cbow专题

word2vec 两个模型,两个加速方法 负采样加速Skip-gram模型 层序Softmax加速CBOW模型 item2vec 双塔模型 (DSSM双塔模型)
推荐领域(DSSM双塔模型): https://www.cnblogs.com/wilson0068/p/12881258.html word2vec word2vec笔记和实现 理解 Word2Vec 之 Skip-Gram 模型 上面这两个链接能让你彻底明白word2vec,不要搞什么公式,看完也是不知所云,也没说到本质. 目前用的比较多的都是Skip-gram模型 Go

Word2Vec之Skip-Gram与CBOW模型
Word2Vec之Skip-Gram与CBOW模型 word2vec是一个开源的nlp工具,它可以将所有的词向量化。至于什么是词向量,最开始是我们熟悉的one-hot编码,但是这种表示方法孤立了每个词,不能表示词之间的关系,当然也有维度过大的原因。后面发展出一种方法,术语是词嵌入。 [1.词嵌入] 词嵌入(Word Embedding)是NL
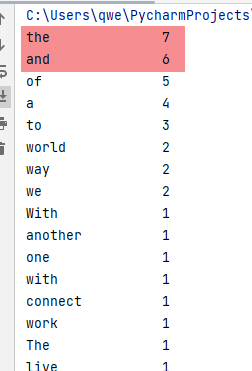
机器学习——CBOW基于矩阵(手动实操)
基于矩阵的CBOW基础算法,其实是负采样的前提算法。 主要是根据 预测准确率为22%左右 说实话。。。我已经很满意了,至少这个东西是可以去预测的,至于预测为什么不正确,我目前猜测主要还是跟词频有关。 在结果中,and和the、a的预测准确率较高,经过打印词频,确实词频高 但其中,预测准确的,也有一些低词频的词汇,所以这个方式目前是可用的。 至于预测效果是否好,主要还是看调参了,比如迭代

cbow 和skip-gram比较
https://blog.csdn.net/weixin_45069761/article/details/106999780?utm_medium=distribute.pc_feed_404.none-task-blog-BlogCommendFromBaidu-1.nonecase&depth_1-utm_source=distribute.pc_feed_404.none-task-blo

word2vec详解(CBOW、SG、hierarchical softmax、negative sampling)
word2vec用来干什么的解释,参见这篇博客一开始也是纯照论文《word2vec Parameter Learning Explained》推公式,到后来理解深了一点,所以后面和前面的公式间有点乱。 python代码:理解不深刻。链接 import argparseimport mathimport structimport sysimport timeimp

word2vec中的CBOW和Skip-gram
word2cev简单介绍 Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇的分布式表示。目前Word2Vec有两种主要模型:Skip-gram和Continuous Bag of Words (
【python、nlp】Word2vec的CBOW模式(文本张量表示)
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇。 假设我们给定的训练语料只有一句话:Hope can set you free(愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-ho

利用Mindspore实现Word2Vec的连续词袋模型(CBOW)和跳词模型(Skip-gram)
前言: 问题:传统的词语的向量表达不能反映词和词之间的相似性和相关语义,且表示维度很长,容易造成维度灾难。(如One-Hot表达一个词,就是初始化一个长度为语料库的向量,并将该词所在位置初始化为1,其他位置均为0,维度很长,且无法反映各个词语之间的关系)因此这种局限导致只能完成一些简单的NLP任务。 措施:于是为了解决这个问题,就不得不提到Word2Vec了,这是NLP领域经
![[CBOW and Skip-gram]论文实现:Efficient Estimation of Word Representations in Vector Space](https://img-blog.csdnimg.cn/129e3cde2d0c49e8ab25cf6cda7bf7b4.png)
[CBOW and Skip-gram]论文实现:Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in Vector Space 一、完整代码二、论文解读2.1 两个框架2.1.1 CBOW2.1.2 Skip-gram 2.2 两种加速2.2.1 Hierarchical Softmax2.2.2 Negative Sampling 三、过程实现3.1 Huffman 树 构建3.1.1 CBO

机器学习——CBOW负采样(未开始)
刚从前一个坑里,勉强爬出来,又掘开另一坑 看了很多文章+B站up主。。。糊里糊涂 但是我发觉,对于不理解的东西,要多看不同up主写的知识分享 书读百遍,其意自现,我是不相信的,容易钻牛角尖 但是,可以多看看一千个哈姆雷特的想法,想法积累多了,一定有那么一刻,让人灵光乍现!!! 拍脑顿悟:原来如此! 给我顿悟的是CSDN的一篇文章Word2Vec详解-公式推导以及代码 CSDN啊,听大神一席话,

cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结
生成词向量的方法 以前大致有两种方法: ①是Matrix Factorization Method,主要代表是SVD Based的LSA等方法,核心是对共现矩阵(co-occurence)进行SVD(奇异值)分解,得到词向量。 ②是Iteration Based Method(Shallow window-based),主要代表是上节课讲到的Skip-Gram和CBOW。核心是概率,通过设置

Word2Vec (Part 2): NLP With Deep Learning with Tensorflow (CBOW)
Tensorflow上其实本来已经有word2vec的代码了,但是我第一次看的时候也是看得云里雾里,还是看得不太明白。并且官方文档中只有word2vec的skip-gram实现,所以google了一下,发现了这两篇好文章,好像也没看到中文版本,本着学习的态度,决定翻译一下,一来加深一下自己的理解,二来也可以方便一下别人。第一次翻译,如有不当,欢迎指出。 原文章地址: Wor

Word2vec用CBOW模型的keras代码详解
Word2vec的原理和code在这篇文本处理算法汇总文章里有总结 代码来源: Word2vec用CBOW模型的keras代码 分析目的: 用于理解word2vec模型的输入、输出,及具体用法。 总结:这个模型的原理在于训练2个矩阵,及一个偏置,将一个word输入第一个矩阵emedding_1,这个矩阵将经过one-hot编码的一个及多个中心word,从训练集中出现的总词数(nb_word)维

中文词向量:使用pytorch实现CBOW
整个项目和使用说明地址:链接:https://pan.baidu.com/s/1my30wyqOk_WJD0jjM7u4TQ 提取码:xxe0 关于词向量的理论基础和基础模型都看我之前的文章。里面带有论文和其他博客链接。可以系统学习关于词向量的知识。 之前已