bow专题

BOW模;型CountVectorizer模型;tfidf模型;
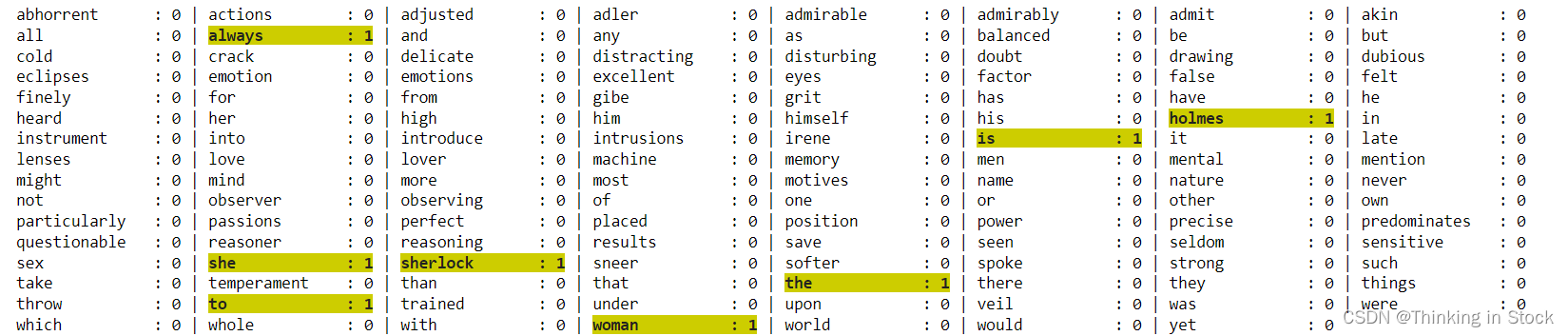
自然语言入门 一、BOW模型:使用一组无序的单词来表达一段文字或者一个文档,并且每个单词的出现都是独立的。在表示文档时是二值(出现1,不出现0); eg: Doc1:practice makes perfect perfect. Doc2:nobody is perfect. Doc1和Doc2作为语料库:词有(practice makes perfect nobody is) Doc
【大语言模型】基础:如何处理文章,向量化与BoW
词袋模型(BoW)是自然语言处理(NLP)和机器学习中一种简单而广泛使用的文本表示方法。它将文本文档转换为数值特征向量,使得可以对文本数据执行数学和统计操作。词袋模型将文本视为无序的单词集合(或“袋”),忽略语法和单词顺序但保留重数。 我们研究两种类型的词袋向量: 原始计数:实际计算文本中每个单词出现的次数TF-IDF:调整原始计数,以偏好那些在少数文档中大量出现的单词,而不是那些在所有文档中

机器学习代码整理pLSA、BoW、DBN、DNN
丕子同学整理点自己的代码:Lp_LR、Pagerank(MapReduce)、pLSA、BoW、DBN、DNN 听说如果你在github等代码托管平台上有自己的开源工具,可以写进简历,是一个加分~ 那就整理整理之前的一些代码片段。 PG_ROC_PR_R:R语言绘制ROC和PR曲线。R PG_PageRank:mapreduce版本的pagerank计算方法。Shell

fog bow 雾虹
雾虹(fogbow),俗称白色彩虹,这是一种与彩虹相似的天气现象,太阳光经由水分子反射和折射后形成。它的成因和彩虹相似,都是阳光被水滴反射后的产物,雾虹是由更小的水滴从更广的范围反射太阳光形成的。 更多参考 http://www.philiplaven.com/p2b.html

【OpenCV】基于BoW词袋模型/HoG+SIFT特征提取的图像检索系统
功能介绍 图片检索结果 Image Retrieval精确度和召回率计算调试数据记录(处理效率、特征值、相似度等) 总体思路 输入路径预处理样本库、提取特征值(HoG/SIFT/LBP/Haar-like)读取待检索图片、提取特征值计算TF/IDF词频(Term Frequency/Inverse Document Frequency)遍历样本库、计算相似度排序、取最相似的前topN个结果重

Bag-of-Words(BoW)
Bag-of-Words(BoW)模型是一种用于自然语言处理(NLP)的基本文本表示方法。它的核心思想是将文本数据转化为一个"词袋",忽略文本中词语的顺序和语法,只关注词汇的出现与否。BoW模型通常包括以下步骤: 构建词汇表:首先,将文本数据中出现的所有不重复的词汇收集到一个词汇表中。这些词汇构成了BoW模型的基础。 创建向量表示:对于每个文本样本,创建一个与词汇表等长的向量。向量中的每个元

【自然语言处理】BOW和TF-IDF详解
BOW 和 TF-IDF 详解 机器无法处理原始形式的文本数据。我们需要将文本分解成一种易于机器阅读的数字格式(自然语言处理背后的理念!)。BOW 和 TF-IDF 都是帮助我们将文本句子转换为向量的技术。 我将用一个流行的例子来解释本文中的 Bag-of-Words(BOW)和 TF-IDF。 我们都喜欢看电影。在我决定看一部电影之前,我总是先看它的影评。我知道你们很多人也这么做!所以
BOW-FisherVector-VLAD
BOW-FisherVector-VLAD ---------reference---------------------- 1. google: a test retrieval approach to object matching in videos 2. 3. aggregating local des
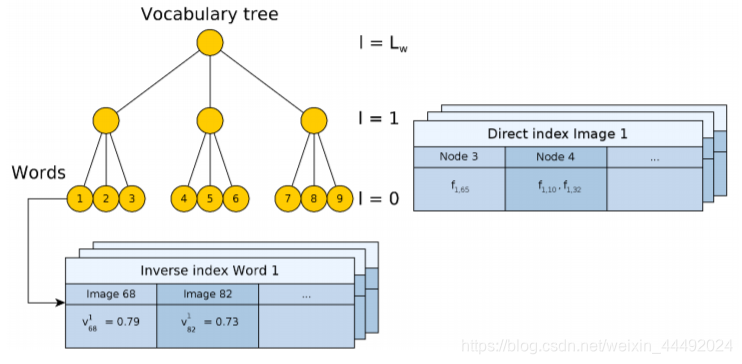
SLAM BOW词袋重定位
visual bag of words 词袋用于SLAM重定位 DBOWBinary featuresImage databaseLoop detectionA. Data base queryB. Matching groupingC. Temporal consistencyD. Efficient geometrical consistency 结果分析 ORBSLAM2 中的Relo