bptt专题

GNN-2008:Original GNN【消息传递(前向传播):聚合函数+更新函数+输出函数】【核心:不动点理论】【梯度优化:用Almeida-Pineda算法,而不是用BPTT(反向传播)算法】
GNN-2008:Original GNN【消息传递(前向传播):聚合函数+更新函数+输出函数】【核心:不动点理论】【梯度优化:用Almeida-Pineda算法,而不是用BPTT(反向传播)算法】 《原始论文:A new model for learning in graph domains-2005》 《原始论文:The Graph Neural Network Model-2008》 一

深度学习100问27:什么是截断的BPTT
嘿,你知道截断的 BPTT 是什么嘛?想象一下,你有一个超级长的故事要讲,一口气从头讲到尾可太难啦,而且很容易把自己绕晕。这时候呢,截断的 BPTT 就像把这个长故事分成一小段一小段来讲。 在循环神经网络训练那些长长的序列数据的时候,如果直接像个“愣头青”一样用传统方法,那计算量会大得吓人,还可能出现梯度消失或者爆炸的情况,就像烟花放一半突然熄火或者炸得不可收拾。 截断的 BPTT 呢,先
BPTT算法详解:深入探究循环神经网络(RNN)中的梯度计算【原理理解】
引言 在深度学习领域中,我们经常处理的是独立同分布(i.i.d)的数据,比如图像分类、文本生成等任务,其中每个样本之间相互独立。然而,在现实生活中,许多数据具有时序结构,例如语言模型中的单词序列、股票价格随时间的变化、视频中的帧等。对于这类具有时序关系的数据,传统的深度学习模型可能无法很好地捕捉到其内在的 时间相关性 。为了解决这一问题,循环神经网络(Recurrent Neural Netwo
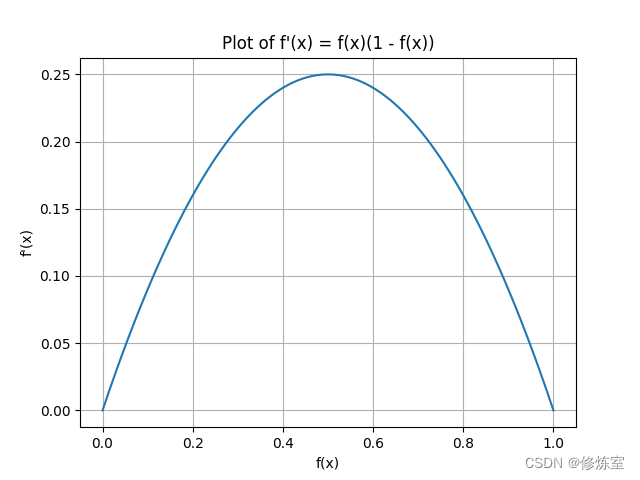
通俗易懂的RNN总结(包含LSTM/GRU/BPTT等)
1、RNN介绍: RNN的基本想法是如何采用序列信息。在传统神经网络中我们假设所有的输入和输出都是相互独立的,但对于很多任务这样的假设并不合适。如果你想预测一个句子的下一个单词,的则需要知道之前的words包括哪些。 RNN被称为循环因为它们对句子的每个元素都执行相同的任务,输出依赖于之前的计算;另一个理解RNN的方法是假设他们用记忆能够获取之前计算过的信息。理论上RNN能够利用任意长的句子,
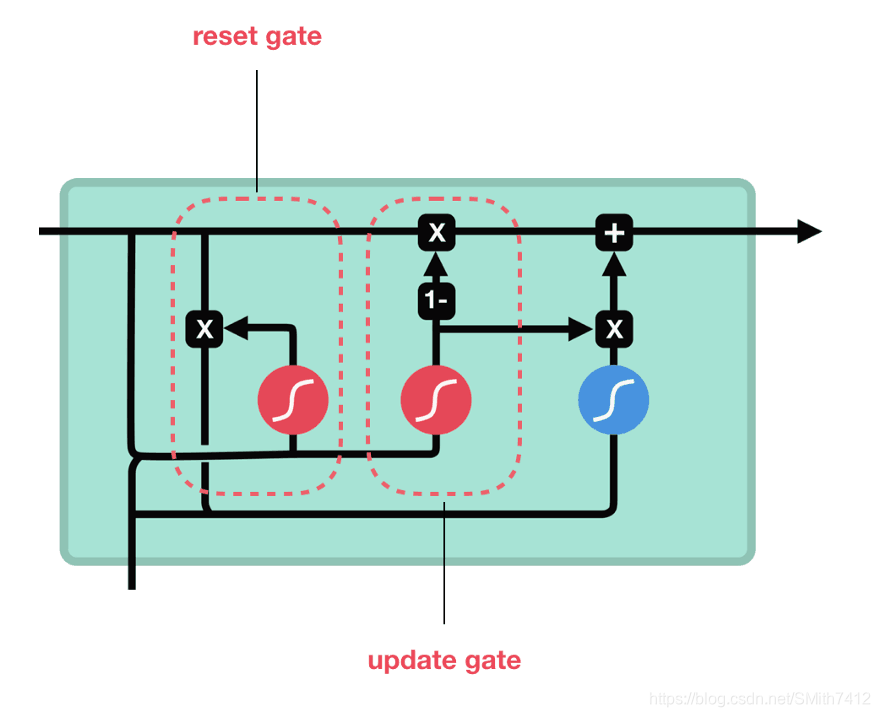
【23-24 秋学期】NNDL 作业10 BPTT
习题6-1P 推导RNN反向传播算法BPTT. 习题6-2 推导公式(6.40)和公式(6.41)中的梯度. 习题6-3 当使用公式(6.50)作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法. 习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试. 代码实现 REF:L5W1作业1 手把手实现

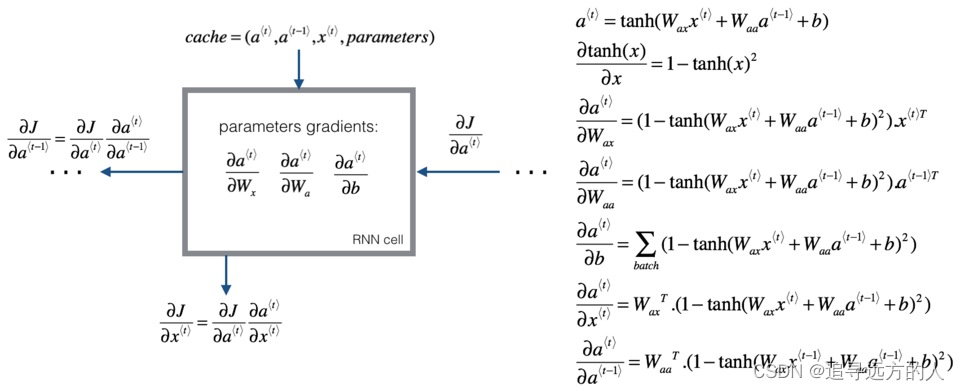
RNN基于时间的反向传播算法BPTT(Back Propagation Trough Time)梯度消失与梯度爆炸
日萌社 人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新) 将RNN展开之后,前向传播(Forward Propagation)就是依次按照时间的顺序计算一次就好了,反向传播(Back Propagation)就是从最后一个时间将累积的残差传递回来即可,这与普通的神经网络训练本质上是相似的。
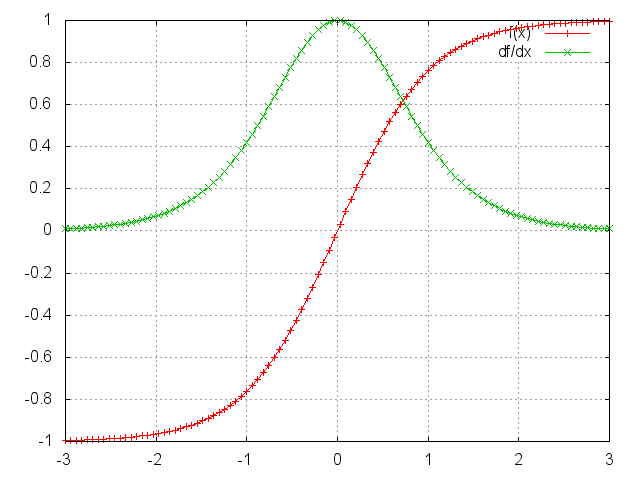
循环神经网络教程第三部分-BPTT和梯度消失
作者:徐志强 链接:https://zhuanlan.zhihu.com/p/22338087 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 本篇是 循环神经网络教程的第三部分。 在前一篇教程中,我们从头开始实现了RNN,但并没有深入到BPTT如何计算梯度的细节中去。在本部分,我们将对BPTT做一个简短的介绍,并解释它和传统的反向传播有什么不同。然后,