本文主要是介绍第二章 checkpoint机制 - 原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、介绍
每次检查点开始时,都会记录当前最新的WAL日志位置,当数据库恢复时,会从检查点开始回放WAL日志。

checkpoint.redo的位置是执行checkpoint时,当前WAL日志的lsn位置。由于checkpoint并不会影响用户请求,所以如上图所示,checkpoint.redo到Checkpoint WAL之间是checkpoint开始后用户请求产生的WAL日志。所以恢复时,真正开始恢复的位置是checkpoin.redo的位置。执行完checkpoint后,会产生一个checkpoint日志,并将checkpoint更新到pg_control文件中。
2、checkpoint请求的标签类型
#define CHECKPOINT_IS_SHUTDOWN 0x0001 /* shutdown时请求的检查点 */
#define CHECKPOINT_END_OF_RECOVERY 0x0002 /* WAL恢复完成时请求的检查点*/
/*检查点立即执行,CheckpointWriteDelay函数不会在刷一个脏页后判断进度进行延迟刷写 */
#define CHECKPOINT_IMMEDIATE 0x0004
//即使没有WAL变更也会做这类检查点请求,往往仅想得到最近检查点位置,在关闭或恢复完成时一起用
#define CHECKPOINT_FORCE 0x0008
#define CHECKPOINT_FLUSH_ALL 0x0010 /*刷写所有页,包括不记录日志的表 */
/* These are important to RequestCheckpoint */
/* 发出检查点请求后,RequestCheckpoint函数不会立即退出,而是等待检查点完成 */
#define CHECKPOINT_WAIT 0x0020
#define CHECKPOINT_REQUESTED 0x0040 /* Checkpoint request has been made */
/* These indicate the cause of a checkpoint request */
#define CHECKPOINT_CAUSE_XLOG 0x0080 /* 由WAL消耗引起的检查点*/
#define CHECKPOINT_CAUSE_TIME 0x0100 /* 由距上次检查点时间超时引起的检查点 */3、checkpoint执行位置
Shutdown时,会直接调用检查点函数CreateCheckPoint(非恢复场景下)和CreateRestartPoint(恢复场景下)进行检查点。
非备机模式下,恢复完成时直接调用检查点函数CreateCheckPoint进行检查点。
注意:若备机模式下,promote时向checkpoint进程发起执行检查点消息并等待它完成;若是fast promote,则CreateEndOfRecoveryRecord产生一个XLOG_END_OF_RECOVERY日志,持久化后更新pg_control文件的最小恢复点为此时lsn位置。也就是说快速promote,在打开数据库读写前,不需要创建检查点,只创建一个recovery结束标记,提高了数据库可用时间。关于promote的结束在后续recovery章节中进行介绍。
其他场景,都是向checkpoint进程发起执行检查点的信号,让checkpoint进程去执行。
4、checkpoint进程
Checkpoint进程入口函数为CheckpointerMain,该函数接收checkpoint请求和周期性进行检查点,主要流程如下图所示。
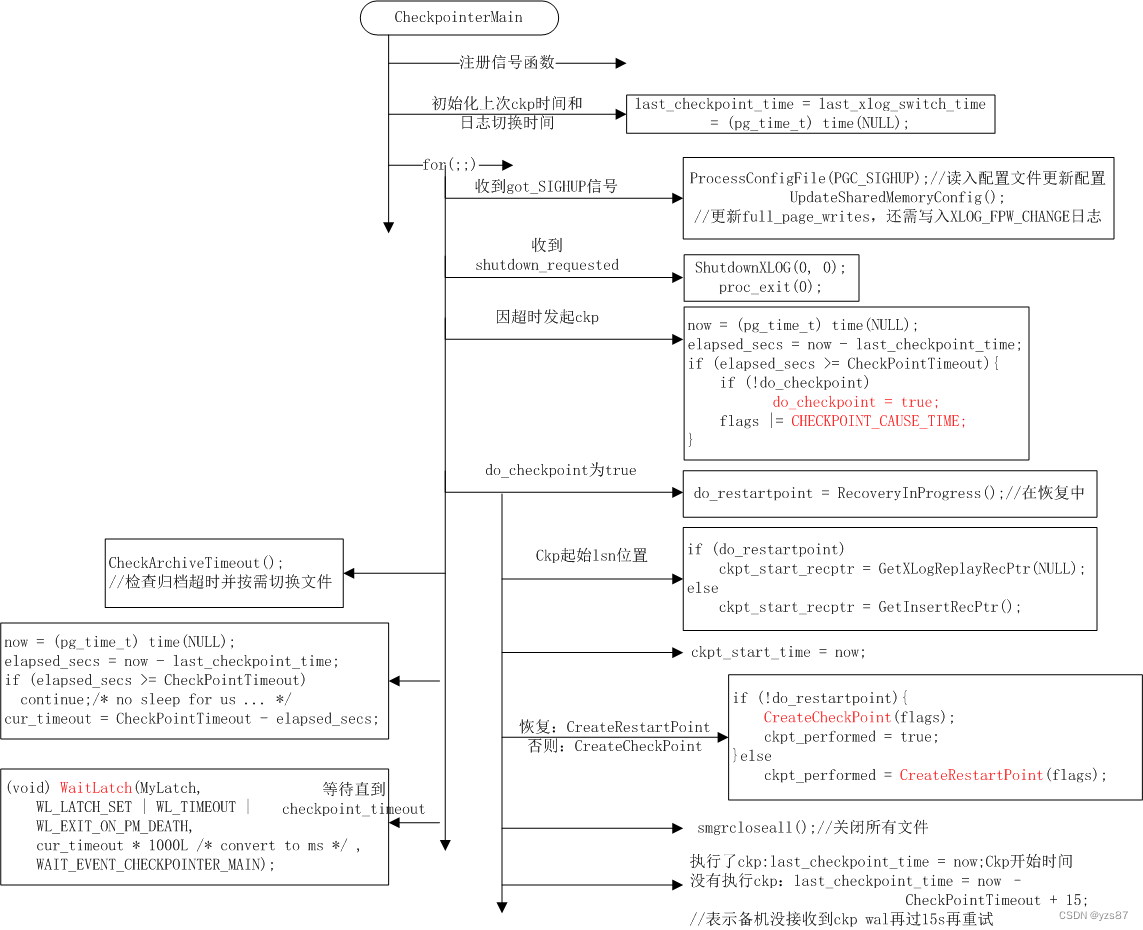
说明:
(1)首先注册信号函数:
SIGHUP:ChkptSigHupHandler函数会将got_SIGHUP置为true,从而读取配置文件
SIGINT:ReqCheckpointHandler函数调用SetLatch(MyLatch);从而立即执行正常的检查点
SIGQUIT:chkpt_quickdie接收postmaster信号进行退出
SIGUSR1:chkpt_sigusr1_handler函数用于唤醒latch
SIGUSR2:ReqShutdownHandler函数使shutdown_requested = true;并唤醒MyLatch等等,从而立即执行shutdown(2)初始化第一次驱动时间
last_checkpoint_time = last_xlog_switch_time = (pg_time_t) time(NULL);(3)进入死循环,处理checkpoint请求:
- 接收到SIGHUP信号,ProcessConfigFile加载postgresql.conf和postgresql.auto.conf文件中配置项;UpdateSharedMemoryConfig函数更新full_page_writes并写一个XLOG_FPW_CHANGE日志,同时更新同步复制的状态(这部分在物理复制章节详述)
- 接收到SIGUSR1信号,即shutdown请求,则调用ShutdownXLOG,会进行强制执行一次检查点,并退出进程。
- 距上次检查点时间超过checkpoint_timeout时间,则发起CHECKPOINT_CAUSE_TIME的检查点(参考第二章checkpoint机制第一节)
- 检查点执行时恢复过程中或者备机执行CreateRestartPoint进行检查点,否则调用CreateCheckPoint执行检查点。恢复时:检查点起始lsn为回放的lsn位置;否则为当前lsn位置。
- 执行完检查点,调用smgrcloseall关闭所有smgr文件
- 执行了检查点,则更新上次检查点时间last_checkpoint_time;若备机在执行时没有接收到checkpoint WAL记录,则等15s后重试
- 若本轮没有执行检查点,或者检查点执行完,则CheckArchiveTimeout检查归档超时并按需切换日志文件;此时距上次检查点时间> checkpoint_timeout,需要立即执行下轮检查点(表示负载有点大,需要频繁检查点),否则等直到checkpoint_timeout再进行下轮检查点。
5、ControlFileData/pg_control文件
typedef struct ControlFileData
{/* 唯一系统标识符,用于保证WAL文件与生成他们的安装版本匹配。这个标识串包含了创建数
* 据库的时间戳及initdb初始时进程号
*/uint64 system_identifier;uint32 pg_control_version; /* PG_CONTROL_VERSION控制文件版本号 *//* 系统表的版本号。PG12的版本为201909212.由三个数字组成X.Y.Z,功能重大变化,X* 才会变化;Y发生变化通常是系统表发生变化;Z变化,系统表不会变化,此时升级* 只需要替换二进制程序。*/uint32 catalog_version_no; /** System status data*/DBState state; /* 系统运行状态,例如shutdown等 */pg_time_t time; /* 最近更新pg_control文件的时间 */XLogRecPtr checkPoint; /* 最近一个检查点的WAL位置 */
//PG11删除了prevCheckPoint
//https://www.postgresql.org/message-id/CANP8%2BjL_OjL7xM3WmY%3DjDzhfSs1Qup26iu0N6Rdav--S0mUrRg%40mail.gmail.comCheckPoint checkPointCopy; /* 最近一次检查点的副本 */XLogRecPtr unloggedLSN; /* 当前fake LSN值, 在unlogged表中使用 *//** 最小恢复点与备库应用WAL日志有关。备机回放一些日志后就会执行检查点,将检查点* 信息记录到控制文件中。当备机回放一些日志后若有一些脏数据刷写到磁盘,会把脏* 页的最新lsn写到最小恢复点。备机异常崩溃启动后,需要恢复到这里才可以提供只读* 服务,从而保证恢复到一个以执行点*/XLogRecPtr minRecoveryPoint; //最小恢复点TimeLineID minRecoveryPointTLI;//最小恢复点的时间线/** 热备份相关的3项:主上执行了select pg_start_backup后,生成backup_label文件* 拷贝主库,包括backup_label文件,备启动时,若发现有backup_label文件,则从* 里面记录的检查点开始恢复,同时备把这个位置记录到控制文件的backupStartPoint中*/XLogRecPtr backupStartPoint;XLogRecPtr backupEndPoint; //备库恢复中一些中间状态bool backupEndRequired;//备库恢复中一些中间状态/** Parameter settings that determine if the WAL can be used for archival* or hot standby.*/int wal_level;bool wal_log_hints;int MaxConnections;int max_worker_processes;int max_wal_senders;int max_prepared_xacts;int max_locks_per_xact;bool track_commit_timestamp;uint32 maxAlign; /* alignment requirement for tuples */double floatFormat; /* constant 1234567.0 */
#define FLOATFORMAT_VALUE 1234567.0/** This data is used to make sure that configuration of this database is* compatible with the backend executable.*/uint32 blcksz; /* 数据块大小*/uint32 relseg_size; /* 大表的每个段文件的块数。一些文件系统上,* 单个文件大小受限,为此将数据分到多个数据文件中存储 * 这个值指定了每个文件最多多少数据块。默认131072个,* 每个8K,则数据文件最大为1GB*/uint32 xlog_blcksz; /* WAL 文件的块大小 */uint32 xlog_seg_size;/* 每个WAL文件的大小 */uint32 nameDataLen; /* 表明、索引名等最大长度*/uint32 indexMaxKeys; /* 一个索引最多多少列,12中默认32个*/uint32 toast_max_chunk_size; /*TOAST表chunk大小 */uint32 loblksize; /* chunk size in pg_largeobject *//* flags indicating pass-by-value status of various types */bool float4ByVal; /* float4类型的参数是传值还是传引用*/bool float8ByVal; /* float8类型的参数是传值还是传引用*//* 数据块checksum版本,如果是0,则数据库没有使用checksum。只有运行initdb -k时才
* 会启用checksum功能
*/uint32 data_checksum_version;/** Random nonce, used in authentication requests that need to proceed* based on values that are cluster-unique, like a SASL exchange that* failed at an early stage.*/char mock_authentication_nonce[MOCK_AUTH_NONCE_LEN];/* CRC of all above ... MUST BE LAST! */pg_crc32c crc;
} ControlFileData;
系统状态包括:
typedef enum DBState
{DB_STARTUP = 0, //数据库正在启动状态DB_SHUTDOWNED, //数据库实例正常关闭DB_SHUTDOWNED_IN_RECOVERY, //备实例正常关闭DB_SHUTDOWNING, //数据库正在停止,先做检查点,开始做检查点时这个状态,做完时shutdownDB_IN_CRASH_RECOVERY, //崩溃恢复时这个状态DB_IN_ARCHIVE_RECOVERY, //备机实例正常启动后就这个状态DB_IN_PRODUCTION //数据库实例正常启动后就这个状态。备机正常启动是in archive recovery
} DBState;6、CHECKPOINT WAL
typedef struct CheckPoint
{XLogRecPtr redo; /* 执行检查点开始时的当前lsn位置 */TimeLineID ThisTimeLineID; /* current TLI */TimeLineID PrevTimeLineID; /* previous TLI, if this record begins a new* timeline (equals ThisTimeLineID otherwise) */bool fullPageWrites; /* current full_page_writes */FullTransactionId nextFullXid; /* next free full transaction ID */Oid nextOid; /* next free OID */MultiXactId nextMulti; /* next free MultiXactId */MultiXactOffset nextMultiOffset; /* next free MultiXact offset */TransactionId oldestXid; /* cluster-wide minimum datfrozenxid */Oid oldestXidDB; /* database with minimum datfrozenxid */MultiXactId oldestMulti; /* cluster-wide minimum datminmxid */Oid oldestMultiDB; /* database with minimum datminmxid */pg_time_t time; /* time stamp of checkpoint */TransactionId oldestCommitTsXid; /* oldest Xid with valid commit timestamp */TransactionId newestCommitTsXid; /* newest Xid with valid commit timestamp *//** Oldest XID still running. This is only needed to initialize hot standby* mode from an online checkpoint, so we only bother calculating this for* online checkpoints and only when wal_level is replica. Otherwise it's* set to InvalidTransactionId.*/TransactionId oldestActiveXid;
} CheckPoint;7、CreateCheckPoint
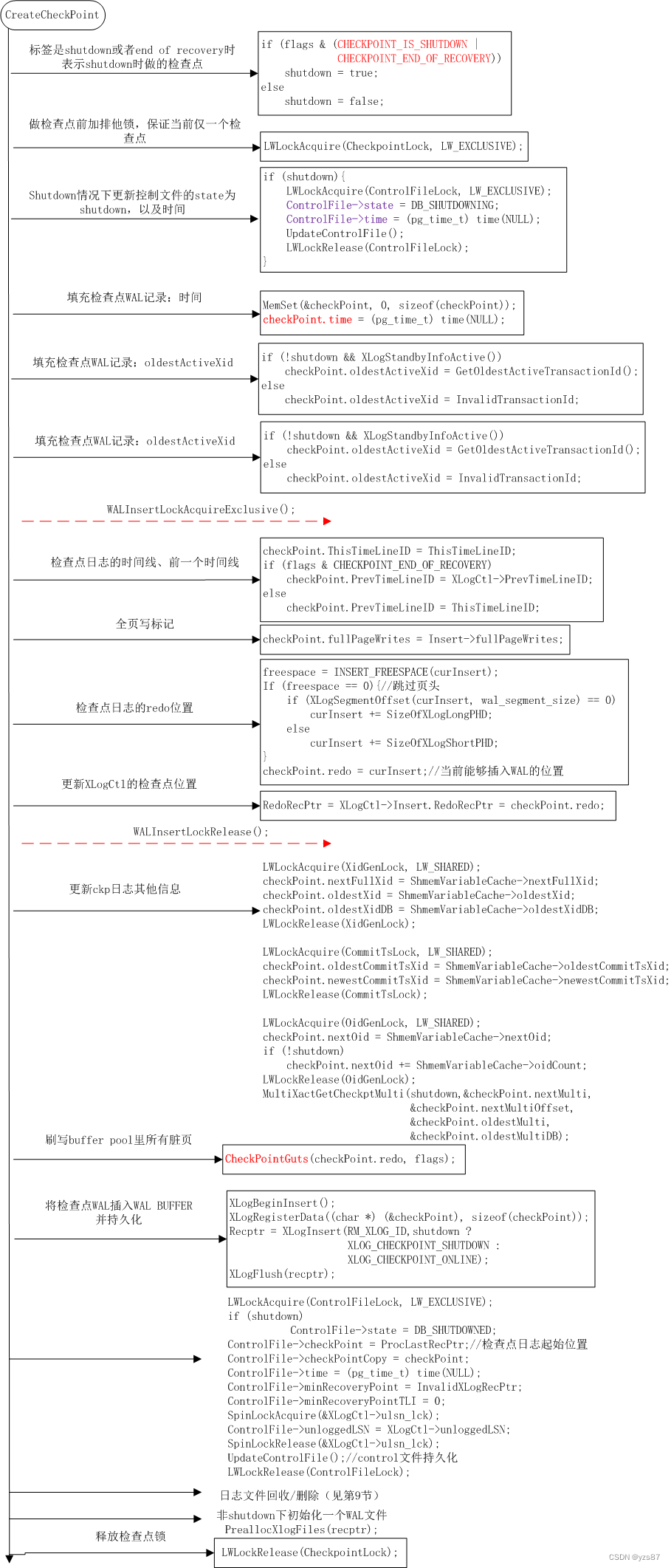
PG执行检查点工作主要由CreateCheckPoint函数完成,该函数会生成checkpoint WAL日志并持久化,同时更新pg_control文件,记录检查点位置。最主要工作是将共享缓冲区中的所有脏页全部刷写磁盘。主要步骤如下图所示:
1)根据传入的flags类型,决定是否是shutdown时进行的检查点
2)执行检查点,需要在CheckpointLock的排他锁内完成,确保当前只能有一个检查点在执行
3)对于shutdown,需要更新控制文件状态为DB_SHUTDOWNING以及其时间,并持久化pg_control文件
4)构建checkpoint的WAL记录body的内容
5)调用CheckPointGuts将共享缓冲区中脏页刷写到磁盘,还包括Clog、事务提交信息等,刷写脏页的函数为CheckPointBuffers->BufferSync。
会首先将共享缓冲区中脏页全部提取出来,并按页号顺序进行排序,然后一页一页的write到磁盘。
每write一个页后都会调用CheckpointWriteDelay函数进行限速,在上节的checkpoint_timeout中详述。
所有脏页刷写完成后,IssuePendingWritebacks将连续的sync请求进行sync
6)脏页刷写完成后,将checkpoint的WAL记录插入WAL BUFFER并持久化到磁盘
7)更新pg_control文件的状态为DB_SHUTDOWNED、更新检查点位置、最小恢复点等信息,然后持久化
8)进行日志文件删除/回收,详见9小节;并进行初始化下一个WAL文件
9)释放检查点锁CheckpointLock
8、CreateRestartPoint
CreateRestartPoint是备机或恢复时执行的检查点。目的时缩短备机重启后恢复时间。注意:备机执行checkpoint后pg_control文件里记录的checkpoint点是从主机传过来WAL里面的checkpoint记录;如果主机很长时间没做checkpoint,那么备机异常宕机重启后恢复仍然会从上次的checkpoint开始恢复,很长时间。
该函数执行的刷写脏页、日志回收/删除和预分配下一个WAL文件部分和CreateCheckPoint函数相同,不同之处在于pg_control文件的更新及它不会产生检查点WAL日志记录。
1)xlog_redo回放CHECKPOINT WAL记录后,将其起始结束位置分别记录到XLogCtl->lastCheckPointRecPtr和XLogCtl->lastCheckPointEndPtr,将WAL记录的body位置记录到XLogCtl->lastCheckPoint,以便备机执行检查点时将主机传来的CHECKPOINT更新到pg_control文件中。
2)shutdown情况下会将pg_control文件的状态更新为DB_SHUTDOWNED_IN_RECOVERY
3)更新minRecoveryPoint及pg_control文件中最小恢复点为XLogCtl->lastCheckPointEndPtr。
9、删除/回收旧的WAL文件
删除/回收旧的WAL文件在两种检查点下,一种是CreateCheckPoint,另一种是CreateRestartPoint,后一种用于恢复时或备机场景下。
1)CreateCheckPoint调用流程
CreateCheckPointif (PriorRedoPtr != InvalidXLogRecPtr)UpdateCheckPointDistanceEstimate(RedoRecPtr - PriorRedoPtr);XLByteToSeg(RedoRecPtr, _logSegNo, wal_segment_size);KeepLogSeg(recptr, &_logSegNo);_logSegNo--;RemoveOldXlogFiles(_logSegNo, RedoRecPtr, recptr);2)CreateRestartPoint调用流程
CreateRestartPointif (PriorRedoPtr != InvalidXLogRecPtr)UpdateCheckPointDistanceEstimate(RedoRecPtr - PriorRedoPtr);XLByteToSeg(RedoRecPtr, _logSegNo, wal_segment_size);receivePtr = GetWalRcvWriteRecPtr(NULL, NULL);replayPtr = GetXLogReplayRecPtr(&replayTLI);endptr = (receivePtr < replayPtr) ? replayPtr : receivePtr;KeepLogSeg(endptr, &_logSegNo);_logSegNo--;RemoveOldXlogFiles(_logSegNo, RedoRecPtr, endptr);9.1 CreateCheckPoint中删除/回收WAL文件
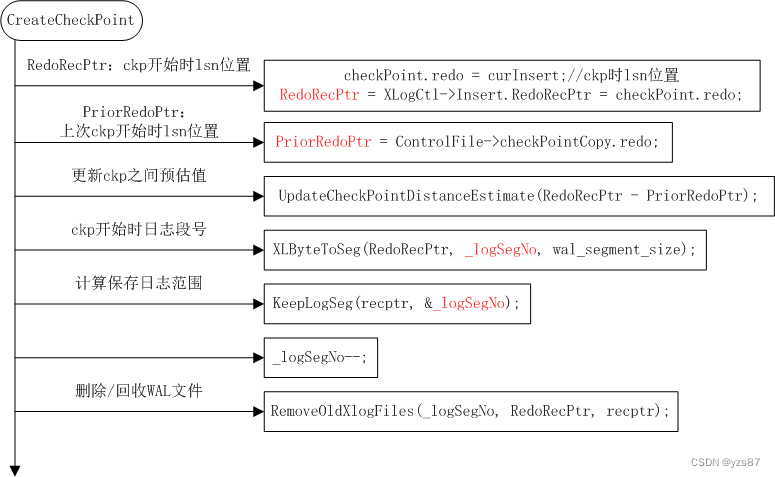
CreateCheckPoint执行完刷写脏页-写CHECKPOINT日志并持久化后对WAL文件进行回收/删除:流程如下图所示
说明:
1)根据两次上次checkpoint开始到这个checkpoint开始产生的日志量计算本次 checkpoint到下次产生的日志量预估值:CheckPointDistanceEstimate
if CheckPointDistanceEstimate < RedoRecPtr-PriorRedoPtr即上次checkpoint开始---本次checkpoint开始产生的日志量CheckPointDistanceEstimate=RedoRecPtr-PriorRedoPtr
elseCheckPointDistanceEstimate=(0.90 * CheckPointDistanceEstimate +
0.10 * (RedoRecPtr-PriorRedoPtr)
即预估值要么为上次检查点到本次检查点产生的日志量,要么为按上面比例计算后的值。2)将检查点开始时lsn位置转换成段号_logSegNo,即此时的日志文件段号
3)通过KeepLogSeg计算保留的日志文件范围:
- recptr为本次checkpoint写入CHECKPOINT的WAL日志后的lsn位置
- 此时的日志文件段号为segno,由recptr转换计算
- 保留日志文件个数由wal_keep_segments和复制槽位置综合计算:
segno = segno - wal_keep_segments;keep=XLogCtl->replicationSlotMinLSN;
XLByteToSeg(keep, slotSegNo, wal_segment_size);//复制槽请求的最小文件
if (slotSegNo < segno)segno = slotSegNo;//wal_keep_segments和复制槽较小需要保留的较小段号
if (segno < *logSegNo)*logSegNo = segno;
//若保留的文件号segno本次执行检查点后的文件号小,则segno之前的文件都需要保留,
//否则保留本次checkpoint之前的都需保留4)_logSegNo--;表示logSegNo之前包括该值的都需要删除/回收,由函数 RemoveOldXlogFiles完成。该函数会遍历pg_wal目录下所有日志文件,与 __logSegNo进行比较(跳过时间线比较),对小于这个的所有日志文件都调用 RemoveXlogFile进行回收/删除(该日志文件需要归档完成)。这里需要注意,若主备环境频繁进行倒换,即频繁promote,则会频繁产生不同时间线的同一个段号日志文件。这个段号日志文件执行检查点后可能由于不比较时间线,所以可能删除不掉,从而导致磁盘空间撑爆。
5)RemoveXlogFile回收/删除文件:
(1)第一次checkpoint,recycleSegNo为本次checkpoint结束后+10,即回收文件后新文件段号最大为本次checkpoint段文件加10后的值。
(2)非第一次checkpoint,recycleSegNo为XLOGfileslop计算:
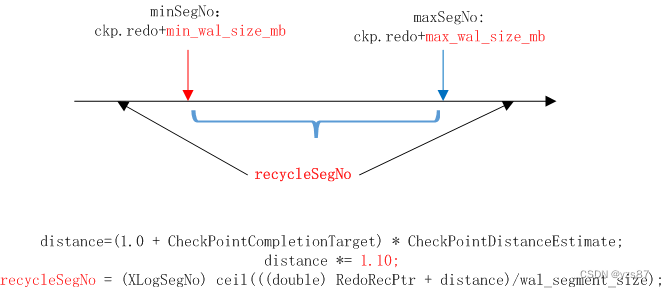
回收量落在(min_wal_size,max_wal_size)范围内,即回收文件后最大段号recycleSegNo在上图蓝色大括号内。也就是说WAL预估值放到后(后面ckp之前产生的日志量)得到的最大段号是recycleSegNo。
- (3)回收一个文件直到最大值是recycleSegNo后,其他的WAL文件都需要删除。回收即文件重命名,删除调用durable_unlink进行删除。
-
9.2 CreateRestartPoint中删除/回收WAL文件
CreateRestartPoint和CreateCheckPoint删除/回收机制类似。只是删除/回收的范围不同。CreateCheckPoint的从本次checkpoint开始的段文件号向前推,保留一定值后进行删除/回收,而CreateRestartPoint从min(接收的WAL位置,回放WAL位置)段文件号向前推,保留一定值后进行删除/回收。
这篇关于第二章 checkpoint机制 - 原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





