本文主要是介绍AIGC岗位需求增长超300%,平均年薪超40万元,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI圈最近又发生了啥?
AIGC 应用爆发,相关岗位需求增长超 300%、平均招聘年薪超 40 万元
随着 AI应用的爆发,生成式人工智能(AIGC)的招聘市场十分火爆。数据显示今年一季度,生成式人工智能相关职位需求同比增长超三倍。从全平台增长较好的职位类别来看,增长率达到 60% 已经算是非常突出的表现了,而 AIGC相关岗位的同比增长超过了 320%

https://www.ithome.com/0/766/415.htm
阿里云发布通义千问2.5,称性能得分追平GPT-4 Turbo
阿里云正式发布了通义千问2.5,模型性能全面赶超GPT-4 Turbo。据了解,通义千问2.5最新开源的1100亿参数模型在多个基准测评中均取得了最佳成绩,成功超越了Meta的Llama-3-70B模型,成为开源领域的新标杆。相比通义千问2.1版本,通义千问2.5在上述四项能力上分别提升了9%、16%、19%和10%,其中文能力更是持续领先业界。在权威基准0penCompass上,通义千问25的得分追平了GPT4 Turbo
https://news.mydrivers.com/1/978/978802.htm
Stack Overflow 宣布与 OpenAl 建立 API 合作伙伴关系
OpenAI 将使用 OverflowAPI 来提高模型性能,并在 ChatGPT 中为 Stack Overflow 社区提供归属。Stack Overflow 将使用 OpenAI 模型开发 OverflowAI,并最大限度地提高模型性能。双方的合作旨在改善两个平台的用户和开发人员体验。第一批集成和功能将于 2024 年上半年推出,合作关系将使 Stack Overflow 能够对社区驱动的功能进行再投资
https://stackoverflow.co/company/press/archive/openai-partnership
谷歌 DeepMind 和 Isomorphic Labs 推出 AlphaFold 3,首发Nature
AlphaFold 3 是一款革命性的模型,能够以前所未有的精确度预测所有生命分子的结构和相互作用
在预测蛋白质与其他分子类型的相互作用方面,它至少比现有预测方法提高了50%的准确率,而对于某些重要的相互作用类别,其预测准确率甚至翻倍。AlphaFold 3 的能力来源于其新一代架构和训练,现在已覆盖所有生命分子
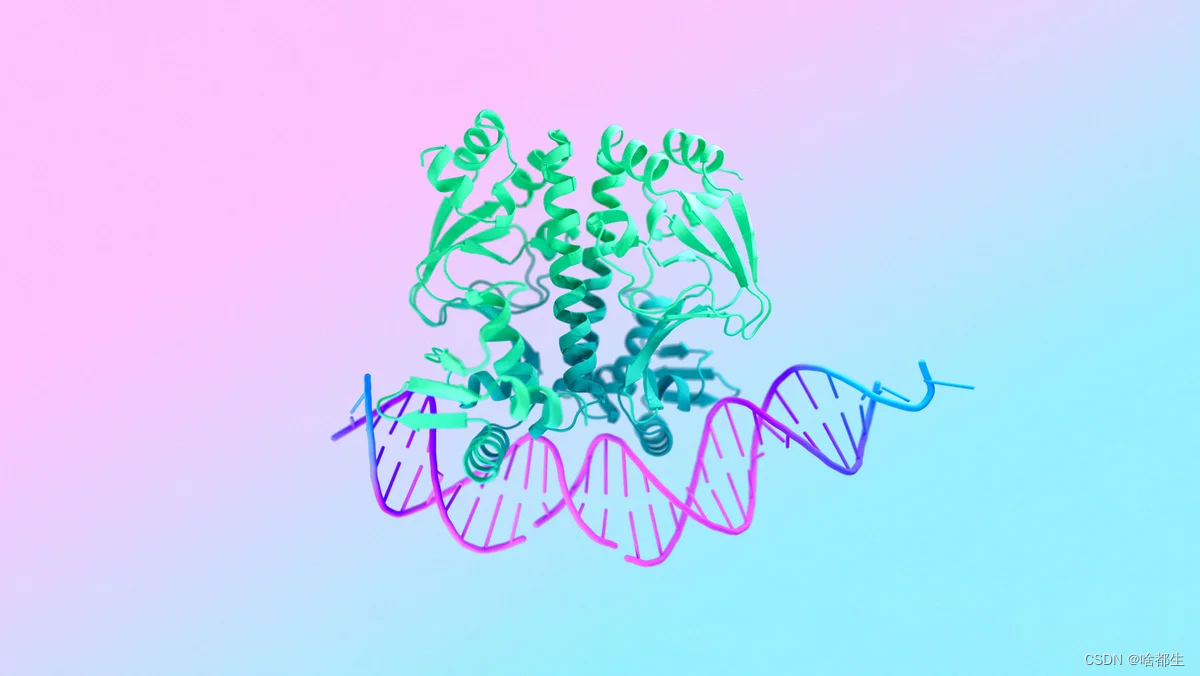
谷歌DeepMind还新推出了AlphaFold服务器。这是一个免费平台,全球科学家均可用于非商业研究。只需点击几下,就能利用AlphaFold 3的强大功能,模拟由蛋白质、DNA、RNA以及一系列配体、离子和化学修饰组成的结构
https://blog.google/technology/ai/google-deepmind-isomorphic-alphafold-3-ai-model/
微软将推出自研AI大模型 MAI-1,同谷歌和 OpenAl 展开竞争
据The Information报道,美国科技巨头微软公司(Microsoft)将推出一款参数达5000亿的全新 AI模型产品,内部称为MAI-1。报道称,MAI-1由前谷歌AI负责人、Inflection CEO穆斯塔法·苏莱曼 (MustafaSuleyman)负责领导开发,将远远大于微软之前训练过的任何小开源模型,约5000亿参数可调整或设置来确定模型在训练期间学习哪些内容,并且它将与Inflection之前发布的Pi模型是分开的。消息人士预计,MAI-1最快在5月举行的微软Build开发者大会上预览这款新模型
https://www.tmtpost.com/7074112.html
苹果新一代 AI PC 芯片 M4 推出,NPU 速度和设备运行速度大幅提升
在“Let freeze”特别新品发布会上,苹果公司正式发布全新iPad Pro,配备全新、专为 AI 打造、基于ARM架构的新一代AI PC芯片Apple Silicon M4。全新M4芯片采用台积电第二代3nm工艺,拥有最高280亿个晶体管,支持全新串联OLED显示引擎,其CPU性能比M2快50%,GPU性能比M2提升4倍,内置全新NPU(新的神经引擎),支持每秒38万亿次 AI计算处理能力,比苹果A11芯片的神经网络引擎快可达60倍(6000%)
https://www.tmtpost.com/7076057.html
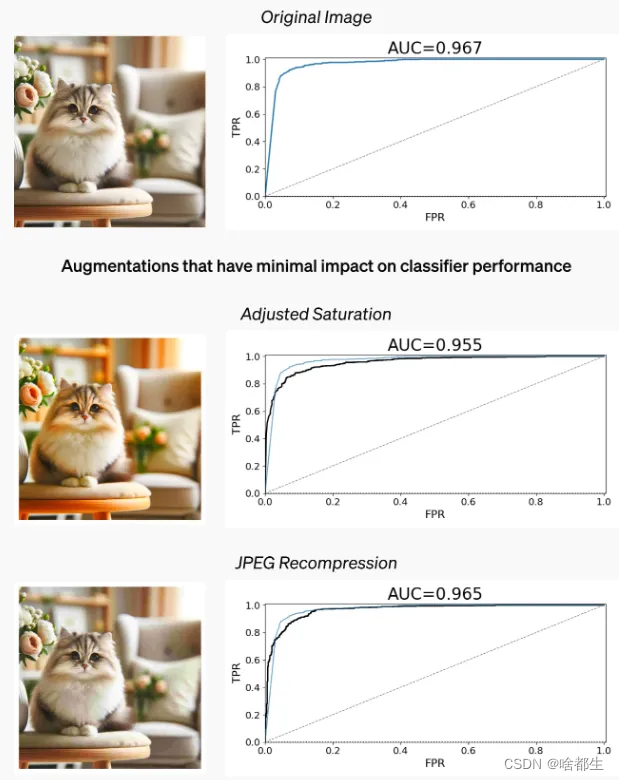
OpenAI 新工具识别DALL-E 3生成图像准确率达98%
OpenAI 开发了一种新工具,用于检测图像是否由其人工智能图像生成器 DALL-E 3 创建。该工具检测 DALL-E 3 图像的准确率约为 98%,即使图像被裁剪、压缩或改变了饱和度也不例外。不过,该工具在检测其他人工智能模型生成的图像方面效果不佳,只能检测出 5-10% 的图像
https://openai.com/index/understanding-the-source-of-what-we-see-and-hear-online
OpenAl 高管:今天的 ChatGPT 将在一年内显得“糟糕得可笑’
OpenAl首席运营官布拉德·莱特卡普 (Brad Lightcap) 近日表示,以 ChatGPT 为代表的生成式 AI 聊天机器人将在未来 12 个月内取得突破性进展,我们现在使用的系统届时将显得糟糕得可笑,莱特卡普补充说,人工智能工具将能够比以往承担更复杂的任务,将成为用户的“绝佳队友”,帮助他们处理“任何给定问题”
https://www.ithome.com/0/766/336.htm
李飞飞最新访谈:并不担心AI末日,对过度炒作AI可能导致人类灭绝感到担忧
华裔人工智能科学家、斯坦福大学教授李飞飞现身旧金山科技峰会,李飞飞表示,公众关注的焦点应转向更为紧迫的问题,如人工智能所引发的虚假信息泛滥。她认为,当前对生成式人工智能技术的普遍“悲观情绪”存在过度渲染之嫌。她直言:“我对于过度炒作人工智能可能导致人类灭绝的风险感到担忧。”
https://new.qq.com/rain/a/20240510A048CQ00
这篇关于AIGC岗位需求增长超300%,平均年薪超40万元的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






