本文主要是介绍深度学习之基于YOLOV5的口罩检测系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
一、项目背景
随着全球公共卫生事件的频发,口罩成为了人们日常生活中不可或缺的一部分。在公共场所,如商场、车站、学校等,确保人们正确佩戴口罩是防控疫情的重要措施之一。然而,人工检查口罩佩戴情况不仅效率低下,而且难以全面覆盖。为了解决这一问题,本项目提出了基于YOLOv5的口罩检测系统。该系统能够自动对人群中的口罩佩戴情况进行检测,极大地提高了检测效率和准确性。
二、项目目标
本项目的目标是开发一个基于YOLOv5的口罩检测系统,该系统能够实时处理视频流或图像数据,并准确识别出人群中是否佩戴口罩以及口罩佩戴的正确性。系统应具备以下特点:
实时性:系统能够实时处理视频流或图像数据,并快速给出检测结果。
准确性:系统能够准确识别出人群中是否佩戴口罩以及口罩佩戴的正确性。
灵活性:系统能够适应不同场景下的口罩检测需求,如室内、室外、不同光照条件等。
三、技术实现
算法选择:本项目选择YOLOv5作为核心算法。YOLOv5是一种基于深度学习的目标检测算法,具有检测速度快、准确性高等优点。它采用单次前向传播即可实现端到端的目标检测,并采用了多种优化策略,如锚框自适应、多尺度预测等,进一步提高了检测性能。
数据集准备:为了训练YOLOv5模型进行口罩检测,需要准备一个包含人脸和口罩标注的数据集。数据集应包含多种场景下的图片和视频数据,如室内、室外、不同光照条件等。同时,数据集中的图片和视频应尽可能清晰,标注应准确无误。
模型训练:使用TensorFlow或PyTorch等深度学习框架对YOLOv5模型进行训练。在训练过程中,可以通过调整网络参数、优化器设置、损失函数选择等方式来优化模型性能。此外,还可以采用数据增强技术(如随机裁剪、旋转等)来扩展数据集,提高模型的泛化能力。
系统实现:在算法实现的基础上,开发一个完整的口罩检测系统。该系统应包括视频或图像输入模块、口罩检测模块、结果输出模块等。用户可以通过该系统实时查看视频流或图像数据中的口罩佩戴情况,并获取相应的检测结果。
二、功能
深度学习之基于YOLOV5的口罩检测系统
三、系统

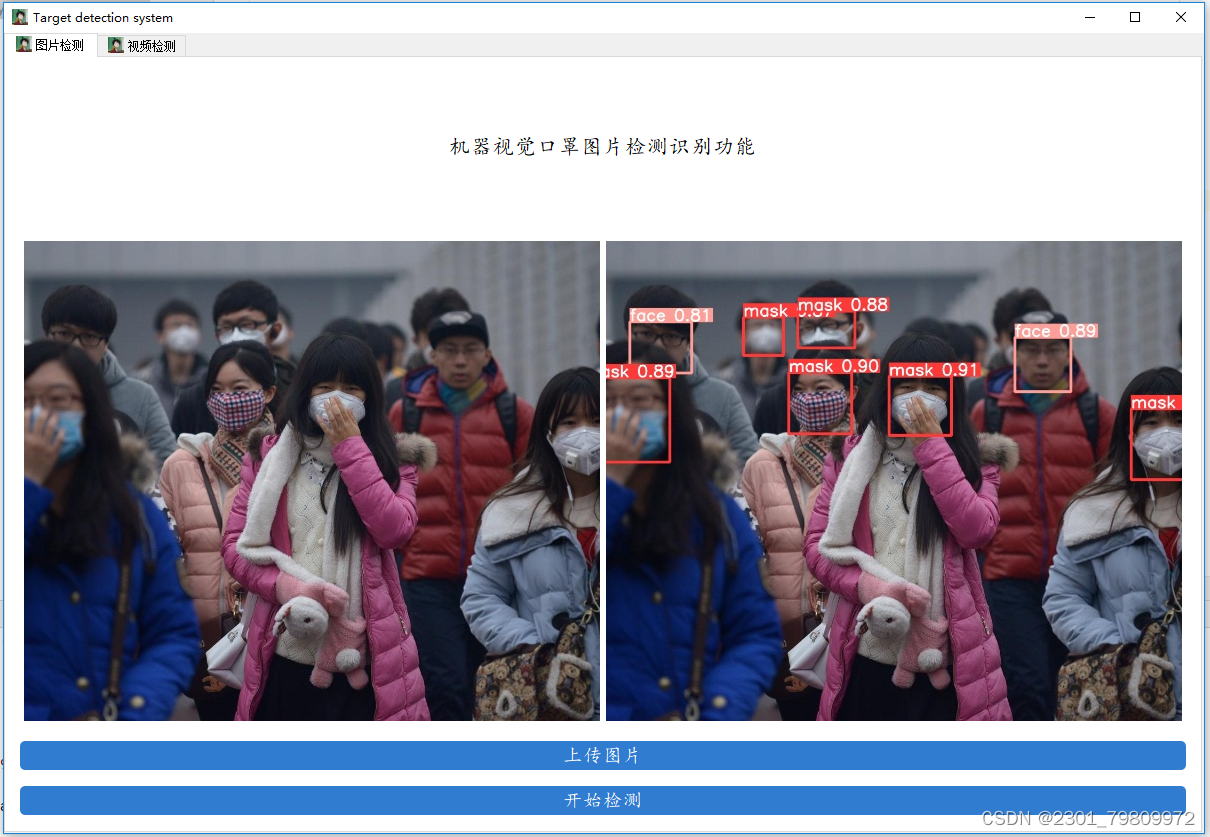
四. 总结
提高检测效率和准确性:相比人工检查,基于YOLOv5的口罩检测系统能够实时处理大量数据,并快速给出准确的检测结果。这将大大减轻人工检查的负担,提高检测效率和准确性。
促进疫情防控:通过实时检测人群中的口罩佩戴情况,可以及时发现未佩戴口罩或口罩佩戴不正确的人员,从而及时采取措施进行防控。这将有助于减少疫情传播的风险,保护人们的生命安全和身体健康。
推动智能化发展:本项目的实施将推动深度学习技术在智能化领域的应用和发展。通过结合其他技术(如人脸识别、行为分析等),可以进一步拓展口罩检测系统的功能和应用范围,为人们带来更加便捷、智能的生活体验。
这篇关于深度学习之基于YOLOV5的口罩检测系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





