本文主要是介绍深入解析kube-scheduler的算法自定义插件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
编辑
一、问题引入
二、自定义步骤
三、最佳实践考虑
一、问题引入
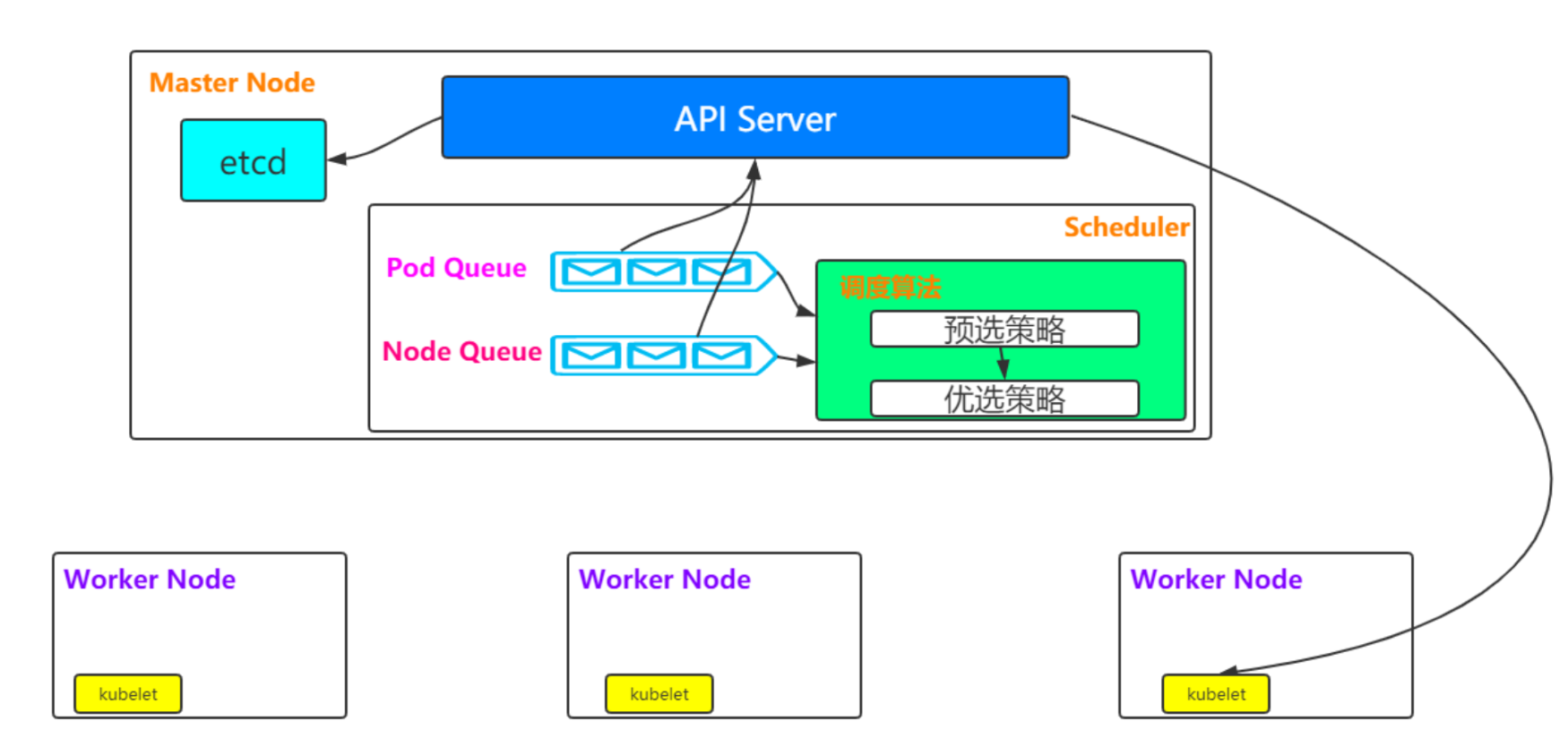
当涉及到 Kubernetes 集群的调度和资源分配时,kube-scheduler 是一个关键组件。kube-scheduler 负责根据集群的调度策略,将 Pod 分配到适当的节点上。kube-scheduler 默认使用一组内置的调度算法来实现这个功能,但它也提供了一种机制,允许用户自定义调度算法,这就是算法自定义插件。
算法自定义插件允许用户根据特定需求和约束,编写自己的调度算法,并将其插入到 kube-scheduler 中。这样的插件可以根据不同的标准和条件来评估节点的可用性和适应性,以决定将 Pod 分配到哪个节点上。
二、自定义步骤
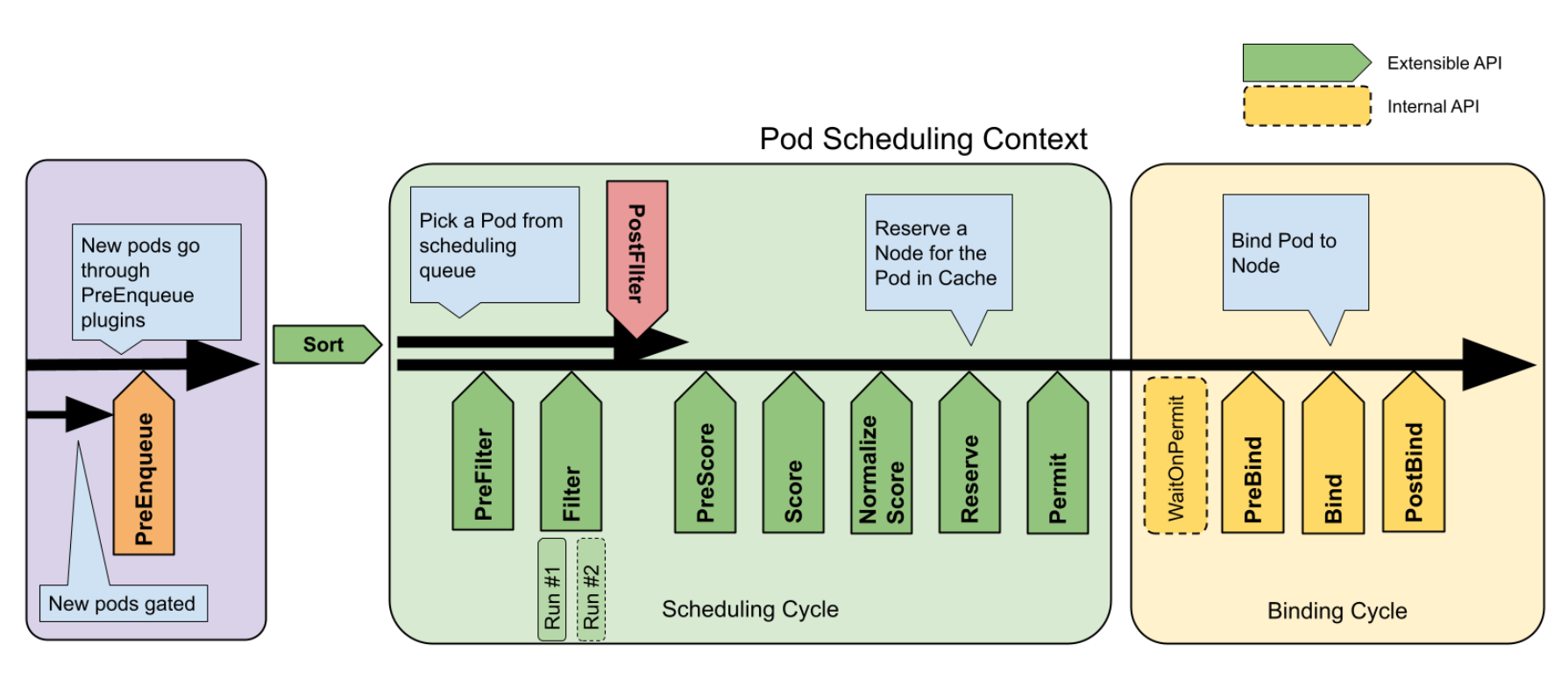
下面是一个详细解释,展示如何编写和使用 kube-scheduler 的算法自定义插件。
-
创建插件文件:
首先,创建一个插件文件,例如my_scheduler_plugin.go。 -
导入必要的包:
在插件文件中,导入所需的包,包括 Kubernetes 的调度框架和其它相关的依赖。import ("context""k8s.io/kubernetes/pkg/scheduler/framework" ) -
定义插件结构体:
定义一个实现framework.Plugin接口的结构体,并为其添加必要的字段。type MySchedulerPlugin struct {// 添加所需的字段和配置 } -
实现插件方法:
在插件结构体中,实现framework.Plugin接口的方法,包括Name()、PreFilter()、Filter()、PostFilter()、PreScore()、Score()、NormalizeScore()和Permit()等方法。这些方法允许你定义插件在调度过程中的不同阶段做出的决策和操作。
func (p *MySchedulerPlugin) Name() string {// 返回插件的名称 }func (p *MySchedulerPlugin) PreFilter(ctx context.Context, state *framework.CycleState, pod *v1.Pod) *framework.Status {// 在预过滤阶段执行操作 }func (p *MySchedulerPlugin) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {// 在过滤阶段执行操作 }// 实现其它方法... -
注册插件:
在extension-apiserver或kube-scheduler的启动配置中,将插件注册到 kube-scheduler 中。apiVersion: kubescheduler.config.k8s.io/v1beta1 kind: KubeSchedulerConfiguration plugins:score:enabled:- my-scheduler-plugin通过将插件添加到
score.enabled列表中,告诉 kube-scheduler 启用你的自定义插件。 -
编译并运行 kube-scheduler:
使用合适的构建工具,编译 kube-scheduler,并确保你的插件代码可以被正确引用和加载。go build -o kube-scheduler cmd/kube-scheduler/main.go ./kube-scheduler
这是一个简单的插件示例,实际的插件可能需要更多的逻辑和判断。可以根据自己的需求和场景,编写定制的插件来满足特定的调度要求。
三、最佳实践考虑
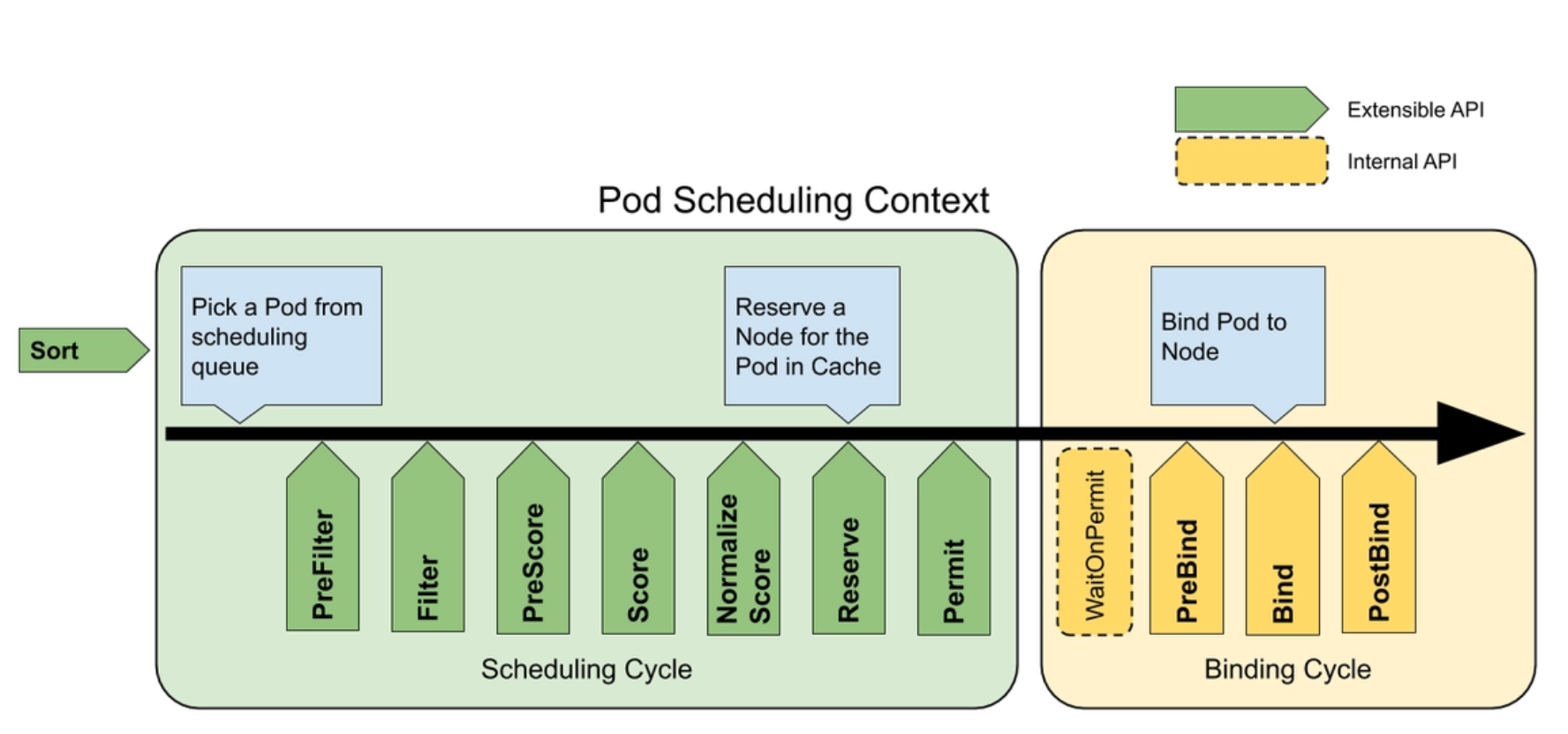
当涉及到 kube-scheduler 的算法自定义插件时,以下是一些最佳实践可以考虑:
-
理解调度需求:在编写自定义插件之前,确保充分理解你的调度需求。明确你想要实现的调度策略、约束条件和优先级。
-
考虑性能和可伸缩性:自定义插件对调度性能和可伸缩性有一定影响。在编写插件时,注意代码的效率和性能,避免引入过多的开销和延迟。
-
使用调度器框架:在编写自定义插件时,建议使用 Kubernetes 提供的调度器框架。该框架提供了一组接口和方法,帮助你在调度过程的不同阶段进行决策和操作。
-
多插件协作:Kubernetes 支持同时运行多个调度插件。考虑将多个插件组合使用,以实现更复杂的调度策略。确保插件之间的协作和顺序是正确的,并避免冲突或竞争条件。
-
测试和验证:在将自定义插件部署到生产环境之前,进行充分的测试和验证。使用合适的测试工具和技术,确保插件的正确性、稳定性和性能。
-
文档和注释:良好的文档和注释对于自定义插件的维护和协作非常重要。确保你的插件代码具有清晰的注释、示例和使用文档,以便其他人能够理解和使用它。
-
社区参与:参与 Kubernetes 社区的讨论和交流,分享你的经验和学习。从其他用户和开发者那里获取反馈和建议,以不断改进和优化你的自定义插件。
这些最佳实践可以帮助在使用 kube-scheduler 的算法自定义插件时获得更好的结果,并确保插件的可靠性和性能。记住,根据具体需求和场景进行适当的调整和改进。
这篇关于深入解析kube-scheduler的算法自定义插件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






