本文主要是介绍高效查询秘诀,解码YashanDB优化器分组查询优化手段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
分组查询是数据库中使用场景非常广泛的一个操作,作用是对查询出来的数据按照某些列进行分组与汇聚,得到汇聚或者运算后的结果,其性能对于数据库查询而言,也是非常重要的一环。本文将介绍一下数据库基本的分组操作与一些优化手段。
产生分组操作的场景
通常以下四种场景可能产生分组操作:
01 直接使用Group by关键字
比如下面的例子,统计每个部门入职时间大于三年的员工数,首先选择出入职时间大于三年的所有员工数,然后按照部门进行分组操作,就能得到想要的结果。
SELECT dept, count(*)
FROM employees
WHERE enroll_date > sysdate – 3 years
GROUP BY dept
02 其他关键字(Distinct)或者隐式分组操作
比如:
select count(*) from employees;
统计所有的员工数,可以认为,这是所有的数据都在一个分组的分组操作。
select distinct dept from employees;
统计员工的部门,相同的部门只出现一次,这个可以认为是只有分组没有汇聚计算的分组操作。
其等价于下列语句:
select dept from employees group by dept;
注:一些数据库的distinct和group by内部是统过一个算子来实现的,一些数据库是通过不同的算子实现的,所以,在平时的测试中,有的数据库这两种等价改写的效率是一致的,有的数据库这两种等价改写的效率是不同的。
03 适用于分析系统的高级分组操作
比如:rollup,cube,grouping sets,本文主要聚焦在简单group上,对该部分本文不做详细分析。
04 优化器自动添加的分组操作
有时候,语句中是没有明显的group by操作的,但是查看执行计划的时候,却发现了分组操作,这是YashanDB优化器在某些场景下,自动添加分组操作实现了一个等价操作,通常是Distinct这种没有汇聚的分组。
比如:TPCC中的一个语句:
SELECT count(*) AS low_stock FROM (SELECT s_w_id, s_i_id, s_quantityFROM bmsql_stockWHERE s_w_id = ? AND s_quantity < ? AND s_i_id IN (SELECT ol_i_idFROM bmsql_districtJOIN bmsql_order_line ON ol_w_id = d_w_idAND ol_d_id = d_idAND ol_o_id >= d_next_o_id - 20AND ol_o_id < d_next_o_idWHERE d_w_id = ? AND d_id = ?)
);
生成的执行计划如下:
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) | Partition info|
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | |
| 1 | AGGREGATE | | | 1| 2( 0)| |
| 2 | NESTED INDEX LOOPS INNER | | | 1| 2( 0)| |
| 3 | SORT DISTINCT | | | 3| 1( 0)| |
| 4 | VIEW | | | 3| 1( 0)| |
| 5 | NESTED INDEX LOOPS INNER | | | 3| 1( 0)| |
|* 6 | TABLE ACCESS BY INDEX ROWID| BMSQL_DISTRICT | REGRESS | 1| 1( 0)| |
|* 7 | INDEX UNIQUE SCAN | BMSQL_DISTRICT_PKEY | REGRESS | 1| 1( 0)| |
| 8 | TABLE ACCESS BY INDEX ROWID| BMSQL_ORDER_LINE | REGRESS | 1| 1( 0)| |
|* 9 | INDEX RANGE SCAN | BMSQL_ORDER_LINE_PKEY| REGRESS | 3| 1( 0)| |
|*10 | TABLE ACCESS BY INDEX ROWID | BMSQL_STOCK | REGRESS | 1| 1( 0)| |
|*11 | INDEX UNIQUE SCAN | BMSQL_STOCK_IDX1 | REGRESS | 1| 1( 0)| |
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
计划中有一个SORT DISTINCT,YashanDB优化器将in子查询改写为join后,认为先对semi部分去重,再和左边的表进行nested loop join性能比较好,自动添加了个Distinct操作来实现去重(没有汇聚的分组)。
当然,对于该计划,有些数据库是通过Right Semi操作来实现的。这是一个简单的例子,在很多场景下,都可能发现数据库优化器自动添加了Distinct/Unique操作,来优化查询路径。
分组操作的常见算法
分组常用的分组算法有:Hash分组、排序分组、TOPN分组、基于多列Distinct的特殊分组等,下面将展开介绍每一种算法。
01 Hash分组
Hash分组的实现包含以下几个步骤:首先,对分组列先计算其Hash值;其次,根据一定的算法(比如,直接取模)将Hash值映射到Hash桶上,这样Hash值相同的值落在一个Hash桶内;最后,对每个桶内数据做分组操作,也就实现了全局分组的操作。
影响Hash分组性能和Hash表效率的关键因素主要有几个:
- Hash冲突的多少。冲突越高,性能越低。因为在一个桶内,如果使用链表,则是遍历扫描的;如果使用开放地址法,不同Hash值之间的地址占用也会增加Hash查找的次数。那如何来规避冲突的可能性呢?关键通过控制Hash表的大小,如果Hash表的大小小于不同分组值的个数,则Hash冲突是一定产生的,所以Hash表的大小需要尽可能的大于数据不同值的个数,另外,Hash桶的个数一般采用素数,来减少Hash冲突的可能性。
- Hash表动态增长导致的数据拷贝操作。解决办法主要是尽可能一次性分配足够的Hash表内存,这就要求需要对Hash表大小尽可能估计准确,数据库一般通过统计信息计算来估算经过分组之后的条数有多少,为分配Hash表提供依据。
下面看一个简单的例子:
假设表中数据为:1,3,5,7,9。Hash算法采用取原值,则数据的Hash也为1,3,5,7,9。Hash值到Hash桶的映射采用取模。
我们来分析下不同Hash桶下的影响:
情况1:我们假设Hash桶有3个,数据存放情况如下:3个桶都被使用到,0号桶和1号桶中各存放2条记录,2号桶中存放了一条记录,有Hash冲突产生。

情况2:我们假设Hash桶有5个,数据存放情况如下:5个桶都被使用到,而且每个桶内只有一个不同值,这时候,Hash比较的效率是最高的。

情况3:我们假设Hash桶有6个,数据存放情况如下:只有3个桶被使用到,1号桶中存放了2条记录,3号桶中存放了2条记录,5号桶中放了1条记录。

虽然分配了6个桶,但是只有3个桶有数据,效果还不及5个桶的时候。
所以在使用上,需要Hash表尽可能的既保证大小足够存放不同值,又保证值尽可能的离散分布在Hash桶上。
02 基于排序数据的分组
基于有序数据进行分组
如果分组之前,数据已经按照分组列排序了,那么分组的实现就比较简单了,每一行判断和上一行是在同一个分组内,只需要扫描一遍,整个分组就完成了。
所以,优化器对于分组操作,会有一条尝试下层增加排序的路径,这条路径上,保证了到分组操作之前,数据已经是按照分组列排序好了。满足排序的方式主要有几种:
方式1:
通过添加排序算子实现:下层为保证数据有序,可以显示的添加一个Sort算子,用以保证查询的结果是按照分组键来排序的。
方式2:
经过产生隐式数据排序的算子后,数据可能本身就已经有序,可以避免额外排序的产生。这些算子可能包括索引扫描、Merge sorted join等。当索引列或者Join条件产生的排序可以满足分组列时,可以直接使用基于排序数据的分组。
注:该情况仅限于有序的索引,主要是B+树索引。R-Tree索引和反向索引等都无法保证输出数据是有序的,另外,Index Fast Full Scan是基于索引数据的存储直接访问的,返回的数据不具备有序性。
基于无序数据进行分组
如果数据无序,也可以在分组的过程中,一边排序一边汇聚,这是分组操作的另一个可能的算子路径,YashanDB采用SDT group来表示这种分组。
SDT与上述有序数据分组的区别如下:
a. 基于添加排序的分组,有个完整独立的排序操作和分组操作。
1,3,2,3,1 → SORT:1,1,2,3,3 → GROUP:1,2,3
b.SDT分组:在排序的过程中,如果发现是相同的分组,则直接进行汇聚计算。在行数较多,distinct值较少的情况下,这种方法可以显著的减少内存的使用。
1,3,2,3,1 → SORT-GROUP:(1,1),2,(3,3)
在结构上,每个不同的分组值,只保留一个值与前面的汇总结果。
03 TopN分组
在部分场景下,有些分组操作的语句不需要返回所有分组,只需要返回前几个分组即可。这种场景下,如果TopN的列是分组列相关的,分组操作是不需要保留所有分组值的,继而产生TopN分组的优化需求。
以下是一个简单的例子:
分组结构上,只保留前TopN个不同的分组值,一个新值来后,判断是否属于TopN,如果属于TopN,则替换掉分组中的一个存在的最大/最小值。
TOP2: 1,3,2,3,1
1 → 1,3 → 2,3
04 多个Distinct的分组
除了分组外,如果汇聚函数中同时出现distinct操作,则需要实现每个分组内的数据再进行除重操作。
这种操作对于数据库而言,实现的代价相对来说是比较大的,尤其是分组数特别多,每个分组的数据不太多时;而且出现多个distinct时,需要启动非常多的除重操作。
针对这样的场景,数据库会实现一个额外的算法来减少除重个数,通过补空加一个排序,代替分组以及每个分组内的除重操作。具体看如下例子:
select count(distinct c2) from table group by c1
该语句首先根据c1分组,然后每个分组内对c2分别进行除重,直接按照c1和c2进行分组/排序。因为是按照c1和c2排序的,c1内相同的c2是放在一起的,所以一次排序就可以实现group和distinct的计算。
也可以通过如下两次Group来等价实现:
select count(*) from (select c2 from table group by c1, c2) group by c1;
由上面的例子,我们可以看出,当只有一个distinct时,distinct的列可以直接追加在group列的后面,通过一次排序或者分组,数据的顺序就可以同时满足分组和除重操作。
当有多个distinct时,是否也可以通过一次排序来实现呢?我们看一下下面的例子:
select count(distinct c2), count(distinct c3) from table group by c1;
该例子同时存在一个group和两个distinct操作。该操作c2的distinct操作和c3的distinct操作是完全无关,分别计算的,我们可以在计算c2的时候,对c3列完全补空值,计算c3的时候,对c2列完全补空值,因为空值不影响汇聚计算结果。
这样,我们通过将数据翻一倍,c1列保持原值,c2列保持原值的时候,c3列补空,c3列保持原值的时候,c2列补空,然后通过对c1,c2,c3排序,数据上可以同时满足c1的分组和c2,c3的distinct计算。
数据实现如下:
表中原始数据,2条

扩展后数据,2条*2(distinct的个数)
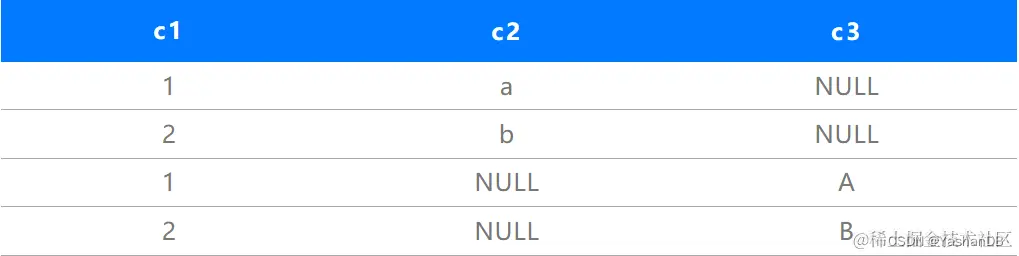
c1, c2, c3 → c1, NULL , c3 + c1 , c2 , NULL → Sort c1, c2, c3 → 一遍扫描实现。
通过该算法可以极大的减少分组操作的个数,但是整体排序的数据量会变大(原始数据乘以汇聚函数带Distinct的个数)。优化器会根据代价,来确定是否选择该算法。
分组操作的优化规则
01 分组列优化
参与分组的列需要进行比较操作,所以在等价的情况下,参与分组的列越少越好。那YashanDB优化器是如何尽可能的减少分组列的个数的呢?
优化方式1:常量优化/等价关系优化
这里的常量指的是运行时判断为常量,主要包括输入的常量、SQL传入的参数等。以下为几个优化示例:
输入常量:
select *** from t1 group c1, 2 → select *** from t1 group by c1
输入参数:
select *** from t1 group c1, :1 → select *** from t1 group by c1
等价关系:
select *** from t1 where b1 = 2 group by b1, c1 → select *** from t1 where b1 = 2 group by c1
优化器会从全局推导出某个group by中的列是否为运行时常量,从而决定是否可以优化掉。
优化方式2:主键优化/Key constraint优化
以下是主键优化的几个示例:表T1上存在主键(a1, b1)
select *** from t1 group by a1, b1, c1 → select *** from t1 group by a1, b1
因为a1,b1为主键列(非空的唯一索引列也具备同样功能),通过a1,b1可以唯一的表示整行,所以a1,b2的分组与所有列的分组等价。
select *** from t1, t2 where t1.b1 = t2.b2 group by a1, b2, c1 → select *** from t1, t2 where t1.b1 = t2.b2 group by a1, b1
通过内在的等价关系,寻找满足主键条件的相关列进行优化。
如果数据已经进行过一次分组,则分组列可以唯一表示分组后的每一行,后续再出现类似的分组操作,也可以使用这些分组列来进行优化,数据库通过key constraint来表示这种关系,从而实现后续分组的优化。
优化方式3:列顺序优化
从逻辑意义上,分组结果与分组列的顺序是无关的,也就是说group by a1, b1与group by b1, a1是等价的,但是排序是与列的顺序强相关的。
当同时存在排序和分组时,YashanDB优化器在选择排序分组算法时,会尝试优化分组顺序,从而保证排序可以利用分组的顺序,优化掉一次排序操作。具体示例如下:
Select *** from t1 group by a1, b1 order by b1 → select *** from group by b1, a1 order by b1
分组列为a1, b1,排序列为b1,当使用排序分组时,如果按照a1,b1排序的,则最后还要按照b1 再排序一次,如果时按照b1,a1排序的,那么按照b1排序本身就天然满足了,就不需要额外的排序了。
02 分布式/并行下的分组
分组是对全局数据进行的,在分布式或者基于数据流的并行执行下,是否可以将分组操作并行化,在每个线程内进行呢?什么情况下需要进行这种分组呢?
下面我们来看一下YashanDB对于分布式或者并行下分组的实现方式(并行与分布式类似,以下以分布式为例)。
select *** from t1 group by c1
以一个简单的语句在分布式的执行为例,可以有如下图所示的几种执行方式:
方式1:
把所有数据节点(DN)的数据都发送到协调节点(CN)上来,在CN上进行一个全局数据的分组操作。适合数据量较小的操作。
方式2:
在每个数据节点内先进行一次分组操作,然后将每个数据节点上汇总的数据再发送到协调节点,协调节点再做一次全局分组操作。
方式3:
分布式下,当分布键是分组键的子集时,数据的分布保证了每个数据节点上的数据都在不同的分组内,则每个数据节点进行分组后,无需全局分组,一次分组就可以实现。可以将分组操作并行的执行,分布式下最理想的分组方式。
方式4:
每个数据节点上的数据,先按照分组键子集进行数据重分发,分发的数据满足不同节点上的数据是属于不同分组的,然后每个节点内进行分组操作即可。

注:CN为SQL入口协调节点,DN为分布式的数据节点。
假设有10个数据节点,我们以几个不同数据分布场景为例子,介绍下如何选择合适的执行方式:
场景一:
t1: 100万记录,数据随机均匀分布在10个数据节点上。极端场景,分组键c1都是重复值1。这个场景下,每个数据节点有100万/10=10万数据。
方式1:
所有数据都要分发到协调节点,数据分发100万。在协调节点上执行一个100万的分组操作。
100万分发+100万CN上的集中分组操作。
方式2:
每个数据节点并行的执行10万记录的分组操作,汇总完后每个数据节点的数据为1条,然后总的10条记录发送到协调节点,进行一个10条记录的分组。
10条分发+10万分组操作+10条分组操作(CN)。
方式3:
数据分布不满足。
方式4:
先将100万按照分组键分发,由于分组键的取值都是1,所以都会分发到一个数据节点上,其他的DN都没数据,所以无法并行执行,然后在这个节点上进行一个分组,最后发到CN。
100万分发+100万单DN分组+1条数据分发。
可以看出,在这个场景下,方式2是最佳的执行方式。
场景二:
t1: 数据量不变,还是100万,但是分组键c1数据是唯一的但不是分布键,也没定义为主键。
方式1:
和场景一的代价相同,100万分发+100万CN上的集中分组操作。
方式2:
每个数据节点上执行一次10万的分组,因为数据是唯一的,分组后的数据还是10万条,所以数据节点上的分组操作是无效分组。然后都发送到CN,在进行一次分组。
10万数据节点分组+100万分发+100万CN节点分组。
方式3:
数据分布不满足。
方式4:
先按照分组键进行分发,因为分组键是唯一的,可以均匀的分布到各个数据节点,每个节点做分组操作即可。
100万数据分发+10万数据节点分组操作+100万数据分发。
对比下,方式4是相对最佳的执行方式。
场景三:
t1: 数据量不变,按分组键c1均匀分布式在数据节点上。
方式1:
和前面场景的代价相同,100万分发+100万CN上的集中分组操作。
方式2:
根据分布键不同值的多少,如果数据只有一个值,则和场景一一样,如果数据是唯一的,则和场景二一样,所以代价在二者之间。
10条分发+10万分组操作+10条分组操作(CN)和10万数据节点分组+100万分发+100万CN节点分组之间。
方式3:
因为数据本身满足分布,数据节点上的分组就是全局分组。
每个数据节点10万分组,分组后数据直接发送给协调节点给客户端即可。发送数据取决于分组后数据大小。最佳执行方式。
方式4:
先进行100万的数据分发,分发后按照在每个数据节点上的数据最大为100万行(数据全重复),最小为10万行(数据可以完全均匀分布), 这样分组操作实际上是10万到100万之间,然后发送到协调节点,相比较方式3,多了一次100万的数据分发。
通过以上几个场景,可以看出,在分布式下,即使是完全相同的数据量,根据分布键和分组键的关系以及分组键不同值的多少,都可能选择不同的执行方式。YashannDB优化器将根据统计信息,来选择最佳的执行方式,并尽可能的保证统计信息的正确性。当然,网络吞吐、内存大小等,也会影响到优化器选择。
总结
除了以上介绍的基本优化之外,YashanDB优化器对分组操作还做了一些其他的优化,比如:Group by下推,Partition wised group等。对于分析的多维分组,cube、 rollup、 grouping sets等,数据库依据不同的数据分布和多维分组列关系,也做了不同程度优化,本文暂不做过多阐述。
本文是Meetup第十期“调优实战专场”的第一篇技术文章,下一篇《YashanDB Meetup系列文章》将带来YashanDB常用的SQL调优思路与手段。欢迎关注“YashanDB”公众号,持续关注本系列文章!
这篇关于高效查询秘诀,解码YashanDB优化器分组查询优化手段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






