本文主要是介绍ElastiCache Serverless for Redis应用场景和性能成本分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. 前言
传统基于实例节点的 Redis 缓存架构中,扩展性是一个重要影响因素。在很多场景中,例如广告投放、电商交易、游戏对战,流量是经常变化的。无论是主从还是集群模式,当大流量进入时,Redis 处理能力达到上限,需要扩容。Amazon Elasticache 支持纵向和横向扩展。纵向扩展是修改节点类型,提高 CPU/内存容量。横向扩展是增加只读节点,或者在集群模式下增加分片数量。无论哪种扩展都可以在线进行,但是,扩展过程中,数据会复制到新集群再替换原有集群,此过程时间消耗会比较长,根据数据量,几十分钟到几小时不等。如果有分片变化,还需要数据重平衡。缩减也是如此,当流量高峰过去之后,为了节省成本,需要降低实例类型,或者减少分片。扩容和缩减过程过长,影响 Redis 性能,除非迫不得已,大多数客户不会对缓存进行在线修改,而是采用最大流量时的高配置,来满足业务需求。高配置实例集群,虽然可以支撑大流量,但是需要更高成本,在业务低谷期时,也需要保持高水位的实例集群配置,这部分成本就会浪费。
有没有方案,可以在业务流量变化很大的情况下,快速扩容或者缩减,满足业务的同时,也能降低成本?Amazon Elasticache Serverless 就是为此而生。
使用 ElastiCache Serverless,无需管理基础设施和容量即提高应用程序性能,从而节省数小时的时间。不到一分钟的时间内设置新缓存,而无需选择缓存节点类型、分片数量、副本数量或跨可用区的节点位置。ElastiCache Serverless 可持续监控缓存的内存、计算和网络利用率,并即时扩展以适应应用程序流量。ElastiCache Serverless 提供单个端点体验,可简化整体客户端配置,减少应用程序中断,客户端无需在维护或扩展事件期间处理集群拓扑的变化。简单的说, ElastiCache Serverless 在流量波峰低谷明显时,可以降低成本,更加平滑扩展,而且完全无需运维。
本篇博客会介绍 ElastiCache Serverless 的应用场景、技术实现、性能测试以及成本分析,方便客户根据自己情况选择。
完整文章来源:ElastiCache Serverless for Redis应用场景和性能成本分析-国外VPS网站本篇博客会介绍ElastiCache Serverless 的应用场景、技术实现、性能测试以及成本分析,方便客户根据自己情况选择。![]() https://www.vps911.com/gwvpstj/2021.html
https://www.vps911.com/gwvpstj/2021.html
二. 应用场景
ElastiCache Serverless 适合以下场景:
- 流量负载频繁波动:例如电商大促或秒杀,游戏推广,汽车车联网数据访问,餐饮行业
- 新业务上线,并且不能预知线上负载
- 降低运维管理
三. 技术架构
ElastiCache Serverless 相比 Amazon Elasticache 实例模式,可以自动监控内存、CPU、网络指标,按照流量迅速扩展,过程更加丝滑,并且按照实际使用量收费,无需大流量时增加过多成本。对于应用程序提供统一的访问节点,即使底层节点发生故障而自动切换,导致拓扑改变,也无需修改应用程序客户端。
下面描述 ElastiCache Serverless 的底层架构。
|
|
|
|
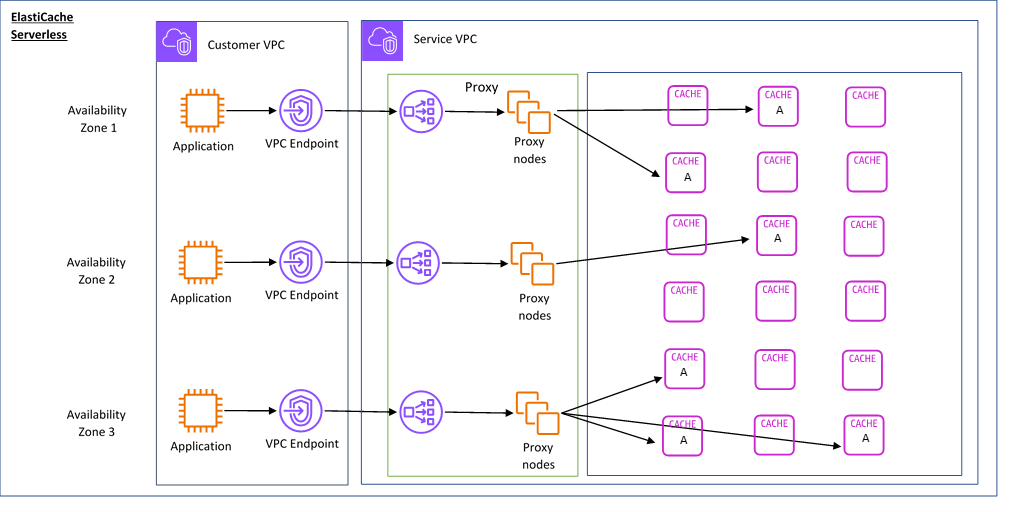
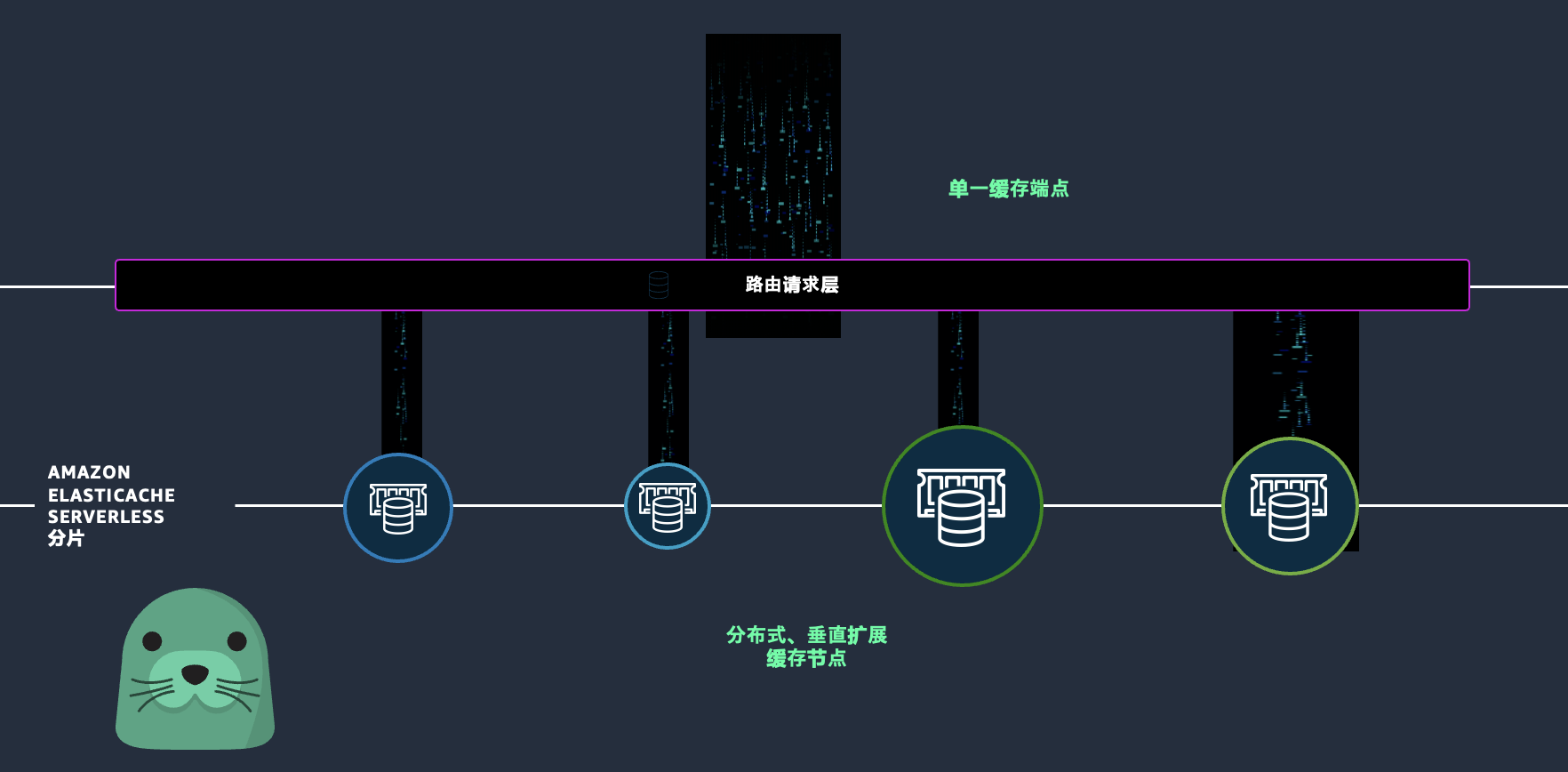
在此架构中,ElastiCache Serverless 提供了统一的访问端点,所有应用程序客户端以集群方式访问 ElastiCache Serverless 集群,例如 test-serveless-0uiite.serverless.use1.cache.amazonaws.com:6379 。内置的代理层接收到请求,把请求负载均衡转发到缓存节点。代理层本身可以跨可用区实现高可用,缓存节点以分片形式组织,每个分片跨可用区主从复制高可用。每个缓存分片,可以快速动态垂直扩展,当到达分片上限时,可以横向增加分片扩展。缓存节点使用了 Caspian 虚拟化管理软件和热管理系统,Caspian 使用超配内存,为每个数据库所在的虚拟机,分配和物理宿主机一样大小的内存,例如 256GB,但是实际使用只是数据库所申请的内存大小,例如 16GB。随着负载变化,内存可以迅速多次无缝扩展,应用无感知。当物理机上的多个数据库已经使用了所有物理内存并且需要申请更多内存的时候,Caspian 会把其中一个实例热迁移到另外的物理机,再给申请的数据库扩容内存。
四. 性能评估
性能方面,ElastiCache Serverless 可以支撑百万级别 RPS,可以达到读取 700 微秒以及写入 1 毫秒的平均延迟,并且还能扩展到最高 5TB 内存容量。
4.1 性能测试结论
- 伸缩性。在请求突增的情况下,Elasticache Serverless 会自动扩展,可能开始时会有延迟的增加 ,之后回落到一致的水平;ElastiCache Serverless 在百万级别高并发请求下,仍然能保持比较一致的响应延迟。
- 预伸缩(pre-scaling)。对于请求突增幅度较大的情况, ElastiCache Serverless 的延迟增加会较为敏感,可能延迟会增加到几毫秒左右。可以通过预设 ElastiCache Serverless 的最小指标来完成。比如最小请求速率、最小存储容量等。ElastiCache Serverless 会事先扩充资源进行负载支撑。
- 稳定性。ElastiCache Serverless 对于平稳负载,运行稳定,没有性能突变。
- 请求数据量与 ECPU 的关系。对于简单类型的 SET/GET 指令,可以通过 SET/GET 操作来推算 ECPU 消耗:数据小于 1KB 时,ECPU 和 SET/GET 操作数相等,直接根据操作数来推演;数据大于 1KB 时, ECPU 大于 SET/GET 操作数,ECPU=操作数*数据大小/1KB。注意评估 GET 的数据量大小时要查看缓存命中率,没有命中的 GET 操作返回 NULL,ECPU 可以记为 1。
具体四项测试的内容如下。
4.2 测试 1: 伸缩性测试
ElastiCache Serverless 能够根据工作负载的变化自动伸缩,本测试主要关注在 ElastiCache Serverless 的伸缩能力。
测试方法:
分别在 1 到 8 个 EC2 机器运行 memtier 测试工具 30 分钟,观察请求数增加时,Elasticache serverless Redis 读写延迟
测试环境:
Client: 1 – 8 EC2 m6i.xlarge
Elasticache Serverless 7.1
测试负载:
通过 Memtier 进行压测,通过控制多台 EC2 机器来增加对 ElastiCache Serverless 的并发访问。每台 EC2 客户端运行 Memtier,输入的参数为:8 线程、单线程建立 50 个连接、单条命令操作数据大小为 500 字节、写读比例为 1:10、运行 1800 秒(30 分钟)。具体命令如下:
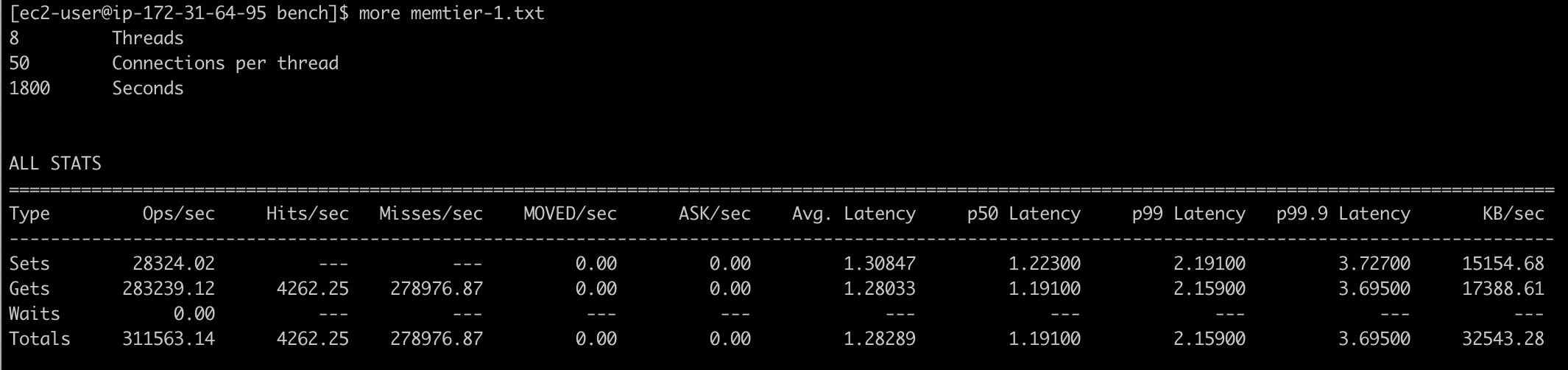
memtier_benchmark -s ping-serveless-0uiite.serverless.use1.cache.amazonaws.com -p 6379 --tls --tls-skip-verify --cluster-mode -c 50 -R -d 500 -t 8 --ratio=1:10 --test-time=1800 --out-file=memtier-1.txt测试结果:
本压测过程运行了 4 组测试。每组测试对应的 EC2 节点数据分别为 1,2,4,8,即每次都以负载加倍的方式来运行。每个 EC2 节点到 memtier 返回的统计信息显示 SET 的 RPS 为 28K 左右,GET 的 RPS 为 280K 左右,读写延迟为 1.3ms 左右,变化不大。8 个客户端总共约 2400K RPS,每秒超过 2 百万请求速率,总体表现相对稳定。
|
|
观察 Elasticache Serverless 服务性能指标:
|
|
主要观察指标如下:
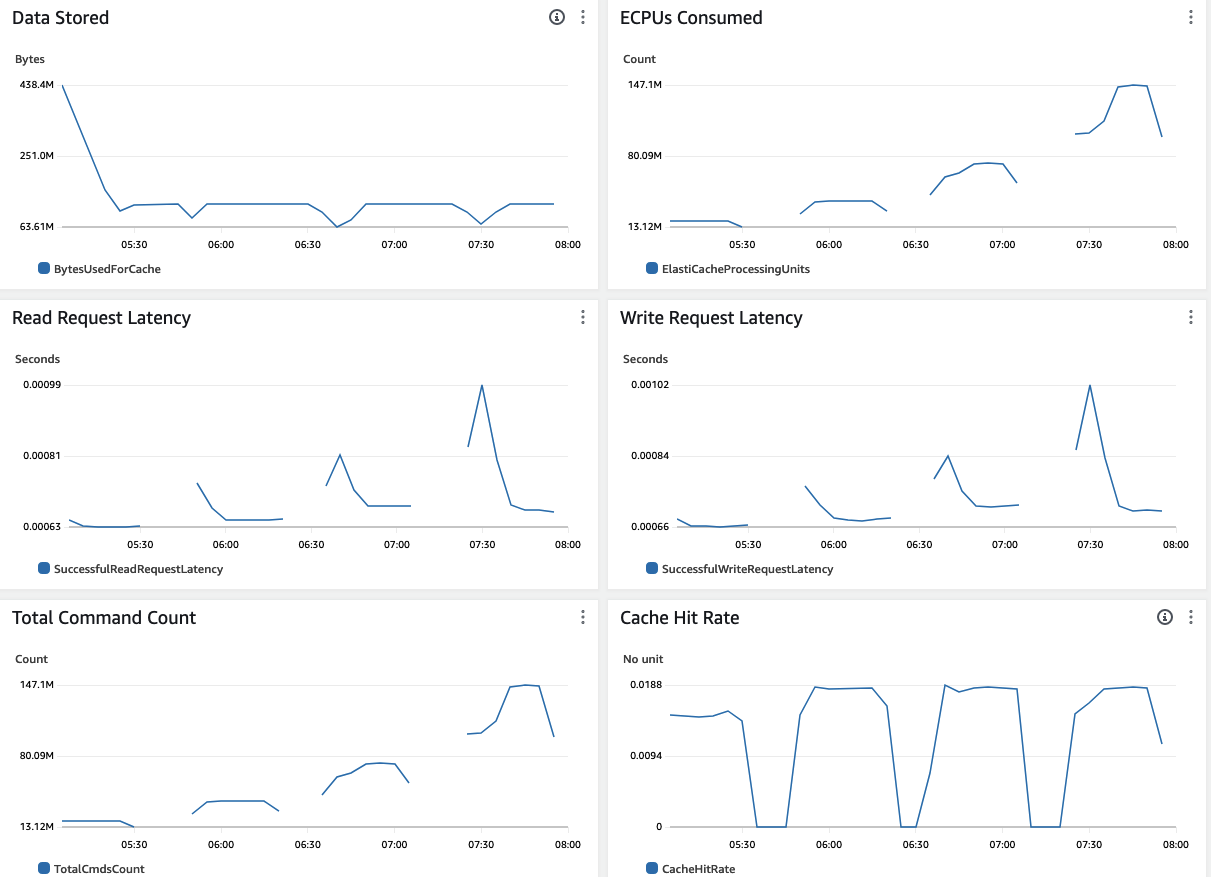
- ECPU:与请求数和每个请求的数据量相关,当 Redis KV 数据小于 1KB 时,ECPU 等同于请求数,从指标中我们可以看到 ECPU 和 Total Commands Count 曲线的完全吻合。随着压测过程的 4 组测试流量的进入, ECPU 和 Total Commands Count 的值随之翻倍,形成 4 个 ECPU 消耗高峰,最高 147M。ECPU 统计的是每分钟的 ECPU 数目,和 Memtier 返回结果每秒 4M 多个请求是相符的。
- 读写请求延迟(Read/Write Request Latency):每次新的大量请求进来,前几分钟左右会有短暂的约 200 微秒延迟升高,之后回落到 700 微秒左右的读写延迟。一开始延迟升高,底层节点正在扩展,完成后恢复到稳定的读写延迟水平(0.63-0.71ms)。因为 EC2 的 Memtier 是在客户端统计时间,读写延迟会比 ElastiCache 中的指标稍高。
- 缓存命中率(Cache Hit Rate):此测试中由于 memtier 设置了随机数据,读取尚未写入的 Key 就会 Miss,从客户端压测结果也能看到大量的 MISS,因此缓存命中率很低。正常情况下,大部分数据应该位于缓存。客户可以使用模拟真实环境的测试数据和程序来压测,会有更高的缓存命中率。
测试结论:
在请求突增的情况下,Elasticache Serverless 会自动扩展,可能开始时会有延迟的增加 ,之后回落到一致的水平;ElastiCache Serverless 在百万级别高并发请求下,仍然能保持比较一致的响应延迟。
需要注意的是,Elasticache Serverless 虽然可以快速扩展,但是仍然要遵循 Redis 最佳实践,避免大 Key 和热 Key,过分倾斜的数据分片,仍然会影响整体性能。
4.3 测试 2: 预伸缩能力测试
ElastiCache Serverless 的空缓存支持每秒 30K ECPU,如果使用了读写分离,最多可以支持到每秒 90K ECPU。当负载需要的 ECPU 数目超过当前集群的承载能力时,ElastiCache Serverless 可以进行横向扩展,每 10-12 分钟可以将每秒承载的 ECPU 翻番。对于流量双倍的负载,比如测试 1 的负载,ElastiCacheServerless 可以满足需求。 但如果预计流量扩展倍数较高,比如零点大促、新游戏发布等,双倍容量扩容可能会带来延迟增加、请求受限。针对这种情况,您可以使用 ElastiCache 的预扩展功能,提前设置最小使用量为预计的峰值。这样,ElastiCache Serverless 会根据设定的最小使用量将集群扩容,以满足突发流量。建议您在峰值事件发生 60 分钟前进行设置。
您可以在创建或者修改 ElastiCache Serverless 集群时,设定或者更改存储或者请求的最小期望值。当预期峰值过去后,可以调整到一个比较小的取值。
|
|
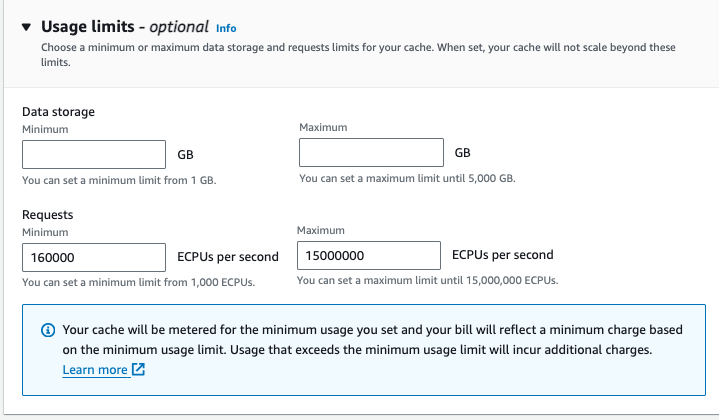
本测试验证两个不同的 ElastiCache Serverless 集群上运行相同负载的性能表现。
测试方法:
在同一台 EC2 机器,先后调用两个不同的 ElastiCache Serverless 集群,通过 Memtier 测试工具产生每秒 160K 的请求负载,运行 30 分钟。观察 ECPU、读写延迟。
测试环境:
EC2:c5a.16xlarge
ElastiCache Serverless 集群 1: 默认配置
ElastiCache Serverless 集群 2: Request 最小值设置为每秒 ECPU160K
测试负载:
通过 Memtier 进行压测,在一台 EC2 机器上进行 Memtier 压测,输入的参数为:4 线程、单线程建立 50 个连接、单条命令操作数据大小为 100 字节、写读比例为 10:1、运行 1800 秒(30 分钟)。具体命令如下:
memtier_benchmark -s elasticacheserverless-default-new-og91gz.serverless.use1.cache.amazonaws.com -p 6379 —tls —tls-skip-verify —cluster-mode -c 50 -R -d 100 -t 4 —ratio=10:1 —test-time=1800 —out-file=memtier-lowstart-new.txt测试结果:
Memtier 的返回结果
集群 1(默认配置)
|
|

集群 2 (最小 ECPU 为 160K/s)
|
|

ElastiCache 集群的指标信息
集群 1(默认配置)
|
|
|

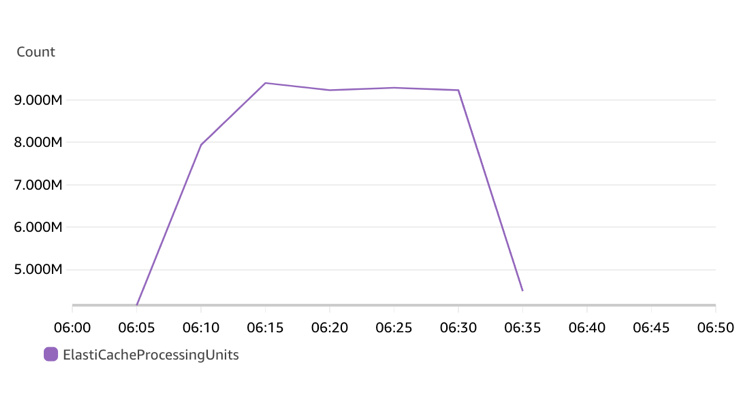
集群 2(最小 ECPU 设置为 160K/s)
|
|
|
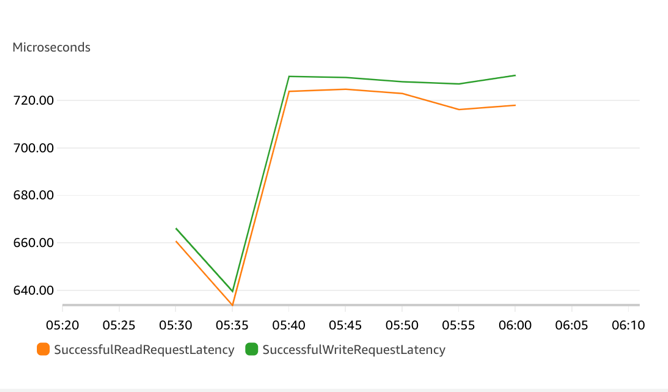
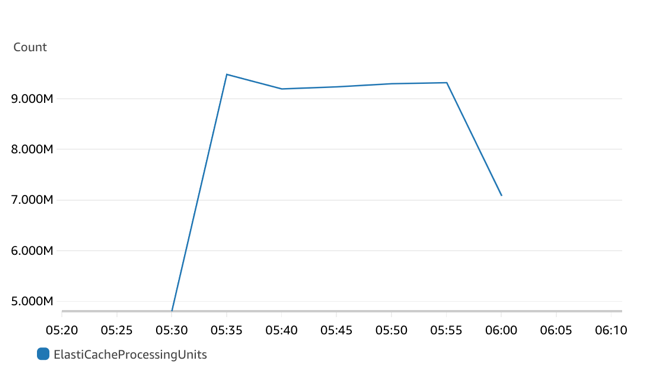
对于集群 1,开始时是空集群,最大处理能力为 30K ECPU/s。在压力突然加到每秒大概 150K 的情况下,ElastiCache Serverless 集群响应延迟会较高(读写均到达 3 毫秒),随着时间推移,在 10 分钟以后,延迟会逐步恢复正常(700 微秒左右)。因为集群开始受限,对命令的请求数目和 ECPU 增长会相对缓慢。
对于集群 2,同样开始时也是空集群,但因为创建集群时指定了最小 ECPU 为 160K/s,所以空集群的当前处理能力为 160K ECPU/s。在压力加到每秒 150K 的情况下,当前集群无需扩展,可以承接压力,所以读写延迟在 600-700 微秒左右,ECPU 增长也会相对到期望范围。读写请求延迟差别不大,写请求延迟稍大。
测试结论:
对于请求突增幅度较大的情况下, ElastiCache Serverless 的延迟增加会较为敏感,可能延迟会增加到几毫秒左右。可以通过预设 ElastiCache Serverless 的最小指标来完成。比如最小请求速率、最小存储容量等。ElastiCache Serverless 会事先扩充资源进行负载支撑。
使用 Pre-scaling 需要注意两点:
- 提前设置的时间。尽管我们测试时创建空集群时指定最小 ECPU 的方式,集群也是在 1 分钟左右建好,还是建议您留好集群扩容的时间,最好是提前 60 分钟设置。
- 成本。即便实际使用量小于设定的最小 ECPU/存储,也会按照最小 ECPU/存储收取费用。因此,建议您在业务峰值过后,及时调低最小值设定。
4.4 测试 3: 稳定性测试
测试方法:
使用 8 台 EC2 节点,每个节点同时运行 memtier 测试工具,共计 4 小时,保持稳定请求量。
测试环境:
与测试 1 相同。
测试负载:
与测试 1 相同。
测试结果:
Elasticache Serverless 监控指标如下。
|
|
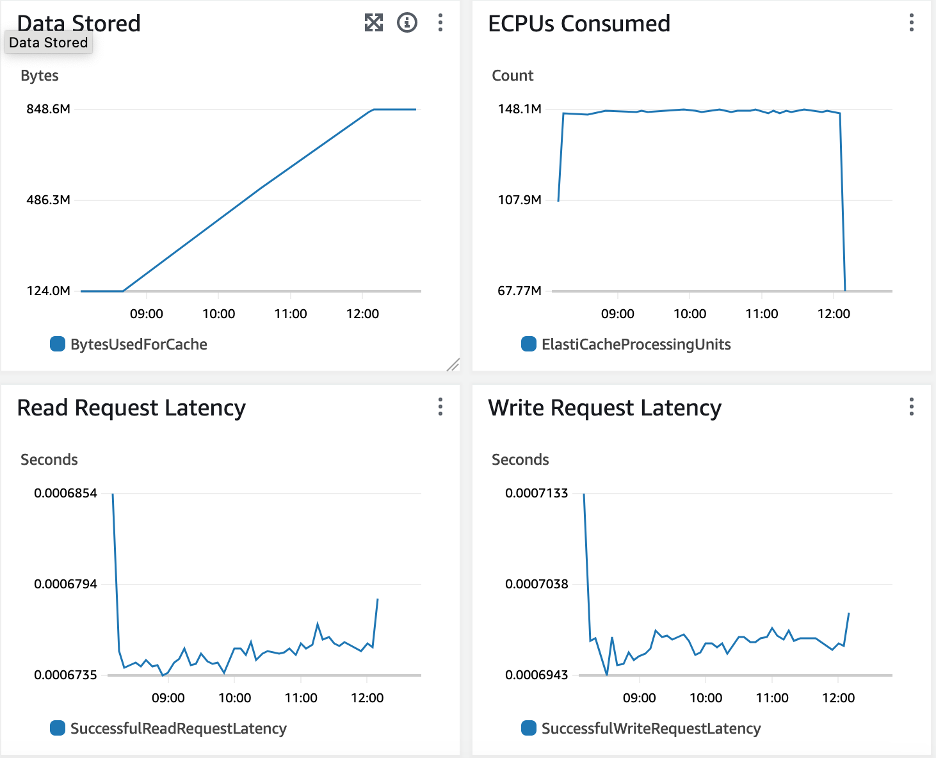
ECPU 一直稳定在 147M,读延迟平均 0.67-0.69ms,写平均延迟 0.69-0.70ms,整体很稳定。
测试结论:
ElastiCache Serverless 对于平稳负载,运行稳定,没有性能突变。
4.5 测试 4: 请求数据量与 ECPU 的关系
Elasticache Serverless ECPU 与数据大小相关,当 SET/GET 的请求小于或者等于 1KB 时,ECPU 消耗为 1;大于 1KB 时,每 1KB 数据对应 1 个 ECPU,比如请求大小为 3.4KB,那么 ECPU 为 3.4。本测试主要来验证 ECPU 与请求数据量大小的关系。
测试方法:
在一个 EC2 客户端,给 ElastiCache Serverless 发送不同的 Memtier 负载,在 Memtier 负载中设置不同的单个请求数据大小,观察 ECPU 数值。
测试环境:
与测试 1 相同。
测试负载:
通过 Memtier 进行压测,在 1 台 EC2 机器上,运行 2 组不同的 Memtier 负载,设置数据大小分别为 100 字节和 3200 字节。Memtier 的输入参数为:4 线程、单线程建立 50 个连接、单条命令操作数据大小分别为 100B/3.2KB、随机数据、写读比例为 1:10、运行 1800 秒。设置为 100B 的命令如下:
memtier_benchmark -s test-serveless-0uiite.serverless.use1.cache.amazonaws.com -p 6379 --tls --tls-skip-verify --cluster-mode -c 50 -R -d 100 -t 4 --ratio=1:10 --test-time=1800 --out-file=memtier-100-50.txt测试结果:
数据大小为 100B 的情况
|
|
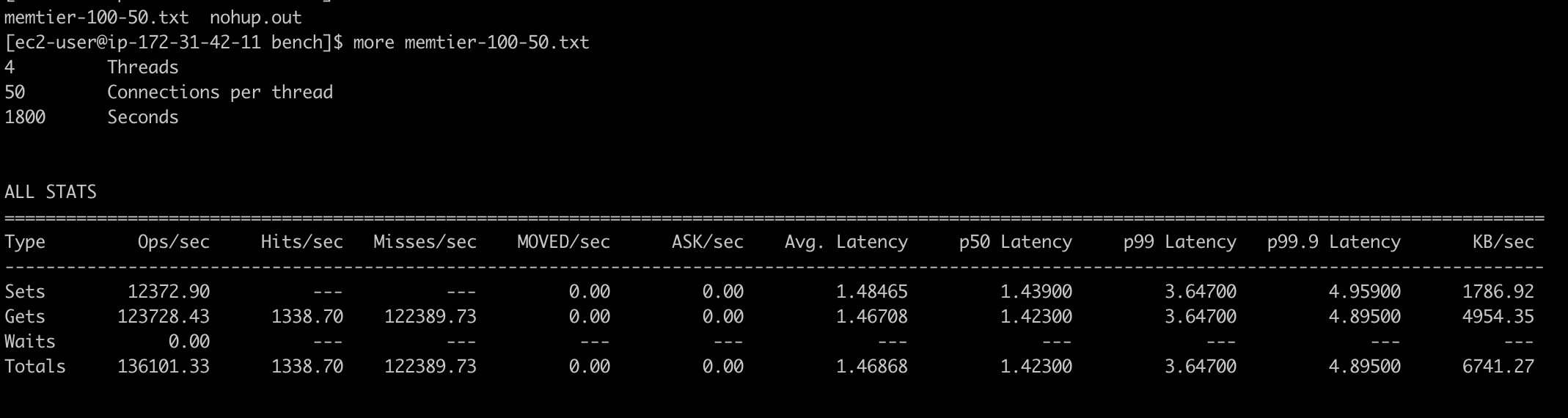
测试时间 30 分钟内,ECPU 总数大约 245.8M。
Memtier 结果显示,平均每秒 136101.33个SET/GET 操作,计算 30 分钟内操作数 244982394。此数值和 ECPU 非常接近。
数据大小为 3.2KB 的情况:
|
|
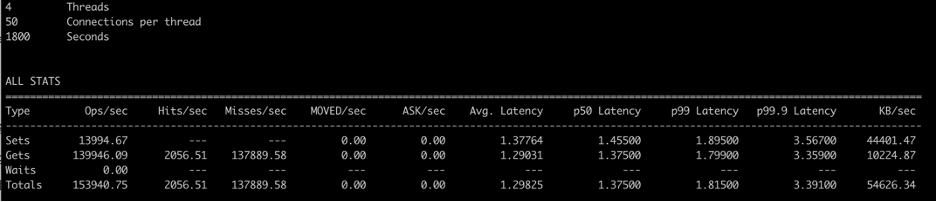
测试时间 30 分钟内,ECPU 总数大约 336M。
Memtier 结果显示,平均每秒 153940 个 SET/GET 操作,SET 数目为 13994,GET 数目为 139946,但这里需要注意的点是因为是随机数据读取,此负载 Cache Miss 情况较多,Cache Hit 数目为 2057,Cache Miss 数目为 137890。对于 Cache Miss 的情况,GET 操作实际是没有数据返回的,应该计入 1 个 ECPU,而非 3.2ECPU。从 Memtier 的 SET/GET 情况推算 ECPU 的消耗:
Set: 13994*1800(秒)*3.2=80,605,440
Get hit: 2057*1800(秒)*3.2=11,848,320
Get miss: 137890*1800(秒)*1=248,202,000
总计 341M,与实际 Elasticache Serverless ECPU 336M 非常接近。
测试结论:
通过 SET/GET 操作来推算 ECPU 消耗,可以采用下面逻辑:
- 数据小于 1KB 时,ECPU 和 SET/GET 操作数相等,直接根据操作数和大小来推演。
- 数据大于 1KB 时, ECPU 大于 SET/GET 操作数,ECPU=操作数*数据大小/1KB。
- 如果有 MISS,每个 MISS 计费为 1 ECPU,ECPU=(写+读 HIT)* 数据大小/1KB+读 MISS
此外需要注意的是, ECPU 消耗通常有两个可能的方面:1)网络数据传输量;2)运行指令时消耗的 vCPU 容量。对于简单的 String 类型的 SET/GET 操作,通常 ECPU 和网络数据大小的关系正如本测试验证的一样。对于比较复杂的数据结构,比如 SortedSets、Hashes,或者较复杂的 Lua 脚本执行,ECPU 的消耗也会受 ElastiCache Serverless 运行指令的时间影响。
五. 成本评估
Elasticache Serverless 成本由两部分构成: ECPU 和内存使用量。
ElastiCache 处理单元(ECPU):包括 vCPU 时间和传输的数据。对于传输的每千字节(KB)数据,读取和写入需要 1 个 ECPU。例如,传输 3.2 KB 数据的 GET 命令将消耗 3.2 个 ECPU。如果单条传输的数据数量不足 1KB,ECPU 以 1 为计算。
存储数据量对应 Elasticache Cloudwatch 指标 BytesUsedForCache,估算每天平均内存使用量。这里需要注意,Elasticache Serverless 存储成本按照 GB/小时计算。为了降低成本,需要设置合理的 Redis 过期淘汰策略,避免长期不用的数据占用内存。相比实例模式下,成本按照实例计算,Serverless 需要更精细的使用方式来降低成本。
5.1 成本估算模型
如果您对业务比较熟悉,知道每个请求大概传输的数据量,可以采用下面的成本计算模型进行大致成本估算。
|
|
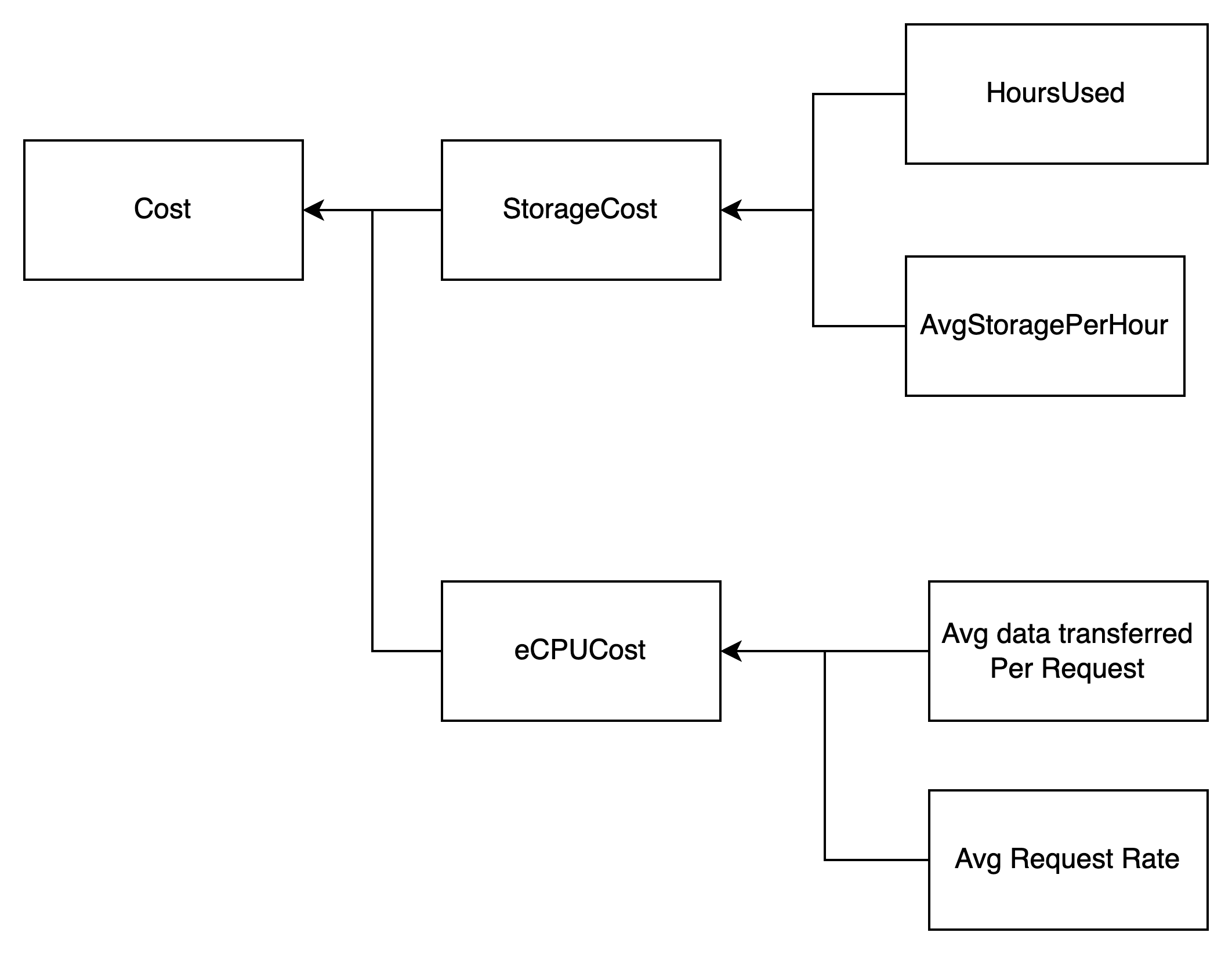
总结成公式就是:
ElastiCache Serverless 成本=平均每小时存储数据量*占用小时数+平均请求速率*每个请求传输的平均数据量/1KB(小于 1KB,以 1 计算,大于 1KB,直接取商)
如果您希望从现有的 ElastiCache 集群的指标中直接评估,您也可以通过下面的方式来计算:
|
|
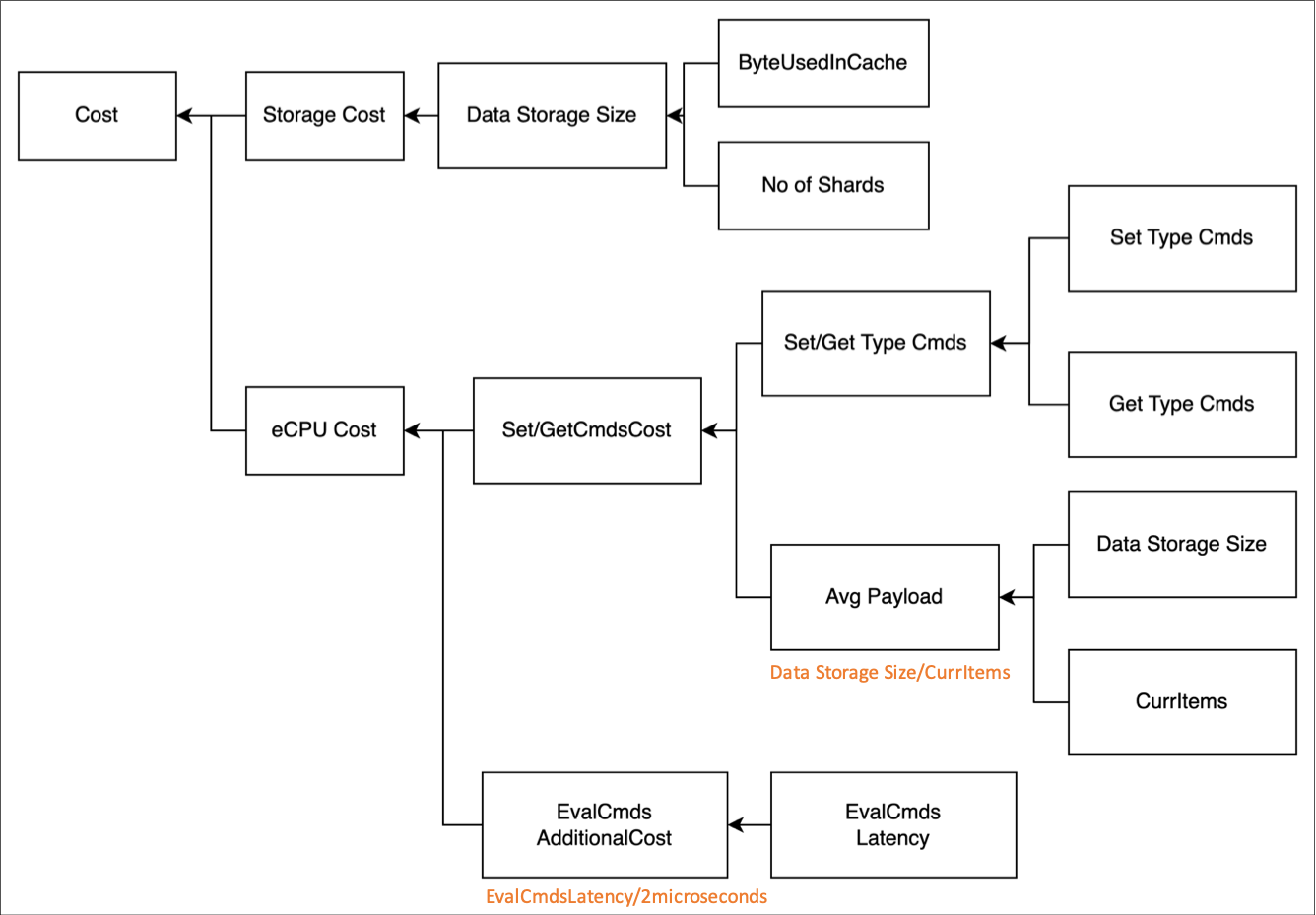
总结成公式就是
ElastiCache Serverless 成本
=存储成本+ECPU 成本
=存储成本 + 简单 SET/GET 消耗 ECPU 成本(主要在传输)+复杂脚本执行额外消耗 ECPU 成本(主要在 vcpu)
=存储成本 + SET/GET 命令数*平均请求负载量 +复杂脚本平均执行时间/消耗一个 ECPU 的平均执行时间
=存储成本 + SET/GET 命令数*存储容量/集群中 Item 数目 +复杂脚本平均执行时间/2 微秒(经验值,可以通过历史信息来估算)
= BytesUsedForCache*shardNum +(SetTypeCmds+GetTypeCmds)* ByteUsedForCache*shardNum/CurrItem+EvalCmdsLatency/2microseconds
对于平均请求负载量,除了用存储容量/集群中 Item 总数计算外,也可以通过传输的数据总量除以运行的命令总数来计算。
|
|

总结成公式就是
平均请求负载量
=数据传输量/请求数
=(NetworkBytesIn+NetworkBytesOut-ReplicationBytes)*NoOfReplicas /(GetTypeCmds+SetTypeCmds+EvalCmds)
5.2 成本估算示例
如果某个时期内,业务波峰低谷明显,相差几倍以上,而且低谷时期流量很低,高峰时期持续时间不长,此时 ElastiCache Serverless 可能成本更低。
下面展示一个根据 ElastiCache for Redis 标准集群模式的实际指标评估 ElastiCache Serverless 是否能够节约成本的实例。
计算示例价格以美国东部 us-east-1 为准 。
以下是 Amazon Elasticache Redis 某个实例集群一天的 CPU 使用率监控指标。
|
|
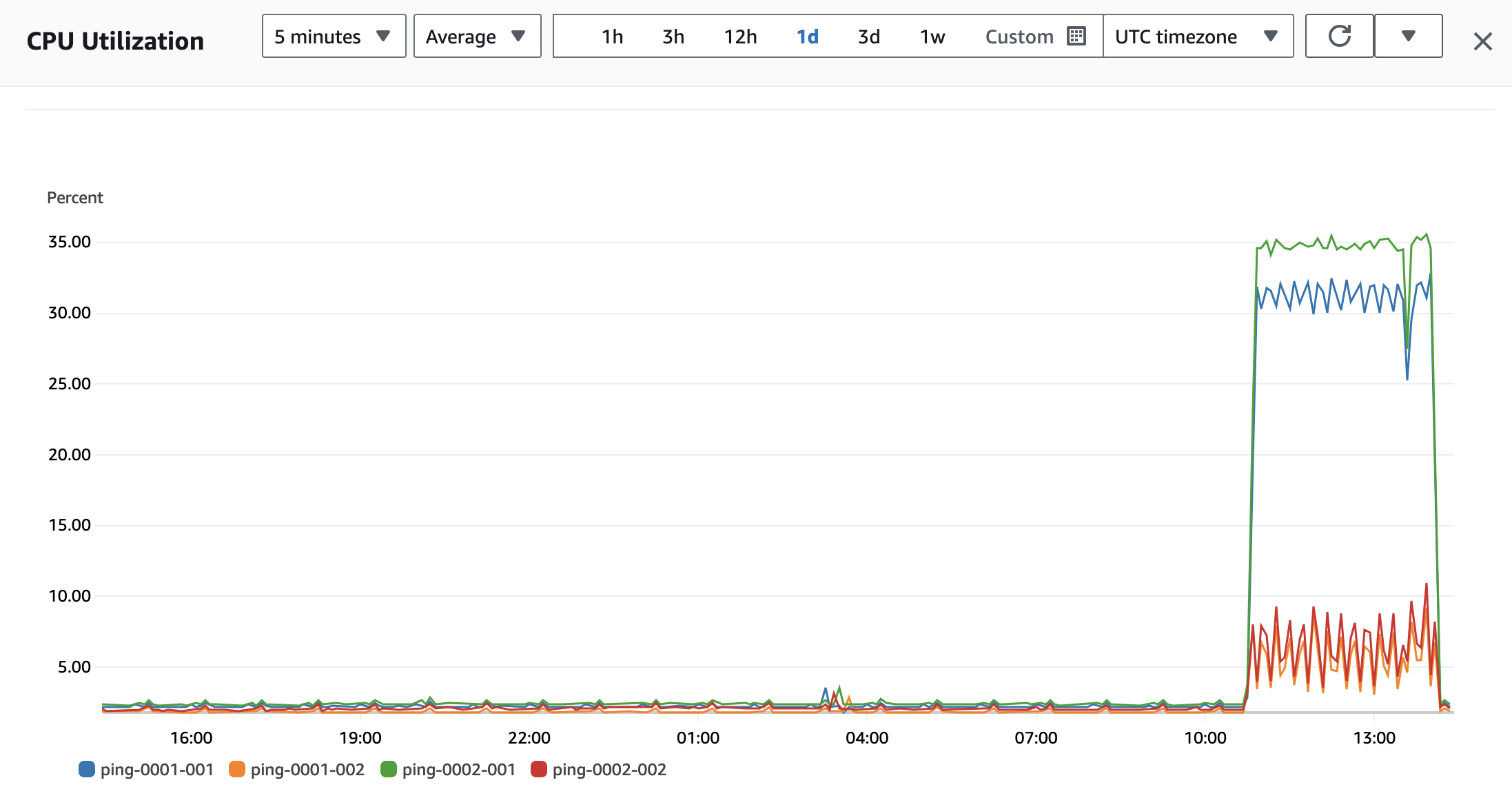
高峰期持续约 3 小时,其余时段资源利用率很低,初步判断可以使用 Serverless 降低成本。
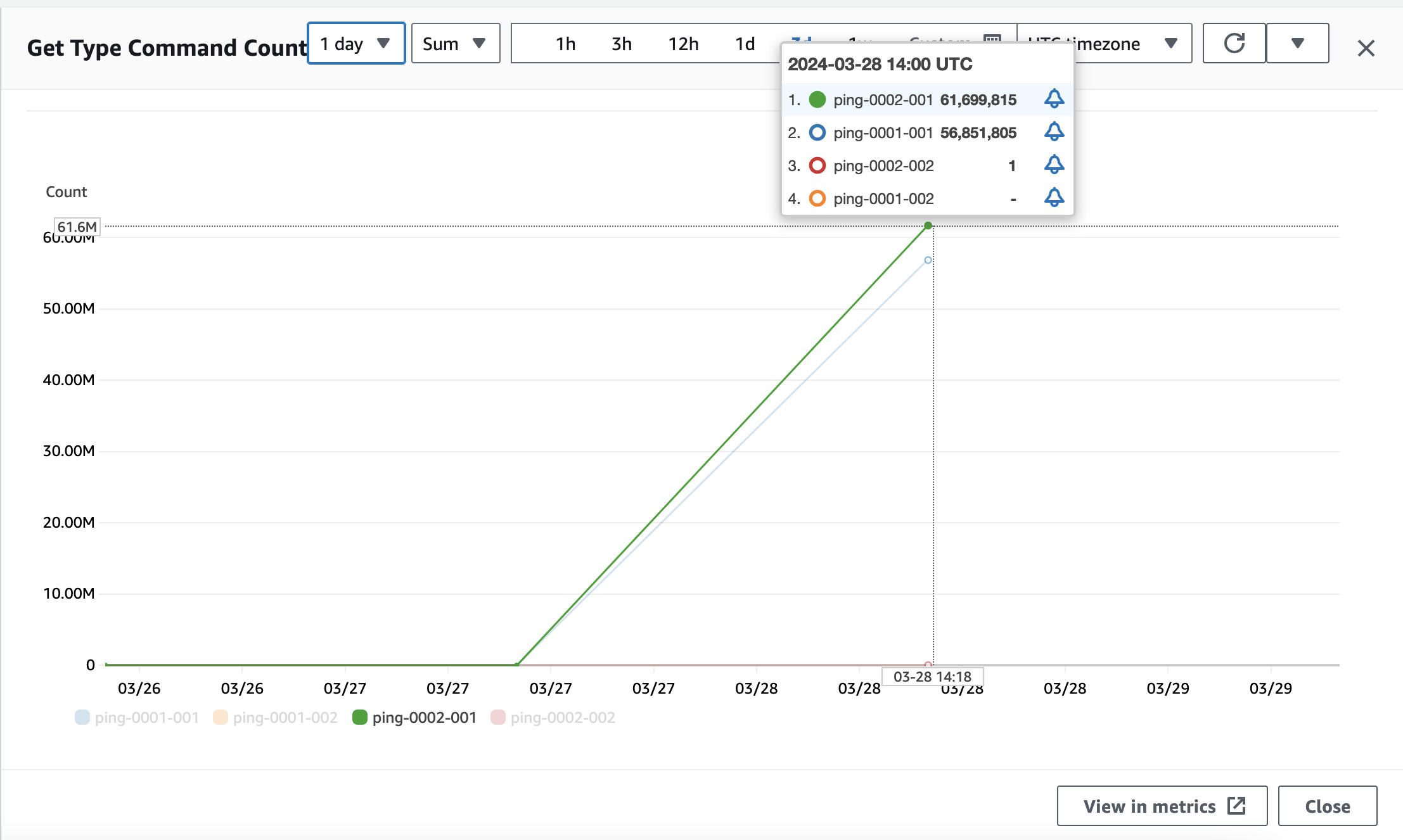
进一步分析计算 ECPU 成本。每个 Key/Value 大小都小于 1KB,计算 Serverless ECPU,需要获取请求数量指标,这里包括 Get Type Command Count 和 Set Type Command Count。指标时间范围扩大到 1 周,选择 Sum 总数,时间粒度选择 1 天,反映在指标图上,每天就是一个点,表示当天 Get 或者 Set 类型的总请求数,所有节点读写请求总量相加,就可以计算当天的 ECPU。
|
|
|
|
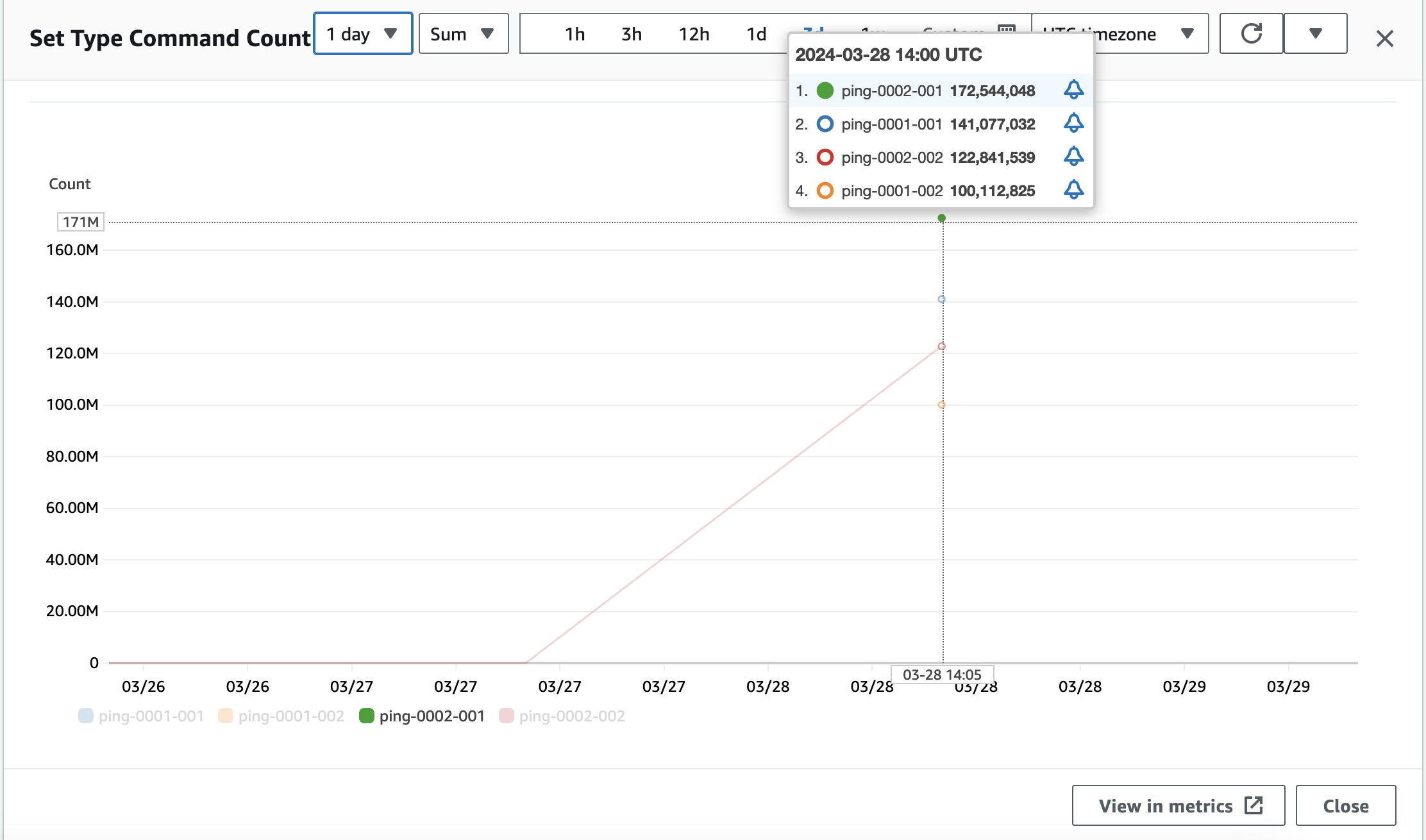
Get 类型请求数:118551620=118M
Set 类型请求数:536575444=537M
总请求数:118+537=655M
ECPU:USD 0.0034 / 百万 ECPU
假设每天都是如此请求量,每月 ECPU 费用:655*30*0.0034=67 USD
需要注意,本例子只包含了 Get/Set 类型请求。如果还有其他读写,比如 Lua 脚本操作,也要把相应的 Eval 指标计算入内。
接着计算存储量,查看 Bytes Used For Cache 指标,若每天变化量不大,按照每小时平均值,即可计算出存储费用。
|
|
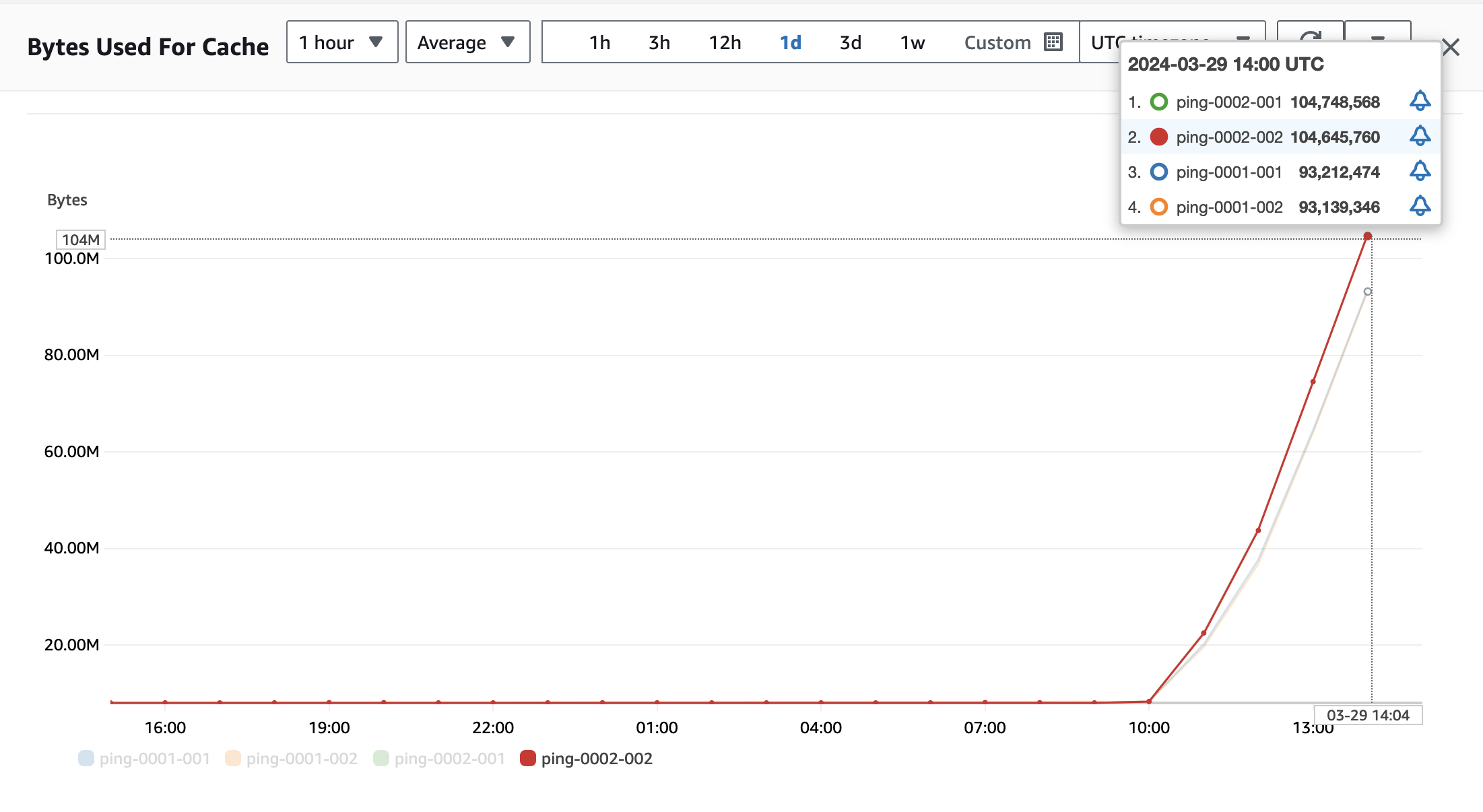
本示例中数据量太少,最高时也只有 100MB,按照最低 1GB 计算。客户可以根据实际使用量来计算真实存储成本。
存储数据:USD 0.125 / GB-小时
每月存储费用:0.125*1*24*30=90 USD
Elasticache Serverless 每月总费用:67+90=157 USD
假设现有 Amazon Elasticache 实例使用集群模式,生产环境最低配置cache.m6g.large(2 vCPU, 6.38GB 内存),2 个分片,每个分片 2 个节点高可用,总共 4 个节点。预留实例包年,折合每月 USD 74.46。
Elasticache 实例集群模式,4 个预留实例每月总费用:74.46*4=298 USD
以此价格对比,Serverless(157)比实例模式(298)成本节省接近一半。
此示例只是估算,实际成本还需要结合已有的配置和监控指标进行评估。
六. 迁移到 ElastiCache Serverless
根据您的诉求不同,可以采用两种不同的方式迁移到- ElastiCache Serverless。
- 如果您接受一定的停机时间,可以采用全量迁移的方式,将自建 Redis 或者 ElastiCache 非集群/集群导出到 rdb 格式,再通过 rdb 导入的方式建立 ElastiCache Serverless 集群。
- 如果您希望尽可能减少对业务的影响,可以利用第三方工具进行在线 CDC 的迁移,比如 RIOT-Redis 和 RedisShake 等。
七. 总结
- Elasticache Serverless 可以根据流量变化,迅速而平滑扩展,读写延迟保持相对稳定。
- 对于应用程序,提供统一访问端口,无需容量管理、故障切换或者小版本升级等运维工作。
- Elasticache Serverless 适合业务波峰低谷变化明显的场景,业务高峰期持续时间不长,低谷流量落差很大时,Serverless 更有成本和扩展优势。
- 可根据现有 Elasticache Redis 实例监控指标,读写请求数,结合数据大小,计算出 ECPU。结合已经使用内存指标,计算存储容量。两者相加即可得出 Elasticache Serverless 费用,与现有 Elasticache 实例作对比成本。
更多相关内容欢迎访问我的网站:国外VPS网站 - 国外VPS测评,云服务器,香港VPS,主机推荐
这篇关于ElastiCache Serverless for Redis应用场景和性能成本分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




