bioinformatics专题

PMAT安装及使用(Bioinformatics工具-021)
01 背景 PMAT 是一个高效的组装工具包,用于利用第三代(HiFi/CLR/ONT)测序数据组装植物线粒体基因组。PMAT 还可以用于组装叶绿体基因组或动物线粒体基因组。 PMAT:使用低覆盖度HiFi测序数据的高效植物线粒体组装工具包-文献精读分享2 02 参考 https://github.com/bichangwei/PMAT #官网 03 安装 #1 Install u
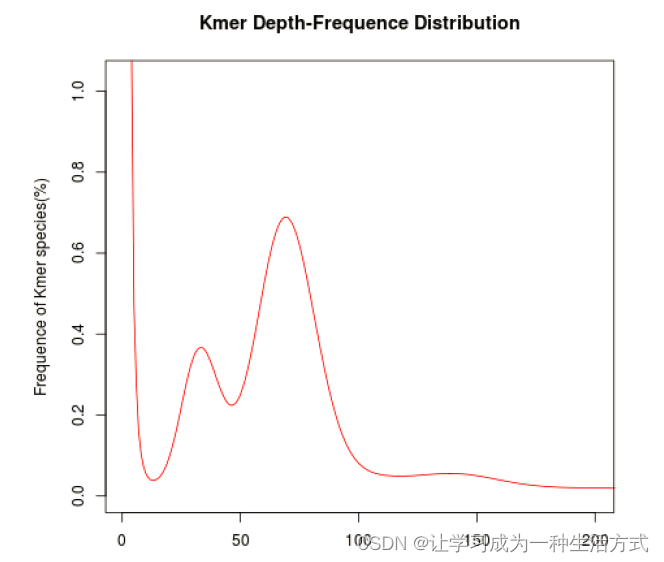
jellyfish安装及使用(Bioinformatics工具-020)
01 背景 基因组survey以测序技术为基础,基于小片段文库的低深度测序,通过K-mer分析,快速获得基因组大小、杂合度、重复序列比例等基本信息,为制定该物种的全基因组de novo测序策略提供有效依据。 jellyfish (水母) 是一个用于快速、内存高效地统计DNA中k-mer数量的工具。一个k-mer是长度为k的子字符串,统计所有这样的子字符串的出现次数是许多DNA序列分析中的核心步

Java for Bioinformatics and Biomedical Applications
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp This book aims to combine industry standard software engineering and design principles, genomics and bioi

bioinformatics小技巧
文章目录 1. 软件安装1.1 linux上python2的安装1.2 Mercurial 安装及使用1.3 tRNAscan的安装和使用1.4 Linux上安装miniconda 2.数据下载2.1 linux上通过ftp下载一个文件夹下的全部文件2.2 GEO数据库数据下载 3.操作系统3.1 Windows下将R设置为环境变量。3.2 Linux 下怎样快速查看一个超大文件夹的文件
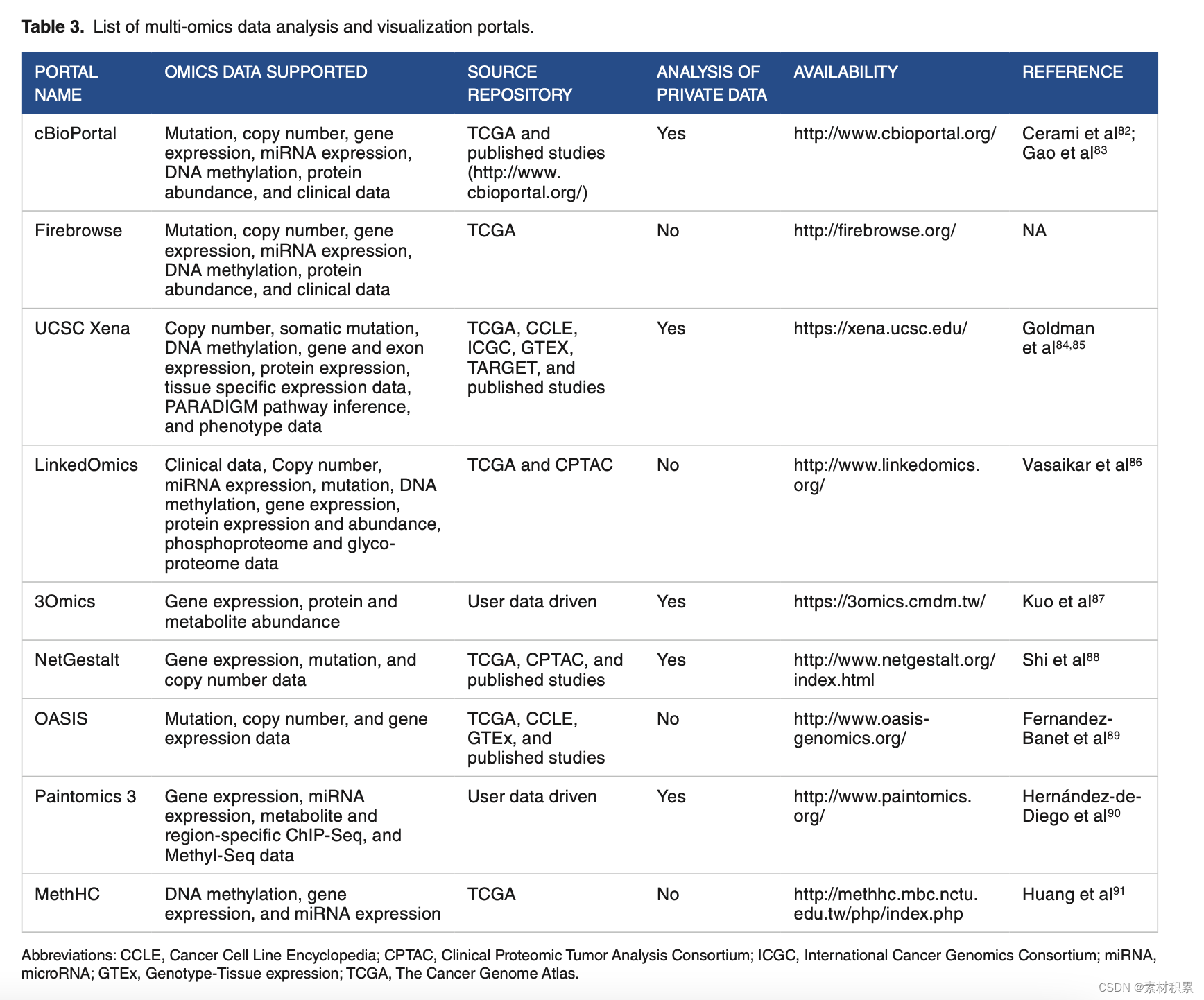
综述 2020-Bioinformatics and biology insights:多组学数据整合和研究方法
Subramanian, Indhupriya, et al. "Multi-omics data integration, interpretation, and its application." Bioinformatics and biology insights 14 (2020): 1177932219899051. 被引次数:746期刊影响因子:5.97多组学数据联合分析 一

INTRODUCTION TO BIOINFORMATICS
INTRODUCTION TO BIOINFORMATICS 这套教程源自Youtube,算得上比较完整的生物信息学领域的视频教程,授课内容完整清晰,专题化的讲座形式,细节讲解比国内的京师大学堂的Mooc教程好过10000倍.下面是视频的快速链接还有文档讲义哦,很好的东东,链接分享给国内的朋友们. =课程主页:http://ocw.metu.edu.tr/course/view

Bioinformatics | 凯斯西储大学张亮亮组发布PICRUSt2预测功能的分析和可视化R包ggpicrust2...
ggpicrust2: 用于PICRUSt2预测功能的分析和可视化R包 ggpicrust2: an R package for PICRUSt2 predicted functional profile analysis and visualization Article,2023-08,[IF = 5.8] DOI:https://doi.org/10.1093/bioinformatic
NMCMDA:神经多类miRNA与疾病关联预测(Briefings in Bioinformatics)
NMCMDA: neural multicategory MiRNA–disease association prediction NMCMDA: neural multicategory MiRNA–disease association prediction | Briefings in Bioinformatics | Oxford AcademicAbstractMotivation.
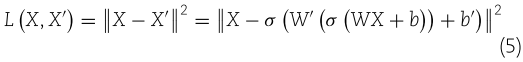
SAEMDA:基于堆叠自编码器的潜在 miRNA-疾病相关性预测(Briefings in Bioinformatics)
Prediction of potential miRNA–disease associations based on stacked autoencoder 源代码:GitHub - xpnbs/SAEMDA Prediction of potential miRNA–disease associations based on stacked autoencoder | Briefings

读书笔记 Bioinformatics Algorithms Chapter5
Chapter5 HOW DO WE COMPARE DNA SEQUENCES Bioinformatics Algorithms-An_Active Learning Approach http://bioinformaticsalgorithms.com/ 一、 1983年,Russell Doolitte 将血小板源生长因子[platelet derived grow

生物信息学Bioinformatics学习笔记(四)- Data analysis-16sRNA
Data analysis-16sRNA 常用V3V4区域进行扩增子测序 Basic analytical procedure 1.原始数据处理 ·去除接头序列,并将双端测序序列拼接成单条序列。 ·根据测序barcode序列区分不同的样本序列。 ·过滤低质量序列和无法比对到16s rDNA数据库的序列。 2.OTU(可执行操作单元)分类和统计 ·以97%的序列相似度将所有序列进行同