本文主要是介绍AI 绘画神器 Fooocus 高级用法:设置、风格、模型、高级设置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。
大家好,我是水滴~~
本文精选了一系列高级技巧和细致调整,旨在提升 Fooocus 用户在利用 Stable Diffusion 模型进行图像生成时的体验和结果质量。通过深入探讨设置、风格、模型选择以及高级配置选项,我们揭示了如何优化创作过程,并使创意设想更加生动和精准地呈现在画布上。
文章内容包含大量的图例,希望能够帮助新手同学快速入门。
一、设置(Setting)
设置(Setting)主要用于调整生成的预设模型、生成质量、生成图像的宽高比例、出图数量、图片的格式、随机种子以及反射提示词,还可以查看生成的历史记录。
1.1 预设(Preset)
预设(Preset)用于切换不同的大模型。
下面列表为各预设使用的 Base 模型、Refiner 模型、LoRA 模型:
| 预设 | Base 模型 | Refiner 模型 | LoRA 模型 |
|---|---|---|---|
| 初始(initial) | juggernautXL_v8Rundiffusion.safetensors | / | sd_xl_offset_example-lora_1.0.safetensors |
| 动漫(anime) | animaPencilXL_v100.safetensors | / | / |
| 默认(default) | juggernautXL_v8Rundiffusion.safetensors | / | sd_xl_offset_example-lora_1.0.safetensors |
| 极速(lcm) | juggernautXL_v8Rundiffusion.safetensors | / | / |
| 闪电(lightning) | juggernautXL_v8Rundiffusion.safetensors | / | / |
| 写实(realistic) | realisticStockPhoto_v20.safetensors | / | SDXL_FILM_PHOTOGRAPHY_STYLE_BetaV0.4.safetensors |
| SAI(sai) | sd_xl_base_1.0_0.9vae.safetensors | sd_xl_refiner_1.0_0.9vae.safetensors | sd_xl_offset_example-lora_1.0.safetensors |
下面为不同风格预设生成的图片:
初始:

动漫:

默认:

极速:

闪电:

写实:

SAI:

1.2 性能(Performance)
性能(Performance)用于修改生成图片的质量。质量越高,生成的图片越细腻,使用的生成步数也越高。
下面列表为各性能所使用的步数,以及附加的 LoRA 模型:
| 性能 | 步数 | 附加 LoRA 模型 |
|---|---|---|
| 质量(Quality) | 60 | / |
| 速度(Speed) | 30 | / |
| 极速(Extreme Speed) | 8 | sdxl_lcm_lora.safetensors |
| 闪电(Lightning) | 4 | sdxl_lightning_4step_lora.safetensors |
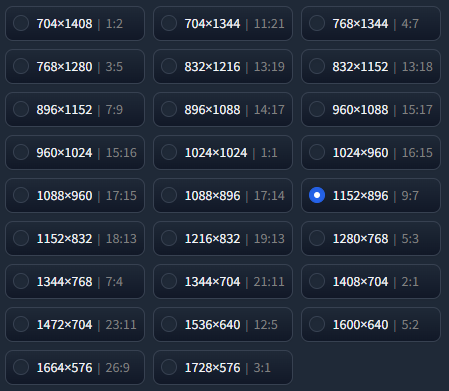
1.3 宽高比例(Aspect Ratios)
宽高比例(Aspect Ratios)用于修改生成图片的宽高比例像素数,可以根据自己的需要来修改。
1.4 出图数量(Image Number)
出图数量(Image Number)表示为一次生成的图像数量。选择范围为
1~32,默认为2。

1.5 输出格式(Output Format)
输出格式(Output Format)表示生成图片的格式。主要有
png(默认)、jpeg和webp。
1.6 反向提示词(Negative Prompt)
反向提示词(Negative Prompt)用于输入反向提示词。正向提示词用于描述你想看到的内容,而反射提示词用于描述你不想看到的内容。
1.7 随机种子(Random)
随机种子(Random)用于固定随机种子。Stable Diffusion 生成的图像都是随机的,通过固定随机种子可以生成相同的图片。
当勾选后,表示使用随机种子:

当取消勾选后,表示使用固定种子;默认使用上次生成图片的种子,也可以自己修改:
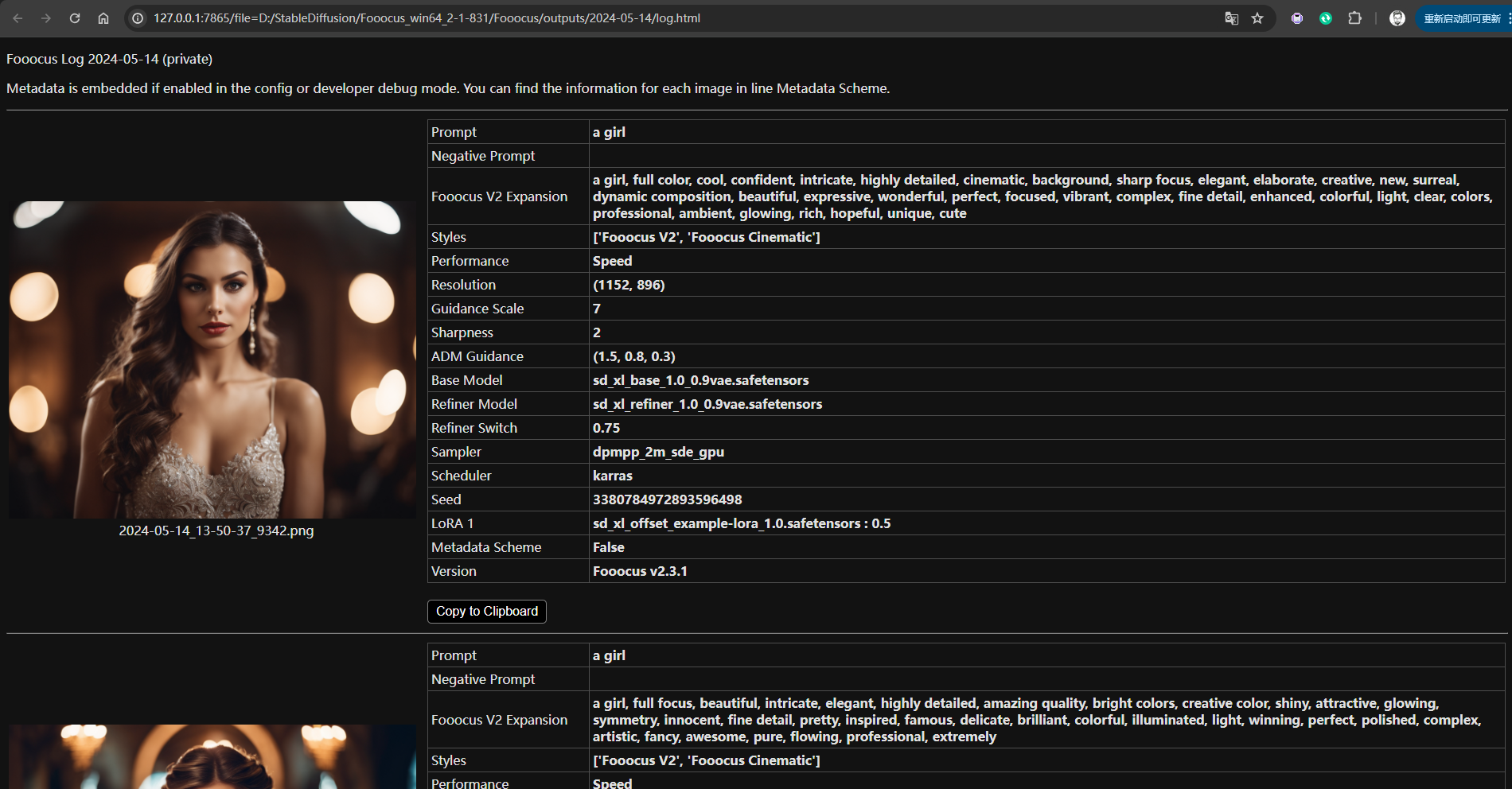
1.8 历史记录(History Log)
历史记录(History Log)用于查看生成图片的记录,内容还包括生成信息。
默认查看当天的生成记录,可以通过修改地址中的日期来选择其它日期的记录:
二、风格(Style)
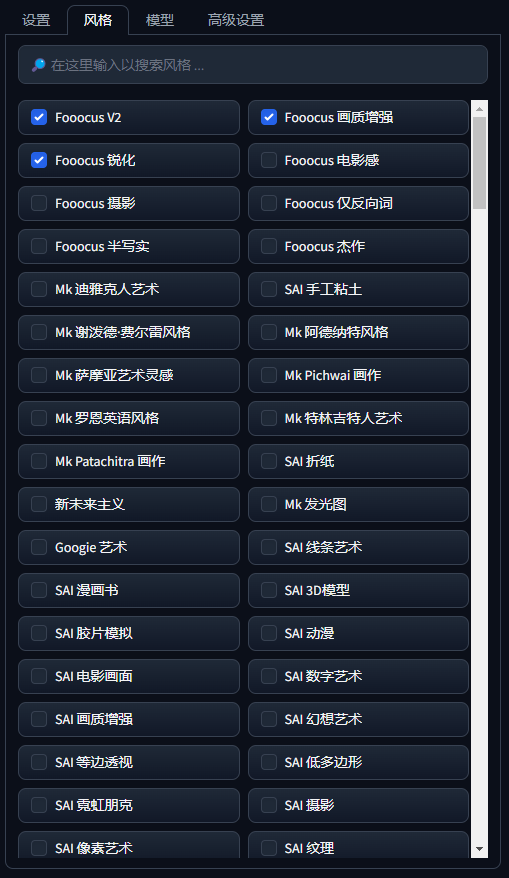
风格(Style)用于选择生成图像的风格。Fooocus 内置了 100 多种风格,这些风格可以自由组合使用,不影响生成的图片质量。
在这些风格中,“Fooocus V2”是一种非常独特的动态风格,它使用 AI(GPT2)自应用地添加风格,使图像更具吸引力。
下面为风格列表:
下面为各风格的示例图:
三、模型(Model)
模型(Model)用于修改模型,可以修改 Base 模型、Refiner 模型、LoRA 模型。
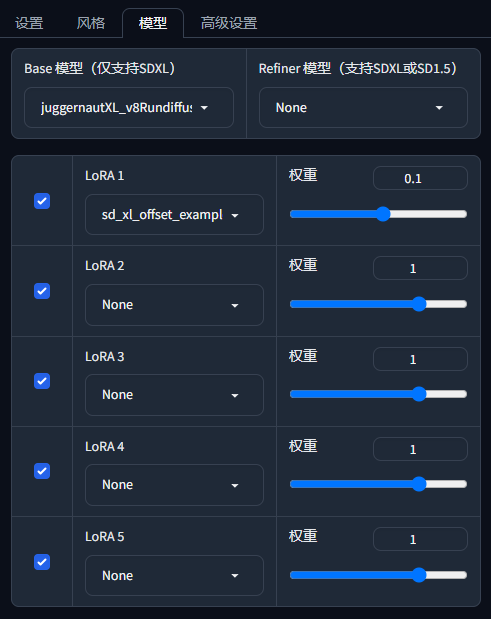
3.1 Base 模型(Base Model)
Base 模型(Base Model)又叫大模型、主模型等,是 AI 生成图片的基石。主流的大模型版本有 SD1.5 和 SDXL,Fooocus 仅支持 SDXL。
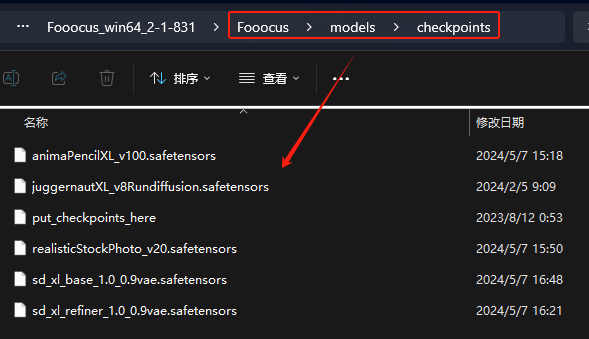
我们还可以下载自己喜欢的大模型,然后将其放到 Fooocus\models\checkpoints 目录,刷新后就可以选择了:
3.2 Refiner 模型
Refiner 模型是一种精炼模型,可以提升基础模型的质量。很多大模型已经不需要额外的 Refiner 模型了,如果需要作用会附加说明。
Refiner 模型的存放的位置了是 Fooocus\models\checkpoints 目录。
3.3 LoRA 模型
LoRA 模型是一种轻量级的扩散模型,用于对标准的
Checkpoint模型进行微调,可以调整图像的风格、光线、细节等。
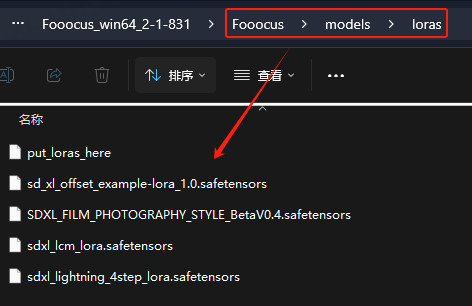
我们还可以下载其它 LoRA 模型,然后将其放到 Fooocus\models\loras目录,刷新后就可以选择了:
四、高级设置(Advanced)
高级设置(Advanced)用于设置提示词引导系数和图像锐度。
4.1 提示词引导系数(Guidance Scale)
提示词引导系数(Guidance Scale)数值越高,风格越简洁、生动、更具艺术感(LCM时为1~2)。取值范围为
1~30,默认值为6。
下图值为6生成的图片:

下图值为16生成的图片:

4.2 图像锐度(Image Sharpness)
图像锐度(Image Sharpness)数值越高,图像和纹理越清晰(LCM时为0)。取值范围为
0~30,默认值为2。
下图为值为20生成的图片:

这篇关于AI 绘画神器 Fooocus 高级用法:设置、风格、模型、高级设置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








