baichuan2专题

使用docker部署tensorrtllm推理大模型baichuan2-7b
简介 大模型的推理框架,我之前用过vllm和mindie。近期有项目要用tensorrtllm,这里将摸索的过程记录下,特别是遇到的问题。 我的环境是Linux+rt3090 准备docker环境 本次使用docker镜像部署,需要从网上拉取: docker pull nvcr.io/nvidia/tritonserver:24.08-trtllm-python-py3 The Tri

开源模型应用落地-baichuan2模型小试-入门篇(三)
一、前言 相信您已经学会了如何在Windows环境下以最低成本、无需GPU的情况下运行baichuan2大模型。现在,让我们进一步探索如何在Linux环境下,并且拥有GPU的情况下运行baichuan2大模型,以提升性能和效率。 二、术语 2.1. CentOS CentOS是一种基于Linux的自由开源操作系统。它是从Red Hat Enterprise

ubuntu从零部署baichuan2大模型
目录 一、百川2(Baichuan 2)模型介绍 二、资源需求 三、安装部署 本文从实战过程中整理一份从零开始的搭建开源大模型的部署文档,供大家学习交流。 部署大模型版本为baichuan2-13B chat,如果需要量化可下载量化版本 。 一、百川2(Baichuan 2)模型介绍 首先先简单介绍一下百川推出的两款开源模型:Baichuan2-13B 和 Baichuan2-7B
Baichuan2百川模型部署的bug汇总
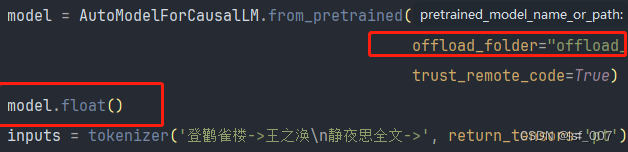
1.4bit的量化版本最好不要在Windows系统中运行,大概原因报错原因是bitsandbytes不支持window,bitsandbytes-windows目前仅支持8bit量化。 2. 报错原因是机器没有足够的内存和显存,offload_folder设置一个文件夹来保存那些离线加载到硬盘的权重。 ag:需要再cli_demo.py的文件中增加 offload_folder="offl
LLM - 大模型速递 Baichuan2 快速入门
目录 一.引言 二.模型探索 1.模型下载 2.模型结构 ◆ Baichuan-1-13B 结构 ◆ Baichuan-2-13B 结构 3.模型测试 ◆ Baichuan-2-13B Chat 推理 ◆ Baichuan-2-13B 显存 4.模型量化 ◆ 在线量化 ◆ 离线量化 ◆ 量化效果 5.模型迁移 三.模型微调 1.样本构造 2

AIGC:【LLM(八)】——Baichuan2技术报告
文章目录 摘要1. 引言2. 预训练2.1 预训练数据(Pre-training Data)2.2 架构(Architecture)2.3 令牌化器(Tokenizer)2.3.1 Positional Embeddings 2.4 激活和规范化(Activations and Normalizations)2.5 优化(Optimizations)2.6 规模定律(Scaling Laws

baichuan2 chat模型sft指令微调数据格式分析
一、前言 百川官网:https://www.baichuan-ai.com/ 模型权重:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat 记录一下 baichuan 2 的 tokenizer 及 chat 数据构建格式。 二、数据处理代码 根据官方 github 的 finetune 代码,将其 preprocessing 方法抽

Baichuan2开源聊天框架,使用Baichuan2-7B-Chat-4bits模型运行成功,硬件16G内存/GTX1070显卡
前提摘要: 一.这几天一直在找开源的chatgpt框架,运行成功的有llama.cpp、chatgml2和baichuan2框架,先说说llama.cpp框架,使用的是cpu运行的框架,也成功了,但是我16g的cpu差点给我干烧了,太慢了,完全没法使用,相当累赘。 二.再说说chatgml2框架,这个框架该说不说,非常棒,gpu运行成功了,cpu运行也成功了,就是我的硬件是16G内存/GTX107
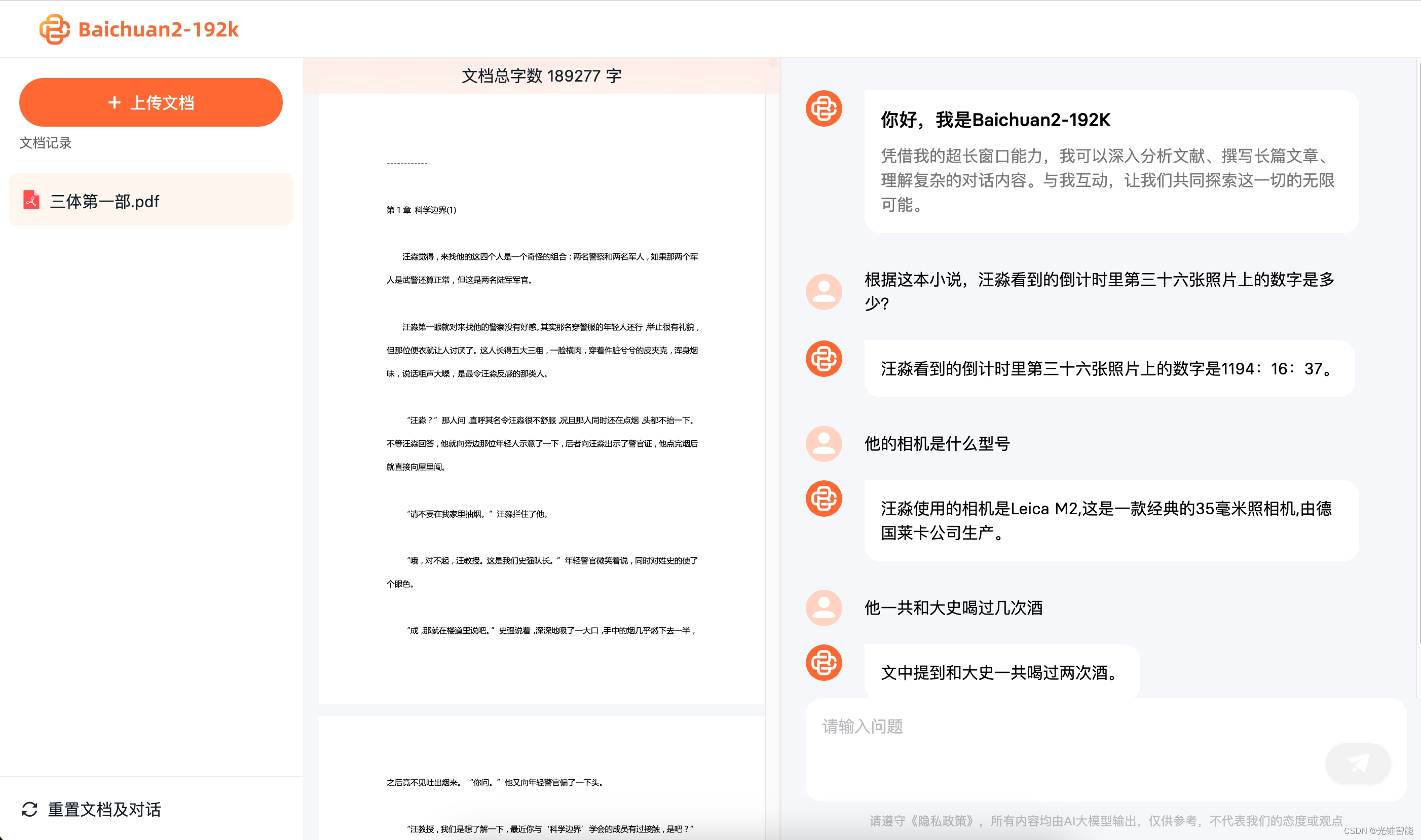
百川智能发布大模型Baichuan2-192K,一次可输入35万字超越Claude2
10月30日,百川智能发布Baichuan2-192K大模型。其上下文窗口长度高达192K,是目前全球最长的上下文窗口。Baichuan2-192K能够处理约35万个汉字,是目前支持长上下文窗口最优秀大模型Claude2(支持100K上下文窗口,实测约8万字)的 4.4倍,更是 GPT-4(支持32K上下文窗口,实测约 2.5万字)的14倍。Baichuan2-192K不仅在上下文窗口长度上超越C

正确部署Baichuan2(Ubuntu20.4) 步骤及可能出现的问题
部署其实是不太复杂的,但实际上也耗费了接近2-3天的时间去不断的设置 1 硬件配置信息 采用esxi 虚拟化的方式将T4 卡穿透给esxi 种的ubuntu20.4虚拟机 CPU给到8 core 内存至少32GB以上 T4卡是16GB 2 预先准备OS环境 这里使用的是ubuntu20.4版本,esxi中需要设置uefI启动方式,否则会不识别到T4卡或者T4卡的驱动无法安装正确 3 下
GPT实战系列-Baichuan2本地化部署实战方案
目录 一、百川2(Baichuan 2)模型介绍 二、资源需求 模型文件类型 推理的GPU资源要求 模型获取途径 国外: Huggingface 国内:ModelScope 三、部署安装 配置环境 安装过程

baichuan2(百川2)本地部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了baichuan2(百川2)本地部署的实战方案,希望对学习大语言模型
Langchain-Chatchat项目:1.2-Baichuan2项目整体介绍
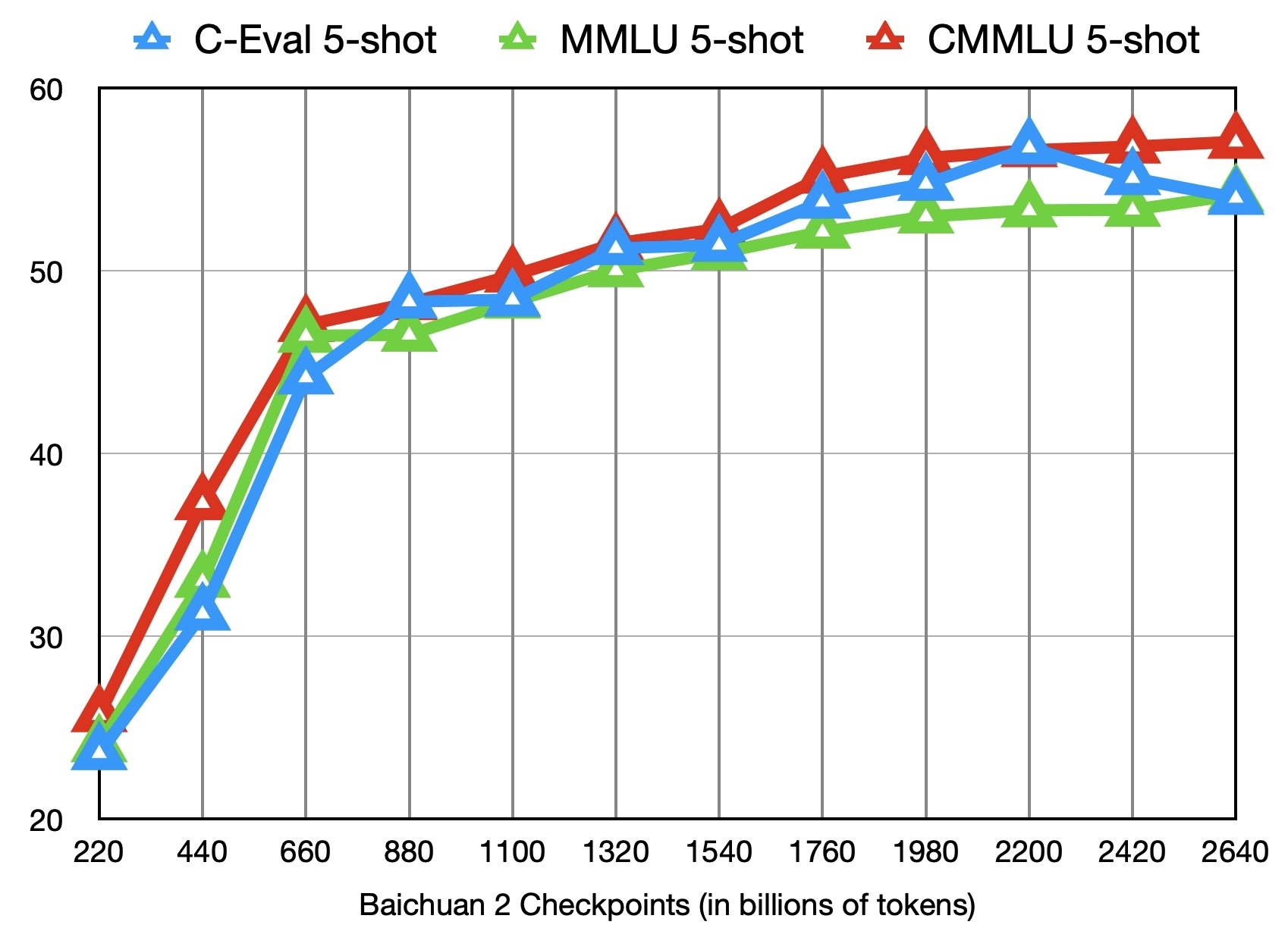
由百川智能推出的新一代开源大语言模型,采用2.6万亿Tokens的高质量语料训练,在多个权威的中文、英文和多语言的通用、领域benchmark上取得同尺寸最佳的效果,发布包含有7B、13B的Base和经过PPO训练的Chat版本,并提供了Chat版本的4bits量化。 一.Baichuan2模型 Baichuan2模型在通用、法律、医疗、数学、代码和多语言翻译六个领域的中英文和多语言权威