本文主要是介绍循环神经网络教程第三部分-BPTT和梯度消失,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链接:https://zhuanlan.zhihu.com/p/22338087
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本篇是 循环神经网络教程的第三部分。
在前一篇教程中,我们从头开始实现了RNN,但并没有深入到BPTT如何计算梯度的细节中去。在本部分,我们将对BPTT做一个简短的介绍,并解释它和传统的反向传播有什么不同。然后,我们会试着去理解梯度消失问题,它导致了LSTM和GRU这两个目前在NLP中最流行、最强大的模型的发明。梯度消失问题最初由Sepp Hochreiter在1991年发现,在最近由于深度结构的使用又引起了人们的关注。
为了完全理解本部分的内容,我建议先熟悉一下偏微分和基本的反向传播是怎么工作的。如果你不熟悉的话,在这里,这里和这里可以找打很好的资料,它们的难度逐级递增。
随时间的反向传播(BPTT)
让我们先迅速回忆一下RNN的基本公式,注意到这里在符号上稍稍做了改变(变成
),这只是为了和我参考的一些资料保持一致。
同样把损失值定义为交叉熵损失,如下:
这里,表示时刻
正确的词,
是我们的预测。通常我们会把整个句子作为一个训练样本,所以总体错误是每一时刻的错误的加和。
我们的目标是计算错误值相对于参数的梯度以及用随机梯度下降学习好的参数。就像我们要把所有错误相加一样,我们同样会把每一时刻针对每个训练样本的梯度值相加:
。
为了计算梯度,我们使用链式求导法则,主要是用反向传播算法往后传播错误。下文使用作为例子,主要是为了描述方便。
上面,
是向量的外积。如果你不理解上面的公式,不要担心,我在这里跳过了一些步骤,你可以自己尝试来计算这些梯度值。这里我想说明的一点是梯度值只依赖于当前时刻的结果
。根据这些,计算
的梯度就只剩下简单的矩阵乘积了。
但是对于梯度情况就不同了,我们可以像上面一样写出链式法则。
注意到这里的依赖于
,
依赖于
和
,等等。所以为了得到
的梯度,我们不能将
看作常量。我们需要再次使用链式法则,得到的结果如下:
我们把每一时刻得到的梯度值加和,换句话说,在计算输出的每一步中都使用了。我们需要通过将
时刻的梯度反向传播至
时刻。
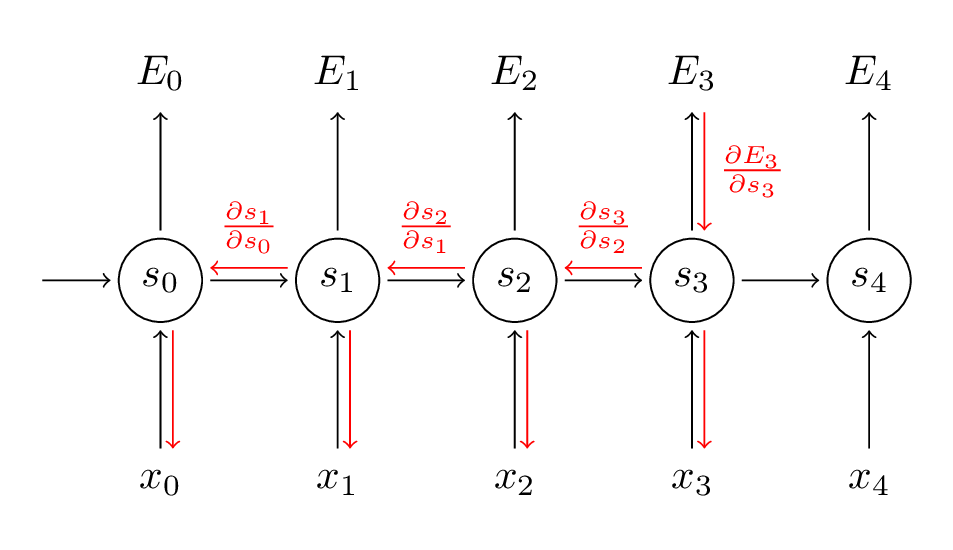
注意到这里和我们在深度前向神经网络中使用的标准反向传播算法是一致的,关键不同在于我们把每一时刻针对的不同梯度做了加和。在传统神经网络中,不需要在层之间共享参数,就不需要做任何加和。在我看来,BPTT是应用于展开的RNN上的标准反向传播的另一个名字。就像反向传播一样,你也可以定义一个反向传递的delta向量,例如,
,其中
。
在代码中,BPTT的一个简易实现如下:
def bptt(self, x, y):T = len(y)# Perform forward propagationo, s = self.forward_propagation(x)# We accumulate the gradients in these variablesdLdU = np.zeros(self.U.shape)dLdV = np.zeros(self.V.shape)dLdW = np.zeros(self.W.shape)delta_o = odelta_o[np.arange(len(y)), y] -= 1.# For each output backwards...for t in np.arange(T)[::-1]:dLdV += np.outer(delta_o[t], s[t].T)# Initial delta calculation: dL/dzdelta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))# Backpropagation through time (for at most self.bptt_truncate steps)for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)# Add to gradients at each previous stepdLdW += np.outer(delta_t, s[bptt_step-1]) dLdU[:,x[bptt_step]] += delta_t# Update delta for next step dL/dz at t-1delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)return [dLdU, dLdV, dLdW]
这会让你明白为什么标准RNN很难训练:序列会变得很长,可能有20个词或更多,因而就需要反向传播很多层。实践中,很多人会把发现传播截断至几步。
梯度消失问题
在教程前一部分,我提到RNN很难学到长范围的依赖——相隔几步的词之间的交互。这是有问题的因为英语中句子的意思通常由相距不是很近的词来决定:“The man who wore a wig on his head went inside”。这个句子讲的是一个男人走了进去,而不是关于假发。但是普通的RNN不可能捕捉这样的信息。要理解为什么,让我们先仔细看一下上面计算的梯度:
注意到也需要使用链式法则,例如,
。注意到因为我们是用向量函数对向量求导数,结果是一个矩阵(称为Jacobian Matrix),矩阵元素是每个点的导数。我们可以把上面的梯度重写成:
可以证明上面的Jacobian矩阵的二范数(可以认为是一个绝对值)的上界是1。这很直观,因为激活函数把所有制映射到-1和1之间,导数值得界限也是1:
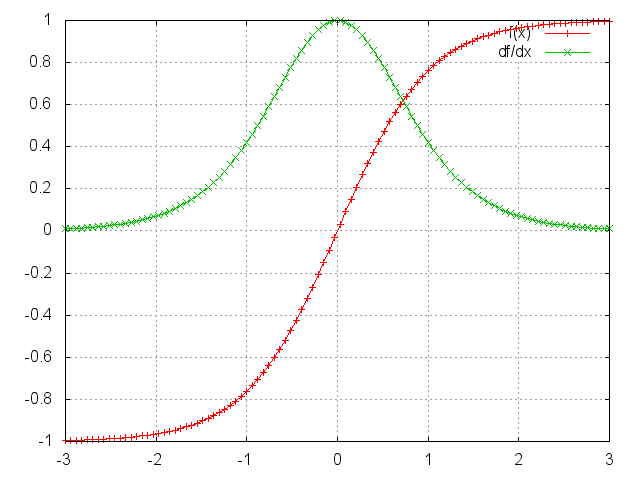
你可以看到tanh和sigmoid函数在两端的梯度值都为0,接近于平行线。当这种情况出现时,我们就认为相应的神经元饱和了。它们的梯度为0使得前面层的梯度也为0。矩阵中存在比较小的值,多个矩阵相乘会使梯度值以指数级速度下降,最终在几步后完全消失。比较远的时刻的梯度值为0,这些时刻的状态对学习过程没有帮助,导致你无法学习到长距离依赖。消失梯度问题不仅出现在RNN中,同样也出现在深度前向神经网中。只是RNN通常比较深(例子中深度和句子长度一致),使得这个问题更加普遍。
很容易想到,依赖于我们的激活函数和网络参数,如果Jacobian矩阵中的值太大,会产生梯度爆炸而不是梯度消失问题。梯度消失比梯度爆炸受到了更多的关注有两方面的原因。其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失出现的时候不那么明显而且不好处理。
幸运的是,已经有一些方法解决了梯度消失问题。合适的初始化矩阵W可以减小梯度消失效应,正则化也能起作用。更好的方法是选择ReLU而不是sigmoid和tanh作为激活函数。ReLU的导数是常数值0或1,所以不可能会引起梯度消失。更通用的方案时采用长短项记忆(LSTM)或门限递归单元(GRU)结构。LSTM在1997年第一次提出,可能是目前在NLP上最普遍采用的模型。GRU,2014年第一次提出,是LSTM的简化版本。这两种RNN结构都是为了处理梯度消失问题而设计的,可以有效地学习到长距离依赖,我们会在教程的下一部分进行介绍。
PS:前两篇教程中的图都没有显示出来,目前不知道是咋回事,希望这一篇能显示出来。
这篇关于循环神经网络教程第三部分-BPTT和梯度消失的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




