bevformer专题

【多视图感知】BEVFormer: Learning Bird’s-Eye-View Representation
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers 论文链接:http://arxiv.org/abs/2203.17270 代码链接:https://github.com/fundamentalvision/BEVFormer
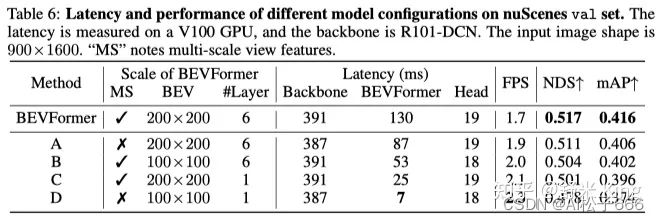
BEVFormer论文详细解读
文章目录 1. 前言1.1 3D VS 4D1.2 .特征融合过程中可能遇到的问题1.3 .BEV提出背景1.4 .BEV最终得到了什么1.5 .输入数据格式 2. 背景/Motivation2.1 为什么视觉感知要用BEV?2.2 生成BEV视角的方法有哪些?为何选用Transformer呢? 3. Method/Strategy——BEVFormer3.1 Overall Archite

bevformer详解(2): 环境搭建
文章目录 1. 环境安装1.1 下载代码1.2 环境配置 2. 准备数据3. 模型训练3.1 处理数据3.2 模型训练3.3 模型测试 1. 环境安装 1.1 下载代码 git clone https://github.com/fundamentalvision/BEVFormer.git 1.2 环境配置 (1) 创建虚拟环境并激活 conda create -n
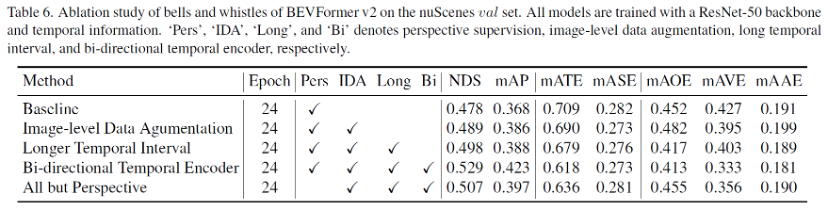
BEVFormer v2论文阅读
摘要 本文工作 提出了一种具有透视监督(perspective supervision)的新型鸟瞰(BEV)检测器,该检测器收敛速度更快,更适合现代图像骨干。现有的最先进的BEV检测器通常与VovNet等特定深度预训练的主干相连,阻碍了蓬勃发展的图像主干和BEV检测器之间的协同作用。为了解决这一限制,我们优先考虑通过引入透视图监督(perspective view supervision)来简
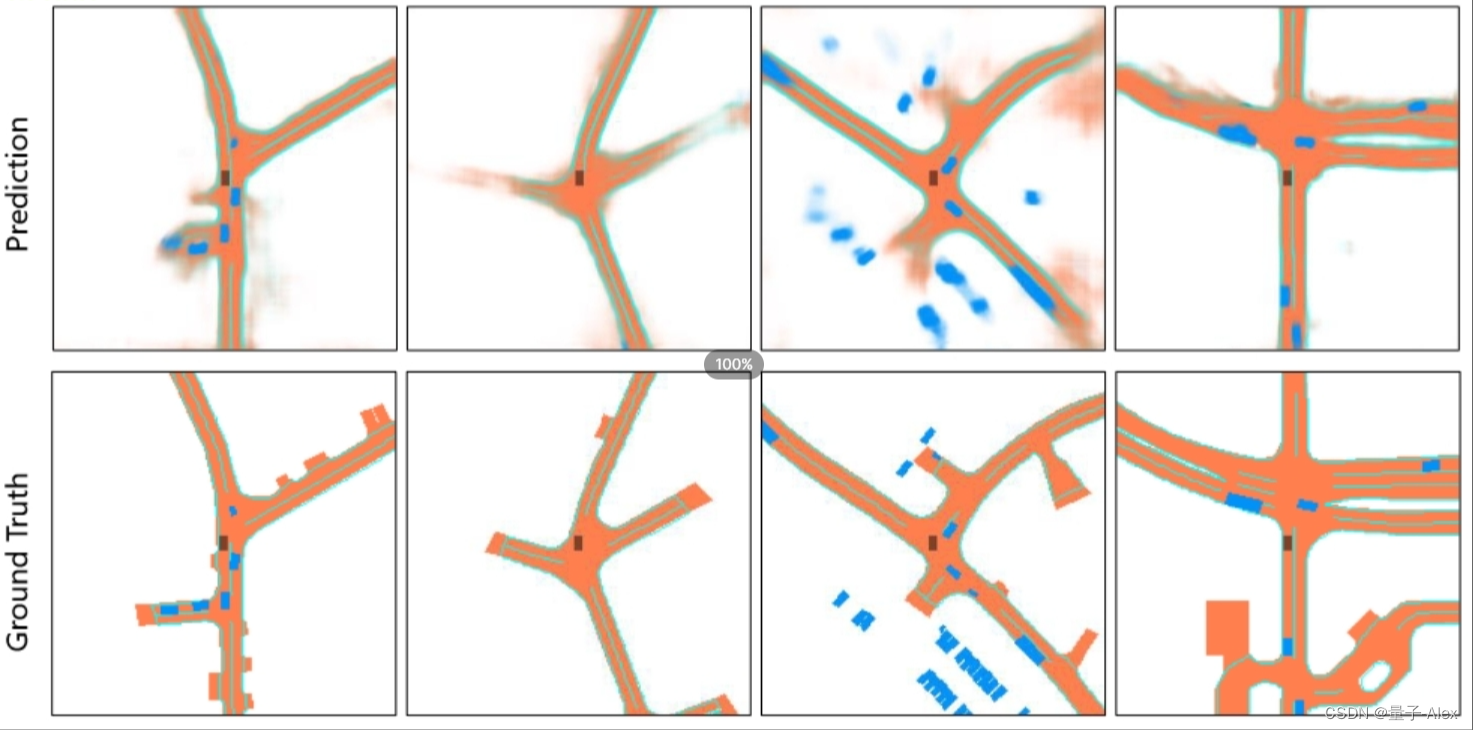
【CV论文精读】【BEV感知】BEVFormer:通过时空Transformer学习多摄像机图像的鸟瞰图表示
【CV论文精读】BEVFormer Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers BEVFormer:通过时空Transformer学习多摄像机图像的鸟瞰图表示 图1:我们提出了BEVFormer,这是一种自动驾驶的范式,它应用Transforme
解读BEVFormer,新一代CV工作的基石
文章出处 BEVFormer这篇文章很有划时代的意义,改变了许多视觉领域工作的pipeline[2203.17270] BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers (arxiv.org)https://arxiv.org/ab

用BEVformer来卷自动驾驶-3
书接前文 前文链接: 用BEVformer来卷自动驾驶-2 (qq.com) 上文书基本把BEV的概念捋清楚了,也对标准BEV可能存在的计算和显存的压力做了一番分析 这篇就是介绍BEVformer是个啥 先给个定义,BEVformer就是个基本框架: 1-通过多个摄像头来进行特征融合,纯视觉方案 2-通过特征对齐,将attention应用

四. 基于环视Camera的BEV感知算法-BEVFormer
目标 前言0. 简述1. 算法动机&开创性思路2. 主体结构3. 损失函数4. 性能对比5. BEVFormerv2总结下载链接参考 前言 自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVFormer 感知算法 课程大纲可以看下面的思维

BEVFormer论文翻译校对版
BEVFormer论文地址:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers 目录 BEVFormer论文翻译摘要1 介绍2 相关工作2.1 基于Transformer的二维感知2.2 基于相机的三维感知 3 BEVFromer

Bevformer:通过时空变换从多摄像机图像学习鸟瞰图表示
论文地址:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers 代码地址:https://github.com/zhiqi-li/BEVFormer 论文背景 三维视觉感知任务,包括基于多摄像机图像的三维检测和地图分割,是自动驾驶系
BEVFormer -通过时空transformers学习多视角图像的BEV表示
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers (readpaper.com) -2022 基于多视角和时序BEV特征迭代优化,获得高精度BEV特征,即作为一个Backbone/neck来使用 简单的说就是提前定义好了 BEV 空