本文主要是介绍BEVFormer论文详细解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 前言
- 1.1 3D VS 4D
- 1.2 .特征融合过程中可能遇到的问题
- 1.3 .BEV提出背景
- 1.4 .BEV最终得到了什么
- 1.5 .输入数据格式
- 2. 背景/Motivation
- 2.1 为什么视觉感知要用BEV?
- 2.2 生成BEV视角的方法有哪些?为何选用Transformer呢?
- 3. Method/Strategy——BEVFormer
- 3.1 Overall Architecture
- 3.2 BEV Queries
- 3.3 SCA: Spatial cross-attention
- 3.4 TSA: Temporal self-attention
- 3.5 Application of BEV Features
- 3.6 Implementation details
- 4. Experiments
- 4.1 experimental settings
- 4.2 3D目标检测结果
- 4.3 multi-tasks perception results
- 4.4 消融试验
- 4.4.1Spatial Cross-attention有效性
- 4.4.2Temporal Self-attention有效性
- 4.4.3Model Scale and Latency
- 5. Discussion
1. 前言
1.1 3D VS 4D
BEV空间的特征我们可以当作是3D的,但是能不能再拓展一步呢?如果再考虑到时间维度,那就是一个4D特征空间了,包括是时序信息时序特征更适合预测速度,轨迹,检测等任务而且还可以进行‘猜想’.
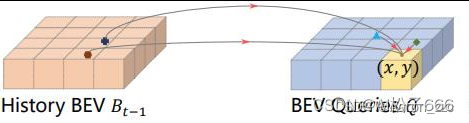
1.2 .特征融合过程中可能遇到的问题
1.自身运动补偿:车在运动,不同时刻之间的特征要对齐
2.时间差异:不同传感器可能具有时间差,要对齐这部分信息
3.空间差异:最后肯定都要映射到同一坐标系,空间位置特征也要对齐
4.谁去对齐呢?肯定不是手动完成的,这些都交给模型去学习就好了
1.3 .BEV提出背景
1.相当于我们在上帝视角下重构了一个特征空间,空间的大小我们自己定义
2.特征空间相当于一个网格,网格的间隔也可以自己定义,对应精度也会有差异
3.在特征空间中,我们可以以全局的视角来进行预测,特征都给你了,咋用你来定
4.难点:既想做的细致,还想节约计算成本,怎么办?BevFormer它来了
1.4 .BEV最终得到了什么
一个核心:纯视觉解决方案(多个视角摄像头进行特征融合)
两个策略:将Attention应用于时间与空间维度(其实就是对齐特征)
三个节约:Attention计算简化,特征映射简化,粗粒度特征空间
基本奠定了框架结构:时间+空间+DeformableAttention
1.5 .输入数据格式
输入张量(bs,queue,cam,C,H,W)
queue表示连续帧的个数,主要解决遮挡问题
cam表示每帧中包含的图像数量,nuScenes数据集中有6个
C,H,W分别表示图片的通道数,图片的高度,图片的宽度
我们只用这6个视觉的CAM数据.
2. 背景/Motivation
2.1 为什么视觉感知要用BEV?
相机图像描述的是一个2D像素世界,然而自动驾驶中利用相机感知结果的后续决策、路径规划都是在车辆所处的3D世界下进行。由此引入的2D和3D维度不匹配,就导致基于相机感知结果直接进行自动驾驶变得异常困难。
这种感知和决策规划的空间维度不匹配的矛盾,也体现在学开车的新手上。倒车泊车时,新手通过后视镜观察车辆周围,很难直观地构建车子与周围障碍物的空间联系,容易导致误操作剐蹭或需要尝试多次才能泊车成功,本质上还是新手从2D图像到3D空间的转换能力较弱。基于相机图像平面感知结果进行决策规划的自动驾驶AI,就好比缺乏空间理解力的驾驶新手,很难把车开好。
实际上,利用感知结果进行决策和路径规划,问题还出现在多视角融合过程中:在每个相机上进行目标检测,然后对目标进行跨相机融合。如2021 TESLA AI Day给出的图1,带拖挂的卡车分布在多个相机感知野内,在这种场景下试图通过目标检测和融合来真实地描述卡车在真实世界中的姿态,存在非常大的挑战。

为了解决这些问题,很多公司采用硬件补充深度感知能力,如引入毫米波雷达或激光雷达与相机结合,辅助相机把图像平面感知结果转换到自车所在的3D世界,描述这个3D世界的专业术语叫做BEV map或BEV features(鸟瞰图或鸟瞰图特征),如果忽略高程信息,就把拍扁后的自车坐标系叫做BEV坐标系(即鸟瞰俯视图坐标系)。
但另外一些公司则坚持不引入深度感知传感器,他们尝试从本质入手,基于视觉学习得到从图像理解空间的能力,让自动驾驶AI系统更像老司机,例如TESLA。Elon Musk认为:人类不是超人,也不是蝙蝠侠,不能够眼放激光,也没安装雷达,但是通过眼睛捕捉到的图像,人类反复练习就可以构建出对周围世界的3D空间理解能力从而很好地掌握驾驶这项能力,那么要像人一样单纯利用眼睛(相机)进行自动驾驶就必须具备从2D图像平面到3D自车空间(BEV)的转换能力。
传统获取BEV map/features的方法有局限性,它一般是利用相机外参以及地面平面假设,即IPM(Inverse Perspective Mapping)方法,将图像平面的感知结果反投影到自车BEV坐标系。Tesla以前的方案也是这样,然而当车辆周围地面不满足平面假设,且多相机视野关联受到各种复杂环境影响的时候,这类方法就难以应付。
针对IPM方法获取BEV遇到的困难,TESLA自动驾驶感知负责人Andrej Karparthy的团队直接在神经网络中完成图像平面到BEV的空间变换,这一改变成为了2020年10月发布的FSD Beta与之前Autopilot产品最显著的差别。TESLA利用Transformer生成BEV Featrues,得到的Features通道数是256(IPM方法最多保留RGB3个channel),这样能极大程度地保留图像信息,用于后续基于BEV Features的各种任务,如动、静态目标检测和线检测等。
2.2 生成BEV视角的方法有哪些?为何选用Transformer呢?
把相机2D平面图像转换成BEV视角的方法有两种:视觉几何方法和神经网络方法。
视觉几何方法:基于IPM进行逐像素几何投影转换为BEV视角,再对多个视角的部分BEV图拼接形成完整BEV图。此方法有两个假设:1.路面与世界坐标系平行,2.车辆自身的坐标系与世界坐标系平行。前者在路面非平坦的情况下并不满足,后者依赖车辆姿态参数(Pitch和Roll)实时校正,且精度要求较高,不易实现。
神经网络方法:用神经网络生成BEV,其中的关键要找到合适的方法实现神经网络内部Feature Map空间尺寸上的变换。
实现空间尺寸变换的神经网络主流操作有两种方法,如图2所示:MLP中的Fully Connected Layer和Transformer Cross Attention(图片引用自《超长延迟的特斯拉AI Day解析:讲明白FSD车端感知》)。
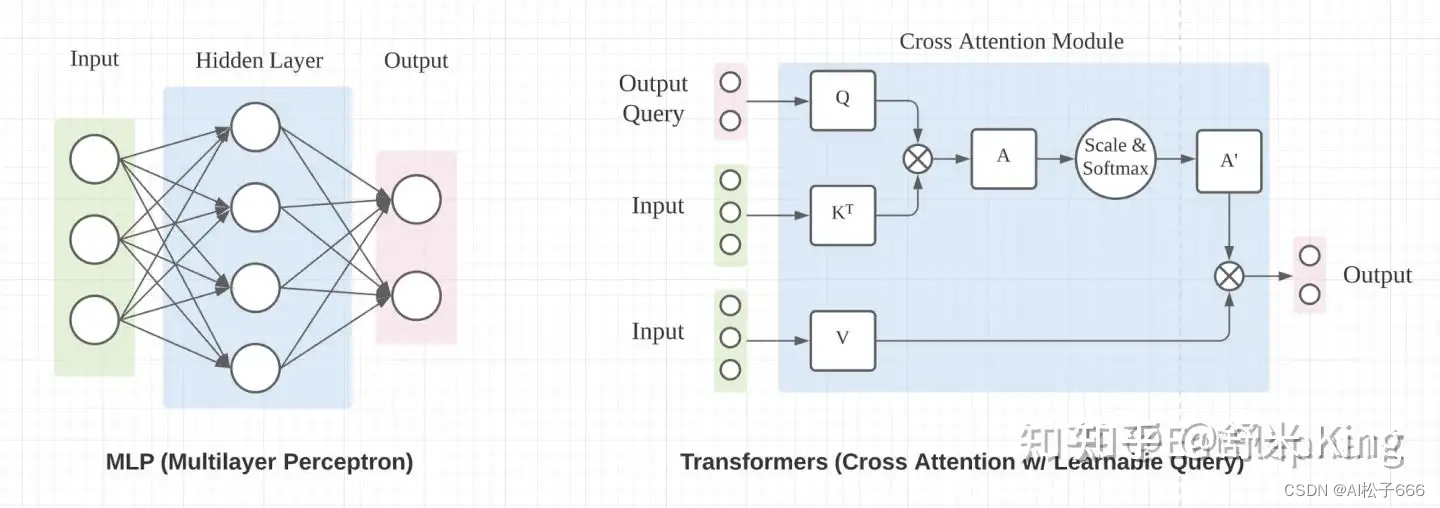

TESLA在2021年AI Day上仅介绍了用Transformer转换BEV Features的技术思想,并未披露更多实现细节。论文BEVFormer充分研究了TESLA的技术思想后,利用Transformer融合图像的时、空特征,得到BEV Features,与TESLA的关键方法、实现效果都非常接近。BEVFormer既通过论文披露了详尽方法,又在2022年6月开源了工程,接下来就围绕BEVFormer介绍如何通过Transformer获取BEV Features。
3. Method/Strategy——BEVFormer
3.1 Overall Architecture
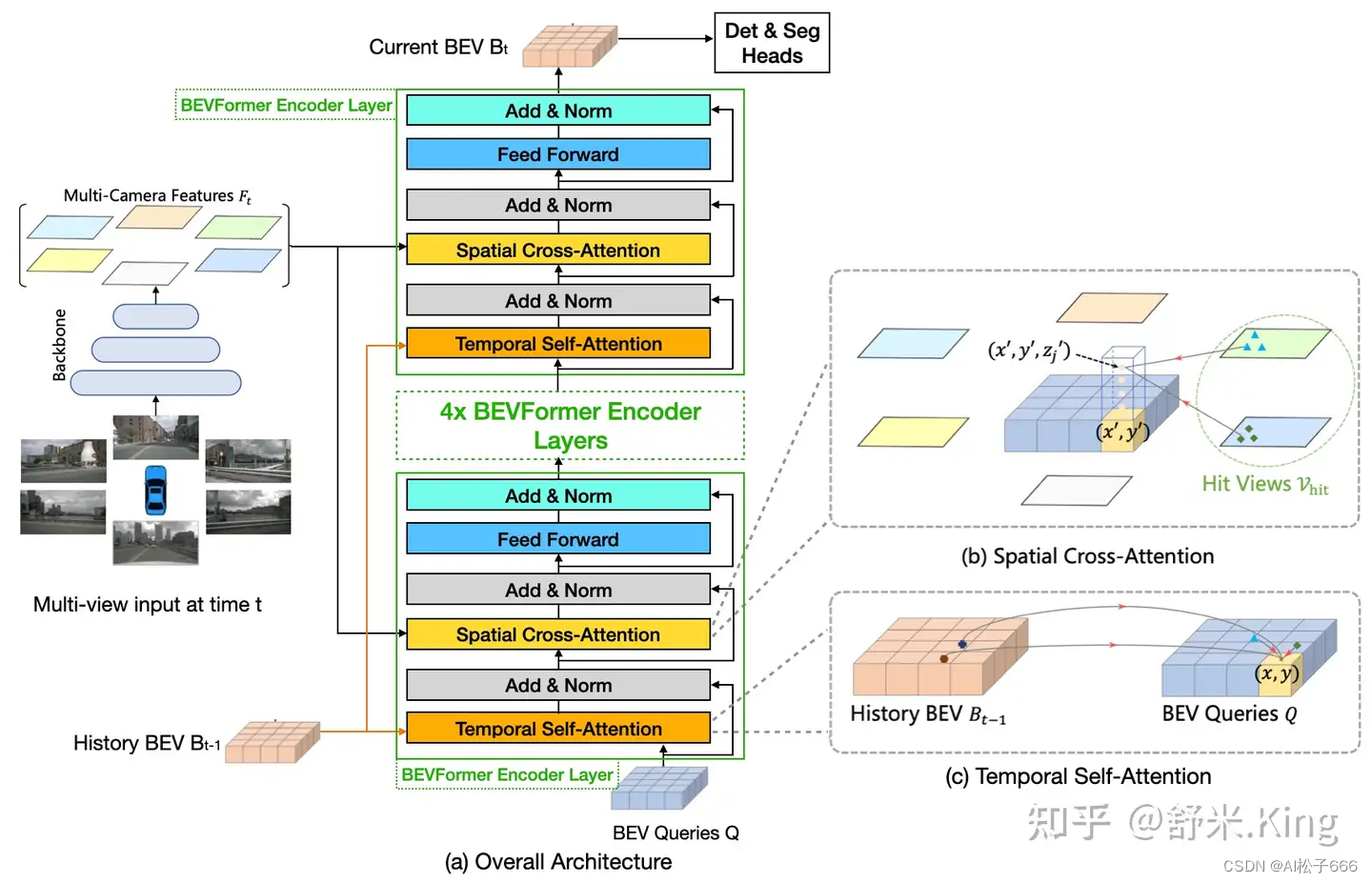
如下图3所示:BEVFormer主体部分有6层结构相同的BEVFormer encoder layers,每一层都是由以transformer为核心的modules(TSA+SCA),再加上FF、Add和Norm组成。BEVFormer encoder layer结构中有3个特别的设计:BEV Queries, Spatial Cross-attention(SCA)和Temporal Self-attention(TSA)。其中BEV Queries是栅格形可学习参数,承载着通过attention机制在multi-camera views中查询、聚合的features。SCA和TSA是以BEV Queries作为输入的注意力层,负责实施查询、聚合空间features(来自multi-camera images)和时间features(来自历史BEV)的过程。
下面分步骤观察BEV完整模型的前向推理过程:

3.2 BEV Queries
BEVFormer采用显性定义BEV的方式,BEV Queries就是其中的显性BEV features。
可从3个概念循序渐进地认识/理解BEV Queries:BEV平面 → BEV 感知空间 → BEV Queries。


3.3 SCA: Spatial cross-attention
如上图(b)所示,作者设计了一种空间交叉注意力机制,使 BEV queries 从多个相机的image Features中提取所需信息并转换为BEV Features。
每个BEV栅格的query在image features的哪些范围提取信息呢?这里有3个方案:
一、从image features的所有点上提取信息,即global attention。
二、从BEV栅格在image features的投影点上提取信息。
三、从BEV栅格在image features的投影点及其周围取信息,即deformable attention。
由于使用了多尺度图像特征和高分辨率 BEV 特征(200x200),如果采用方案一 global attention ,会带来无法负担的计算代价(显存和计算复杂度)。但是,方案一完全用不到相机内外参,这算是它独有的优势。
方案二依赖非常精确的相机内、外参,且不能充分利用image features上的局部区域信息。


3.4 TSA: Temporal self-attention
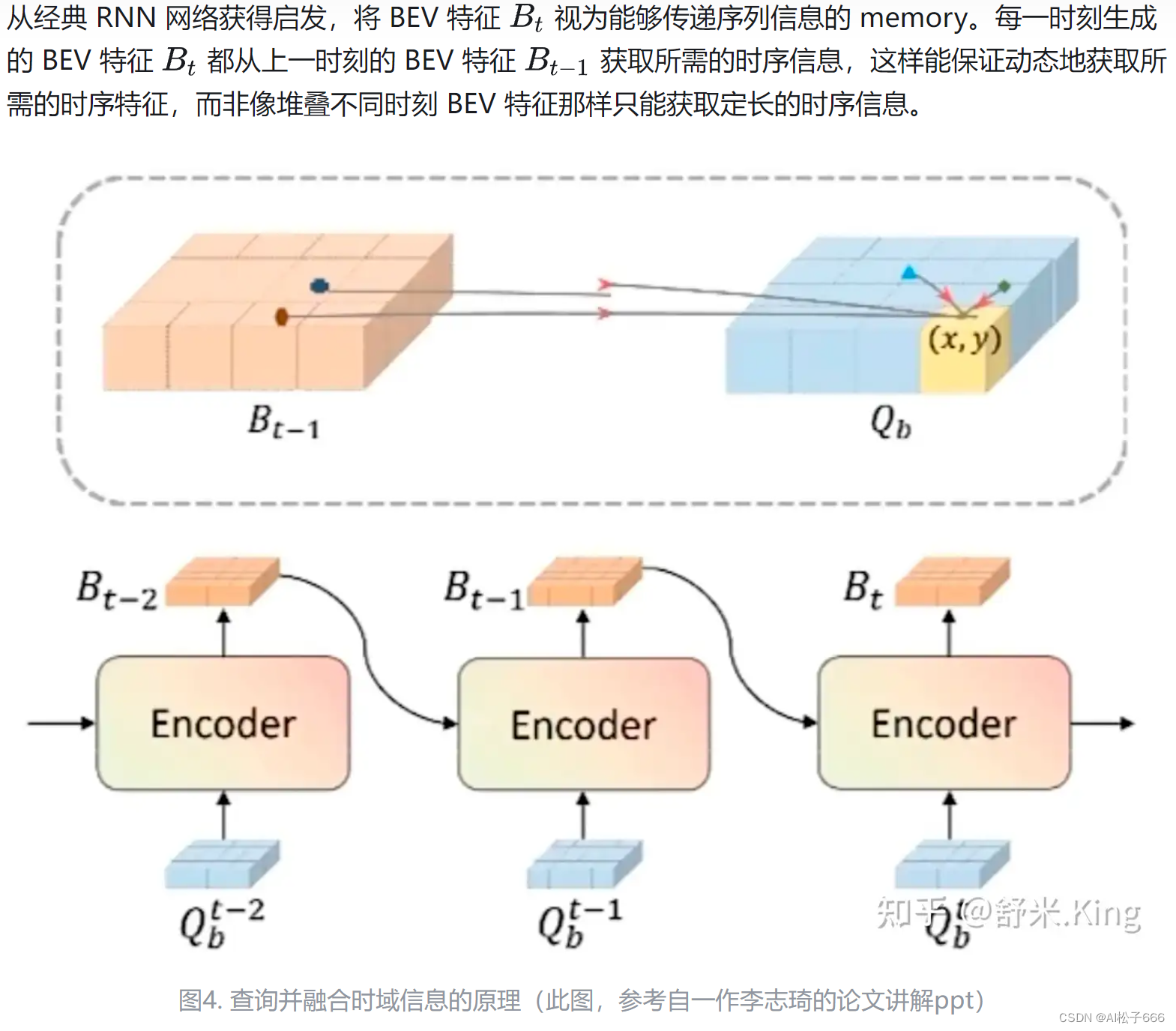

综合3.3和3.4节,观察6个 BEVFormer Encoder Layers的完整结构会发现, BEV query 既能通过 spatial cross-attention 聚合空间特征,又能通过 temporal self-attention 聚合时序特征,这个过程会重复多次,让时空特征融合能够相互促进,最终得到更好的融合BEV features。
3.5 Application of BEV Features

3.6 Implementation details

4. Experiments
4.1 experimental settings

4.2 3D目标检测结果
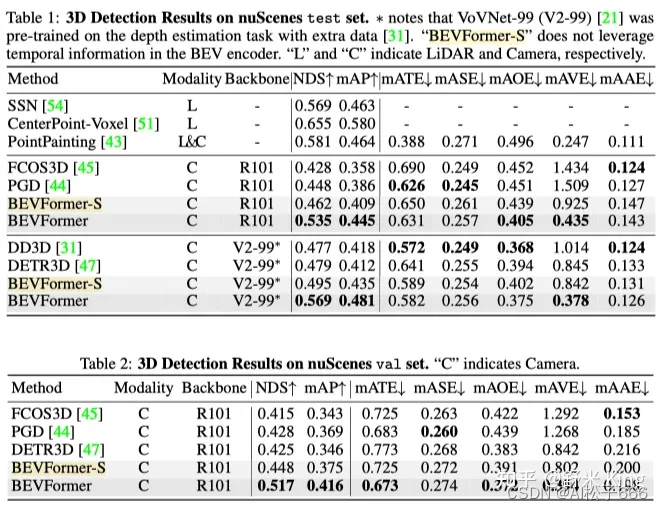
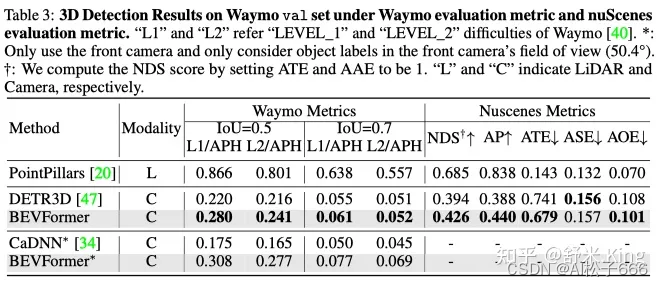
BEVFormer的3D检测性能,如Table1、Table2和Table3所示,远超之前最优方法DETR3D。
BEVFormer引入了temporal information,因此它在估计目标速度方面效果也很好。从速度估计指标mean Average Velocity (mAVE)来看,BEVFormer误差为0.378m/s,效果远好于同类基于相机的方法,甚至逼近了基于激光的方法。
4.3 multi-tasks perception results
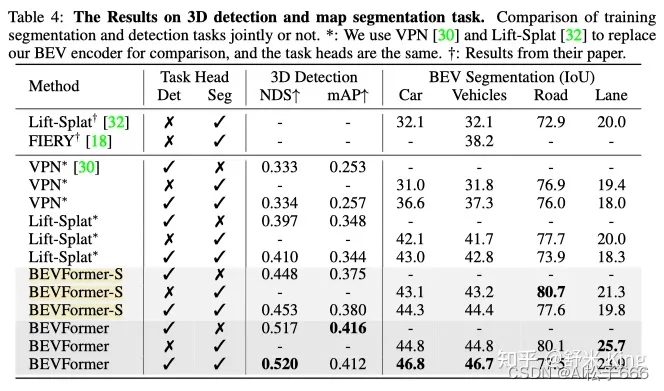
联合训练3D detection和map segmentation任务,与单独训练比较训练效果,如Table4所示:对3D目标检测和分割中的车辆类语义感知,联合训练效果有提升;对分割中的road、lane类的语义感知,联合训练效果反而会下降。
4.4 消融试验
4.4.1Spatial Cross-attention有效性
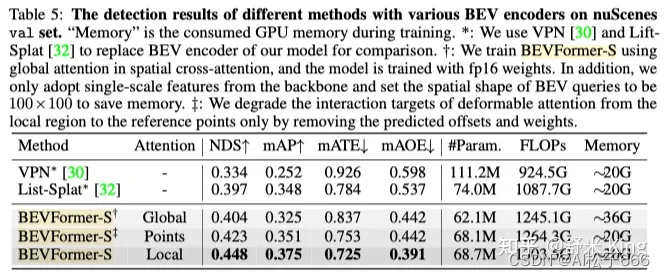
为了验证SCA的有效性,利用不包含TSA的BEVFormer-S来设计消融试验,结果如Table5所示。
默认的SCA基于deformable attention,在对比试验中构建了基于2种不同attention机制的baselines:1. 用global attention取代deformable attention;2. 让每个query仅与它的图像参考点交互,而不是像SCA那样query与图像参考点周围区域交互。为了扩大对比范围,把BEVFormer中的BEV生成方法替换为了VPN和Lift-Spalt中的方法。从Table5结果可见Deformable Attention方法显著优于其它方法,且在GPU Memory使用量和query兴趣区域大小之间实现了balance。
4.4.2Temporal Self-attention有效性
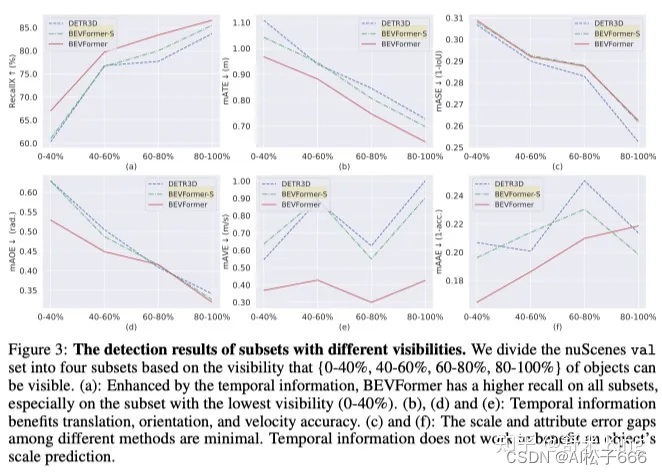
从Table1和Table4可见,在相同的设置下,BEVFormer相比于BEVFormer-S的性能大幅提升,针对有挑战性的检测任务提升更明显。TSA主要是在以下方面影响性能提升的:1.temporal information的引入对提高目标速度估计精度非常有益;2.利用temporal information,目标预测的location和orientations更精确;3.受益于temporal information包含过去时刻object的信息,如图4所示,严重遮挡目标的recall 更高。根据nuScenes标注的遮挡程度把验证数据集进行划分成4部分,来评估BEVFormer对各种程度遮挡的性能,针对每个数据子集都会计算average recall(匹配时把中心距离的阈值设为2m)。
4.4.3Model Scale and Latency
针对不同Scale Settings的BEVFormer,对比检测性能和latency,结果如Table6所示。在3方面进行BEVFormer的Scale配置:1. 输入到BEVFormer Encoder的features是multi-scale还是single-scale;2.BEV Queries/features的尺寸;3. encoder layer数目。
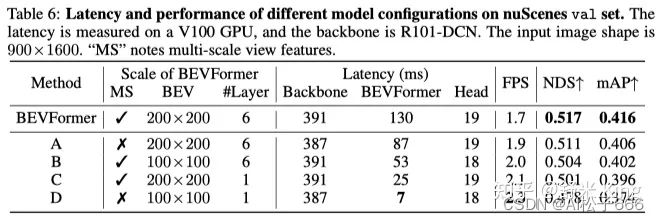
从实验结果看来:Backbone的Latency远大于BEVFormer,因此Latency优化的主要瓶颈在于Backbone而不是BEVFormer(这里指BEVFormer Encoder部分),BEVFormer可以采用不同的Scale,具备支持灵活平衡性能和efficiency的特性。
5. Discussion
1.理论上视觉图像的数据比激光数据稠密,但基于视觉的BEV效果还是比基于激光的方法性能差,那么也说明了理论上视觉还有可提升空间。
2.BEV Features能用于泊车位检测么? 可能可以用BEVFormer在环视鱼眼相机上生成BEV features,用于泊车位检测或近距离目标的精确检测。
3.显性地引入BEV 特征,限制了最大检测距离,在高速公路场景,检测远处目标非常重要,如何权衡BEV的大小与检测距离是一个需要考虑的问题。
4.如何在检测精度和grid大小之间做平衡是一个问题。
针对2、3问题的一个优化方向:设计自适应尺寸的BEV特征。这里的自适应是指根据场景来调整BEV尺寸或精度。
参考文档:https://zhuanlan.zhihu.com/p/538490215
这篇关于BEVFormer论文详细解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







