本文主要是介绍机器学习——CBOW基于矩阵(手动实操),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于矩阵的CBOW基础算法,其实是负采样的前提算法。
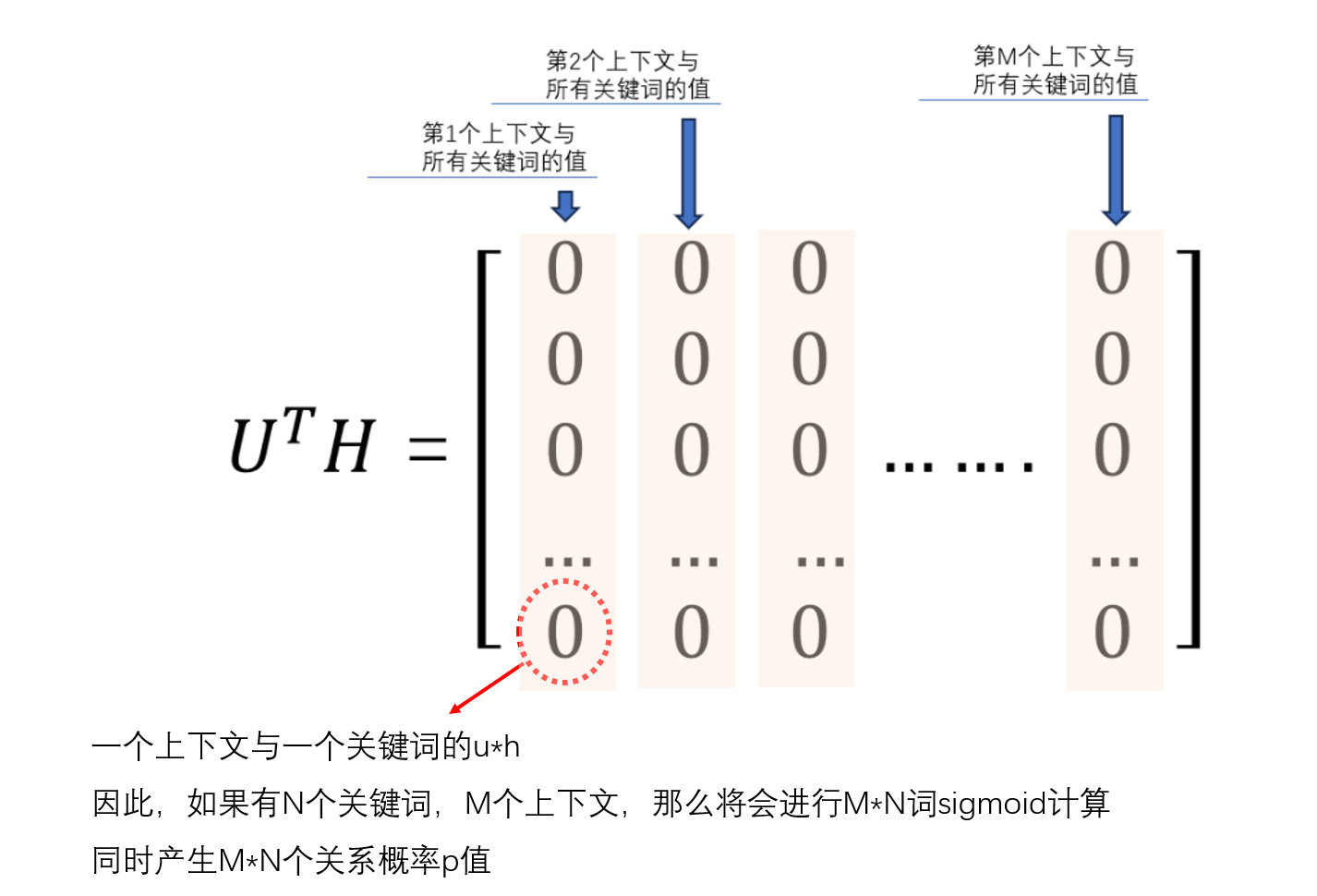
主要是根据
预测准确率为22%左右
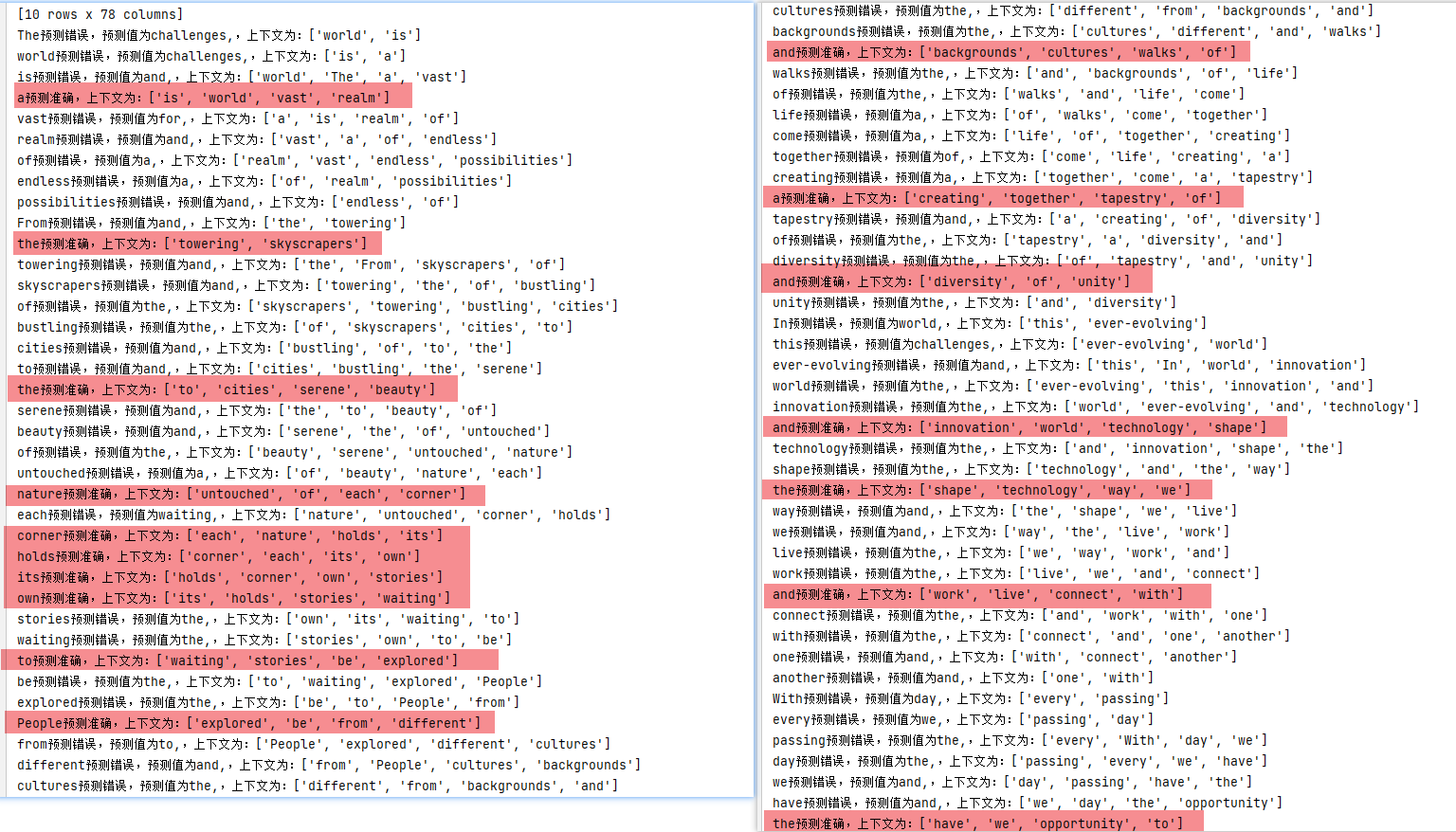
说实话。。。我已经很满意了,至少这个东西是可以去预测的,至于预测为什么不正确,我目前猜测主要还是跟词频有关。
在结果中,and和the、a的预测准确率较高,经过打印词频,确实词频高
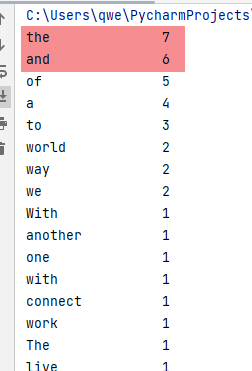
但其中,预测准确的,也有一些低词频的词汇,所以这个方式目前是可用的。
至于预测效果是否好,主要还是看调参了,比如迭代次数、比如学习率等等。
但这不是我重点考虑的。
我只要模型流程是正确的,能跑的通。
import math
import numpy as np
from docx import Document
import re
import pandas as pd
import random
random.seed(0)
pd.options.display.max_rows = None
"""
需要提前设置的参数:doc_path语料的word文档、η学习率、词向量的维度W_columns、iterate_times迭代次数、context_word_num单个上下文的词数量
+++++++ 【W词向量的所有初始值、θ霍夫曼树非叶子节点上的权重参数】:这两个关键参数在后续用正态分布随机树来进行初始化 ++++
"""
doc_path = r"simple_word.docx"
η = 0.01
W_columns = 10
iterate_times = 50
context_word_num = 4# 获取语料库C+统计无重复单词的词典D
doc = Document(doc_path)
C_list = []
all_text = ''
for i in doc.paragraphs:if len(i.text) != 0:para = [x for x in re.split(' |!|\?|\.|。|,|,|\(|\)', i.text) if x]C_list.append(para)all_text = all_text + i.text
words_org = [x for x in re.split(' |!|\?|\.|。|,|,|\(|\)', all_text) if x]
# 统计每个单词的词频,word_count是series数据类型
word_count = pd.value_counts(words_org)
print(word_count)
raise Exception
"""词典D转独热编码"""
D_list = set(words_org)
N = len(D_list)
D_onehot = {}
for index, value in enumerate(D_list):temp = [0] * Ntemp[index] = 1D_onehot[value] = tempdel temp
# 最终词典D的独热编码为D_df
D_df = pd.DataFrame(D_onehot)"""初始化词向量矩阵W:W_columns个维度特征"""
# 这意味着后续的中间向量h和关键词参数向量u,都是用3个值表示,如 h=[1,10,20]
W_dict = {}
for index, word in enumerate(D_list):W_dict[word] = [random.random() for i in range(W_columns)]
# 最终词向量用W_df表示
W_df = pd.DataFrame(W_dict)
print(f"初始的词向量W为")
print(W_df)"""初始化关键词的参数向量u:u的维度特征个数,跟w、h保持一致"""
u_dict = {}
for index, word in enumerate(D_list):u_dict[word] = [1 for i in range(W_columns)]
# 最终关键词参数向量用u_df表示
u_df = pd.DataFrame(u_dict)
print(f"初始的关键词参数向量u为")
print(u_df)# 每一个u的迭代,都需要所有上下文中间向量h的累加,每一个w的迭代,都需要所有u的累加
# 先迭代u,u迭代完变为一个新的u_new后,再用所有的u_new去依次迭代所有的w。"""第3阶段反向传播:把所有上下文存进列表里"""
# 由于我们要迭代很多次,所以每次都重新选取上下文,会非常耗时
# 因此,不如一次性,把所有的上下文都选取后,放进一个列表里边
# 这样,以后无论迭代多少次,上下文都是一样的,不需要重复选取
c = context_word_num//2
y_and_context_list = []
y_h_dict = {}
for sentence in C_list:for index, word in enumerate(sentence):"""获取单个上下文"""y = wordcontext = []if index-2>=0:context.append(sentence[index-1])if index-2>=0:context.append(sentence[index-2])if index+1<len(sentence):context.append(sentence[index+1])if index+2<len(sentence):context.append(sentence[index+2])"""计算单个上下文的中间向量h"""h = list(W_df[context].sum(axis=1))y_and_context = (y, h,context)y_h_dict[y]=list(h)y_and_context_list.append(y_and_context)
"""y和h有个对应的dataframe表:每个关键词都有一个对应的中间向量h"""
y_h_df = pd.DataFrame(y_h_dict)def sigmoid(x, y):sig = np.matmul(x, y)try:result = 1 / (1.0 + math.exp(-sig))except OverflowError:result = 1 / (1.0 + math.exp(700))return result"""反向传播:根据每个上下文和对应的待预测单词y,去迭代u和w"""
for i in range(iterate_times):print(f"第{i + 1}次迭代")h_temp = 0.0"""所有关键词的参数向量u的迭代"""for y_and_context in y_and_context_list:y, h,context = y_and_contextu_old = u_df[y]u_temp = 0.0for y_index in y_h_df:if y_index == y:l_word = 1else:l_word = 0h_row = y_h_df[y_index]"""u的迭代公式涉及所有h的累加计算"""u_temp += η*(l_word-sigmoid(u_old,h_row))*h_rowu_new = u_old + u_tempu_df[y] = u_new"""所有词向量w的迭代"""for y_and_context in y_and_context_list:y, h,context = y_and_contextw_temp = 0.0for y_index in u_df:if y_index == y:l_word = 1else:l_word = 0u_row = u_df[y_index]"""w的迭代公式涉及所有u的累加计算"""w_temp += η*(l_word-sigmoid(u_row,h))*u_rowfor word in context:W_df[word] = W_df[word] + w_temp
print(f"迭代后的词向量W为")
print(W_df)"""迭代后预测,预测的方式:每个h与所有的u分别进行乘积后,再softmax,看哪个值比较大,就预测为哪个关键词"""
def get_mom(a,b_df): # 计算softmax的分母部分mom = 0for b in b_df:temp = np.matmul(a,b_df[b])mom += math.exp(temp)return momdef softmax(a,b,b_df): # 计算最终的softmax值mom = get_mom(a,b_df)son = math.exp(np.matmul(a,b))result = son/momreturn result
"""预测关键词:h和所有的u分别计算出softmax值,其中softmax值最大的为对应的预测关键词"""
def predict(a,b_df): # 预测关键词y_predict = {'max_softmax':0,'y_index':None}for y_index in b_df:softmax_now = softmax(a, b_df[y_index], b_df)if softmax_now>y_predict['max_softmax']:y_predict['max_softmax'] = softmax_nowy_predict['y_index'] = y_indexif y_predict['y_index'] == None:print("无法预测,报错")else:return y_predict['y_index']pre_result = []
for y_and_context in y_and_context_list:y, h, context = y_and_contexth = list(W_df[context].sum(axis=1))y_pre = predict(h,u_df)if y_pre == y:print(f"{y}预测准确,上下文为:{context}")pre_result.append(1)else:print(f"{y}预测错误,预测值为{y_pre},,上下文为:{context}")pre_result.append(0)
print(f"预测准确率为:{sum(pre_result)/len(pre_result)*100}%")这篇关于机器学习——CBOW基于矩阵(手动实操)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







