本文主要是介绍mr on yarn架构设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
架构图
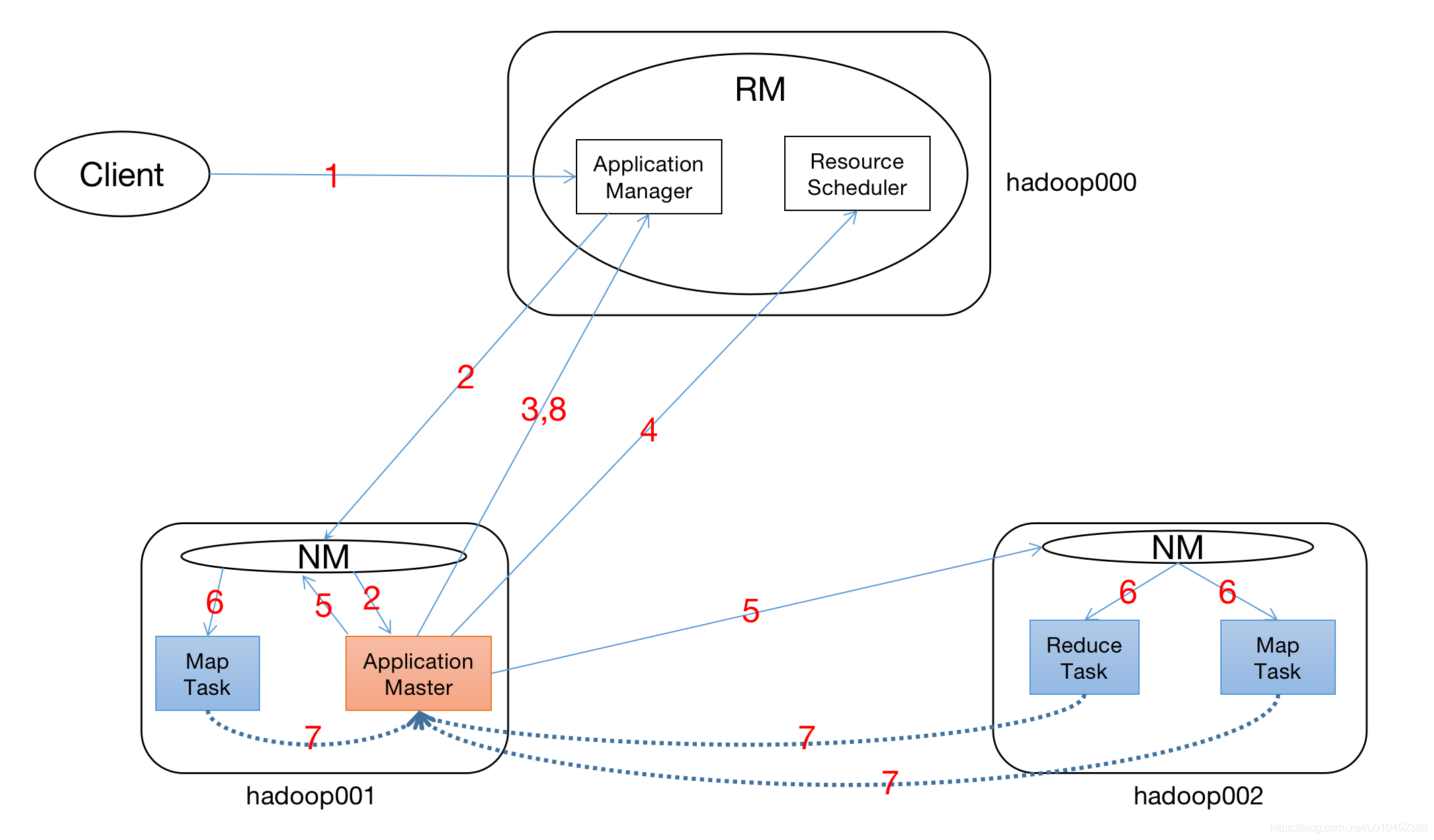
RM: ResourceManager
NM: NodeManager
1.用户向yarn提交job,其中包含Application master程序,以及启动Application master的脚本等
2.RM为该job分配第一个Container,与对应的NM通信,要求他在这个Container启动作业的Application master
3.Application master向Application manager注册信息,这样用户就可以通过RM的web界面查看job的状态
4.application master 采用轮询的机制通过【RPC】协议向Resource Scheduler申请和认领资源
5.一旦申请到资源,与对应的NM通信,请求启动task
6.NM设置好运行环境之后,将任务的启动脚本写到一个脚本中,并通过该脚本启动任务,开始运行任务
7.每个task通过【RPC】协议向application Master回报自己的状态和进度,以让application master掌握各个任务的状态,从而在任务失败的时候,重新启动
8.job运行完成后,application master向application manager注销并关闭自己
这篇关于mr on yarn架构设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![[Linux Kernel Block Layer第一篇] block layer架构设计](https://i-blog.csdnimg.cn/direct/6f402f42143b4aac927657769404055e.png)






