个DAG计算完成得出结果,但是如果在这很长的计算流程中突然中间算出的数据丢失了,spark又会