本文主要是介绍百川智能发布大模型Baichuan2-192K,一次可输入35万字超越Claude2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
10月30日,百川智能发布Baichuan2-192K大模型。其上下文窗口长度高达192K,是目前全球最长的上下文窗口。Baichuan2-192K能够处理约35万个汉字,是目前支持长上下文窗口最优秀大模型Claude2(支持100K上下文窗口,实测约8万字)的 4.4倍,更是 GPT-4(支持32K上下文窗口,实测约 2.5万字)的14倍。Baichuan2-192K不仅在上下文窗口长度上超越Claude2,在长窗口文本生成质量、长上下文理解以及长文本问答、摘要等方面的表现也全面领先Claude2。
今年9月25日,百川智能已开放了Baichuan2的API接口,正式进军企业级市场,开启商业化进程。此次Baichuan2-192K将以API调用和私有化部署的方式提供给企业用户,目前百川智能已经启动Baichuan2-192K的API内测,开放给法律、媒体、金融等行业的核心合作伙伴。
10项长文本评测7项取得SOTA,全面领先Claude2
上下文窗口长度是大模型的核心技术之一,通过更大的上下文窗口,模型能够结合更多上下文内容获得更丰富的语义信息,更好的捕捉上下文的相关性、消除歧义,进而更加准确、流畅的生成内容,提升模型能力。
Baichuan2-192K在Dureader、NarrativeQA、LSHT、TriviaQA等10项中英文长文本问答、摘要的评测集上表现优异,有7项取得SOTA,显著超过其他长窗口模型。
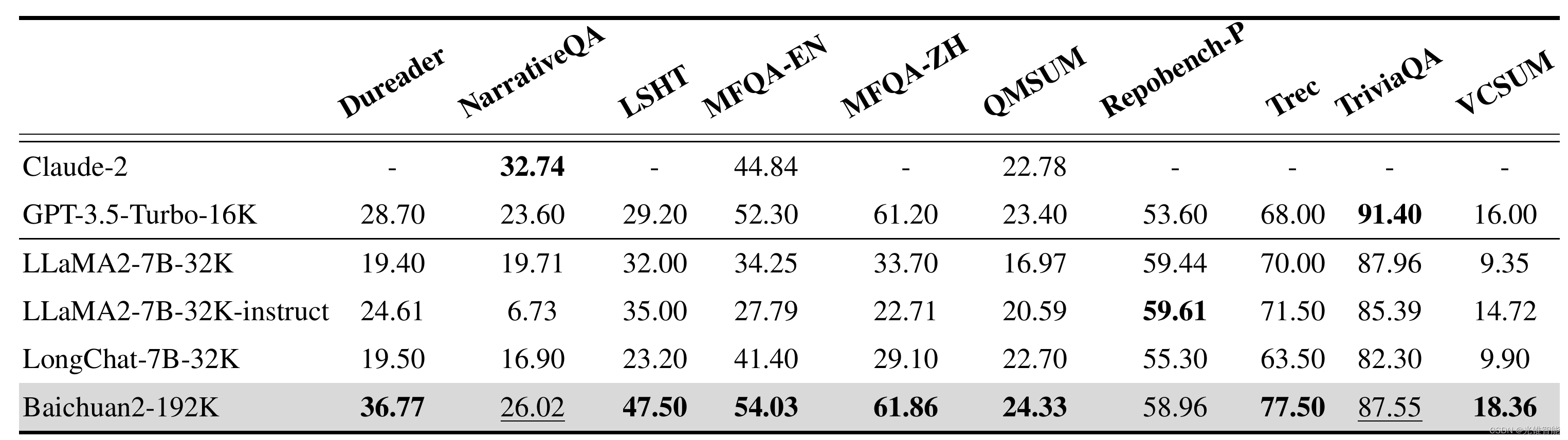
此外,LongEval的评测结果显示,在窗口长度超过100K后Baichuan2-192K依然能够保持非常强劲的性能,而其他开源或者商用模型在窗口增长后效果都出现了近乎直线下降的情况。Claude2也不例外,在窗口长度超过80K后整体效果下降非常严重。由此可见,Baichuan2-192K的长窗口内容记忆和理解能力大幅领先其他模型。

(LongEval是加州大学伯克利分校联合其他高校发布的针对长窗口模型的评测榜单,主要用来衡量模型对长窗口内容的记忆和理解能力,是业内公认的长上下文窗口理解权威评测榜单)
动态采样的位置编码优化,4D并行的分布式方案,同步提升窗口长度和模型性能
扩大上下文窗口能有效提升大模型性能是人工智能行业的共识,但是超长上下文窗口意味着更高的算力需求和更大的显存压力。目前,业内有很多提升上下文窗口长度的方式,包括滑动窗口、降采样、小模型等。这些方式虽然能提升上下文窗口长度,但对模型性能均有不同程度的损害,换言之都是通过牺牲模型其他方面的性能来换取更长的上下文窗口。
而本次百川发布的Baichuan2-192K通过算法和工程的极致优化,实现了窗口长度和模型性能之间的平衡,做到了窗口长度和模型性能的同步提升。
算法方面,百川智能提出了一种针对RoPE和ALiBi动态位置编码的外推方案,该方案能够对不同长度的ALiBi位置编码进行不同程度的Attention-mask动态内插,在保证分辨率的同时增强了模型对长序列依赖的建模能力。在长文本困惑度标准评测数据 PG-19上,当窗口长度扩大,Baichuan2-192K的序列建模能力持续增强。

(PG-19是DeepMind发布的语言建模基准数据集,是业内公认的衡量模型长程记忆推理问题的评测标准)
工程方面,在自主开发的分布式训练框架基础上,百川智能整合目前市场上所有先进的优化技术,包括张量并行、流水并行、序列并行、重计算以及Offload功能等,独创了一套全面的4D并行分布式方案。该方案能够根据模型具体的负载情况,自动寻找最适合的分布式策略,极大降低了长窗口训练和推理过程中的显存占用。
百川智能在算法和工程上针对长上下文窗口的创新,不仅是大模型技术层面的突破,对于学术领域同样有着重要意义。Baichuan2-192K验证了长上下文窗口的可行性,为大模型性能提升开拓出了新的科研路径。
Baichuan2-192K正式开启内测,已落地法律、媒体等诸多真实场景
Baichuan2-192K现已正式开启内测,以API调用的方式开放给百川智能的核心合作伙伴,已经与财经类媒体及律师事务所等机构达成了合作,将Baichuan2-192K全球领先的长上下文能力应用到了传媒、金融、法律等具体场景当中,不久后将全面开放。
全面开放API之后,Baichuan2-192K便能够与更多的垂直场景深度结合,真正在人们的工作、生活、学习中发挥作用,助力行业用户更好的降本增效。Baichuan2-192K 能够一次性处理和分析数百页的材料,对于长篇文档关键信息提取与分析,长文档摘要、长文档审核、长篇文章或报告编写、复杂编程辅助等真实场景都有巨大的助力作用。
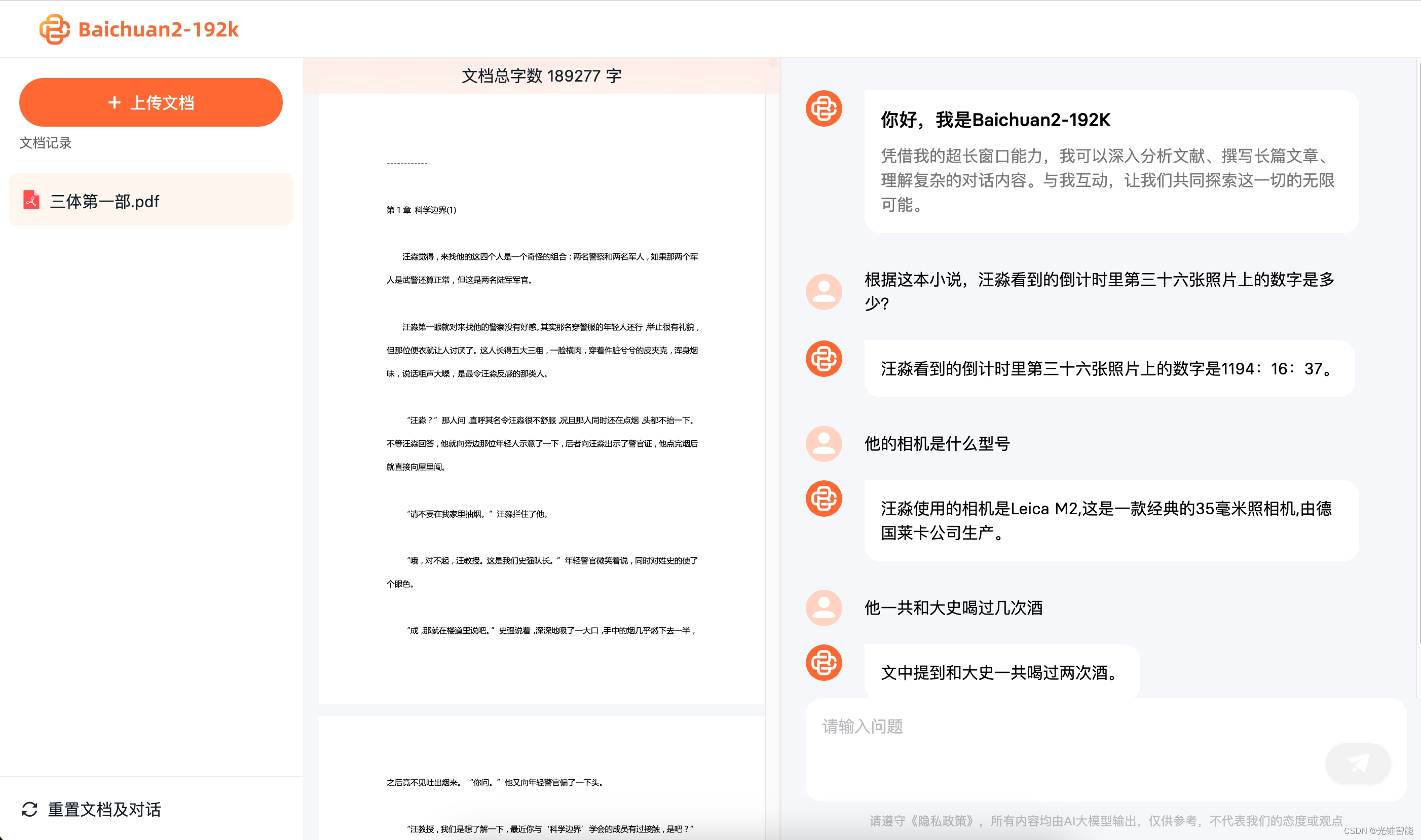
它可以帮助基金经理总结和解释财务报表,分析公司的风险和机遇;帮助律师识别多个法律文件中的风险,审核合同和法律文件;帮助技术人员阅读数百页的开发文档,并回答技术问题;还能帮助科员人员快速浏览大量论文,总结最新的前沿进展。
不仅如此,更长的上下文还为其更好的处理和理解复杂的多模态输入,以及实现更好的迁移学习提供了底层支撑,这将为行业探索Agent、多模态应用等前沿领域打下良好技术基础。
这篇关于百川智能发布大模型Baichuan2-192K,一次可输入35万字超越Claude2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








