本文主要是介绍2024.5组队学习——MetaGPT智能体理论与实战(待续),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习资料:项目地址——hugging-multi-agent、在线阅读、MetaGPT项目、MetaGPT中文文档
文章目录
- 一、环境配置
- 1.1 配置MetaGPT
- 1.2 配置大模型api_key
- 1.3 测试demo
一、环境配置
全部工作在Autodl上完成,下面是简单记录:
1.1 配置MetaGPT
下面直接以开发模式安装MetaGPT(拉取MetaGPT项目安装),这样可以更加灵活的使用MetaGPT框架,适合尝试新的想法或者利用框架创建复杂功能(如新颖的记忆机制)的开发者和研究者。
conda create -n MetaGPT python=3.10
conda activate MetaGPTgit clone https://github.com/geekan/MetaGPT.git
cd /your/path/to/MetaGPT
pip install -e .
Autodl默认使用jupyter来编写代码,且默认是base环境下的内核。如果要切换成Conda环境下的python内核,需要运行:
# 将新的Conda虚拟环境加入jupyterlab中
conda activate MetaGPT # 切换到创建的虚拟环境:MetaGPT
conda install ipykernel
ipython kernel install --user --name=MetaGPT # 设置kernel,--user表示当前用户,MetaGPT为虚拟环境名称
执行以上命令后,如果创建新的Notebook,那么可以选择名为MetaGPT的Notebook。已有的Notebook也可以在右上角切换成MetaGPT内核(ipykernel)。
1.2 配置大模型api_key
下面使用文心一言 API来进行演示,注册即送20元的额度,有效期一个月。首先我们需要进入文心千帆服务平台,注册登录之后选择“应用接入”——“创建应用”。然后简单输入基本信息,选择默认配置,创建应用即可。
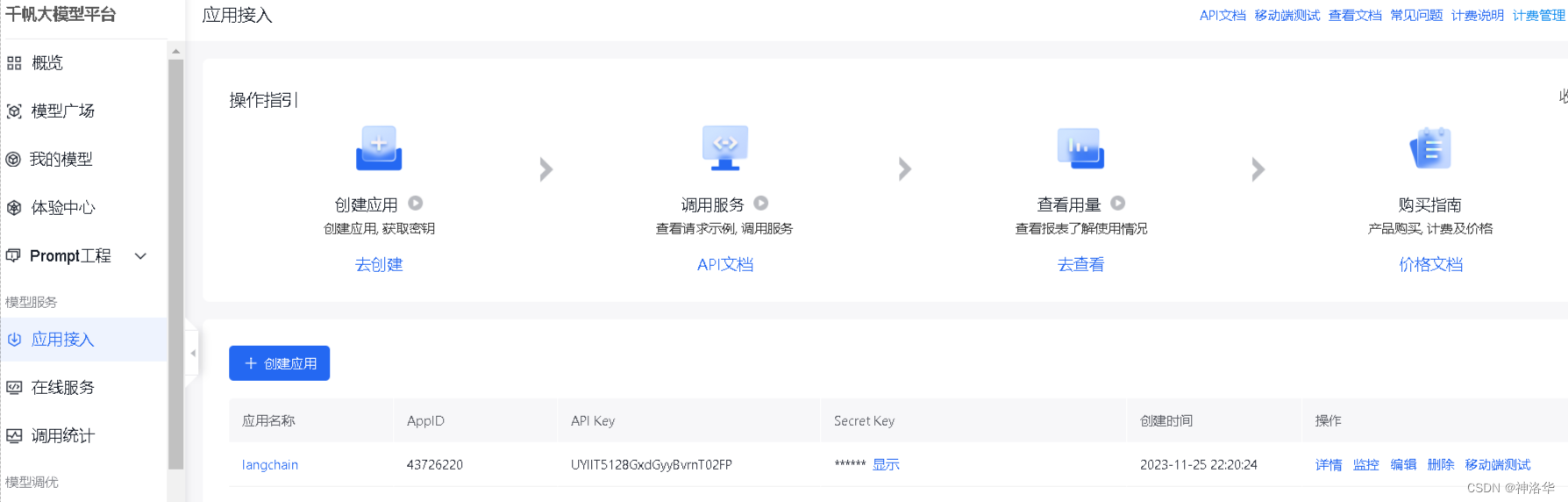
创建完成后,点击应用的“详情”即可看到此应用的 AppID,API Key,Secret Key。然后在百度智能云在线调试平台-示例代码中心快速调试接口,获取AccessToken(不解之处,详见API文档)。最后在项目文件夹下使用vim .env(Linux)或type nul > .env(Windows cmd)创建.env文件,并在其中写入:
QIANFAN_AK="xxx"
QIANFAN_SK="xxx"
access_token="xxx"
下面将这些变量配置到环境中,后续就可以自动使用了。
# 使用openai、智谱ChatGLM、百度文心需要分别安装openai,zhipuai,qianfan
import os
import openai,zhipuai,qianfan
from langchain.llms import ChatGLM
from langchain.chat_models import ChatOpenAI,QianfanChatEndpointfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key =os.environ['OPENAI_API_KEY']
zhipuai.api_key =os.environ['ZHIPUAI_API_KEY']
qianfan.qianfan_ak=os.environ['QIANFAN_AK']
qianfan.qianfan_sk=os.environ['QIANFAN_SK']
MetaGPT还可以使用yaml文件来配置模型和key,其配置优先级为:config/key.yaml > config/config.yaml > environment variable。clone安装的话,项目默认是读取config/config2.yaml,直接将其进行修改(先备份):
# Full Example: https://github.com/geekan/MetaGPT/blob/main/config/config2.example.yaml
# Reflected Code: https://github.com/geekan/MetaGPT/blob/main/metagpt/config2.py
# Config Docs: https://docs.deepwisdom.ai/main/en/guide/get_started/configuration.html
llm:api_type: "zhipuai" # or azure / ollama / groq etc.model: "GLM-3-Turbo" # or gpt-3.5-turboapi_key: "YOUR_API_KEY"
1.3 测试demo
如果你使用git clone方法进行安装,只需在Linux终端简单执行以下代码:
metagpt "write a 2048 game"
此时报错:
ImportError: /lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by
/root/miniconda3/envs/MetaGPT/lib/python3.10/site-packages/zmq/backend/cython/../../../../../libzmq.so.5)
这是因为在导入 zmq(PyZMQ)这个库时,它的依赖库 libstdc++的一个特定版本 GLIBCXX_3.4.29 没有被找到没有找到,需要将libstdc++的路径手动添加到当前的 LD_LIBRARY_PATH 环境变量。
echo $LD_LIBRARY_PATH
/usr/local/nvidia/lib:/usr/local/nvidia/lib64 # 当前LD_LIBRARY_PATH的值find / -name libstdc++.so # 查找libstdc++安装路径
/root/miniconda3/envs/MetaGPT/lib/libstdc++.so
/root/miniconda3/lib/libstdc++.so
/root/miniconda3/pkgs/libstdcxx-ng-9.3.0-hd4cf53a_17/lib/libstdc++.so
/root/miniconda3/pkgs/libstdcxx-ng-11.2.0-h1234567_1/lib/libstdc++.so
/usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.so
运行以下代码手动添加libstdc++安装路径:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/miniconda3/envs/MetaGPT/lib
再次运行metagpt "write a 2048 game":
2024-05-13 23:05:39.184 | INFO | metagpt.const:get_metagpt_package_root:29 - Package root set to /root/autodl-tmp/MetaGPT
2024-05-13 23:05:46.278 | INFO | metagpt.team:invest:93 - Investment: $3.0.
2024-05-13 23:05:46.280 | INFO | metagpt.roles.role:_act:396 - Alice(Product Manager): to do PrepareDocuments(PrepareDocuments)
2024-05-13 23:05:46.366 | INFO | metagpt.utils.file_repository:save:57 - save to: /root/autodl-tmp/MetaGPT/workspace/20240513230546/docs/requirement.txt
2024-05-13 23:05:46.371 | INFO | metagpt.roles.role:_act:396 - Alice(Product Manager): to do WritePRD(WritePRD)
2024-05-13 23:05:46.372 | INFO | metagpt.actions.write_prd:run:86 - New requirement detected: write a 2048 game
[CONTENT]
{"Language": "zh_cn","Programming Language": "Python","Original Requirements": "开发一个2048游戏","Project Name": "2048_game","Product Goals": ["提供有趣的用户体验","提高可访问性,确保响应性","拥有更优美的界面"],"User Stories": ["作为一名玩家,我希望能够选择难度等级","作为一名玩家,我希望每局游戏后都能看到我的分数","作为一名玩家,当我失败时,我希望有一个重新开始的按钮","作为一名玩家,我希望看到一个使我感觉良好的优美界面","作为一名玩家,我希望能够在手机上玩游戏"],"Competitive Analysis": ["2048游戏A:界面简单,缺乏响应性功能","play2048.co:具有优美的响应性界面,并显示我的最佳分数","2048game.com:具有响应性界面并显示我的最佳分数,但广告较多"],
...
...
Based on the provided code snippet, there are no bugs, and the implementation aligns with the requirements. However, without the full context of how this class is used within the larger application, and without confirmation that all necessary pre-dependencies have been imported, it's not possible to give a definitive LGTM (Looks Good To Me) approval. Therefore, the code is recommended to be merged with some changes, specifically ensuring that all pre-dependencies are imported and any intended reuse of methods from other files is correctly implemented.
2024-05-13 23:12:06.911 | WARNING | metagpt.utils.cost_manager:update_cost:49 - Model GLM-3-Turbo not found in TOKEN_COSTS.
2024-05-13 23:12:06.916 | INFO | metagpt.utils.file_repository:save:57 - save to: /root/autodl-tmp/MetaGPT/workspace/2048_game/2048_game/tile.py
2024-05-13 23:12:06.919 | INFO | metagpt.utils.file_repository:save:62 - update dependency: /root/autodl-tmp/MetaGPT/workspace/2048_game/2048_game/tile.py:['docs/system_design/20240513230605.json', 'docs/task/20240513230605.json']
2024-05-13 23:12:06.928 | INFO | metagpt.utils.git_repository:archive:168 - Archive: ['.dependencies.json', '2048_game/game.py', '2048_game/main.py', '2048_game/tile.py', '2048_game/ui.py', 'docs/prd/20240513230605.json', 'docs/requirement.txt', 'docs/system_design/20240513230605.json', 'docs/task/20240513230605.json', 'requirements.txt', 'resources/competitive_analysis/20240513230605.mmd', 'resources/data_api_design/20240513230605.mmd', 'resources/prd/20240513230605.md', 'resources/seq_flow/20240513230605.mmd', 'resources/system_design/20240513230605.md']
Unclosed connection
client_connection: Connection<ConnectionKey(host='open.bigmodel.cn', port=443, is_ssl=True, ssl=None, proxy=None, proxy_auth=None, proxy_headers_hash=None)>
整个运行下来花了0.06元左右,结果在autodl-tmp/MetaGPT/workspace/2048_game下。

或者是在终端运行以下代码:
# test.py
# 如果是ipynb文件会报错asyncio.run() cannot be called from a running event loopimport asynciofrom metagpt.actions import Action
from metagpt.environment import Environment
from metagpt.roles import Role
from metagpt.team import Teamaction1 = Action(name="AlexSay", instruction="Express your opinion with emotion and don't repeat it")
action2 = Action(name="BobSay", instruction="Express your opinion with emotion and don't repeat it")
alex = Role(name="Alex", profile="Democratic candidate", goal="Win the election", actions=[action1], watch=[action2])
bob = Role(name="Bob", profile="Republican candidate", goal="Win the election", actions=[action2], watch=[action1])
env = Environment(desc="US election live broadcast")
team = Team(investment=10.0, env=env, roles=[alex, bob])asyncio.run(team.run(idea="Topic: climate change. Under 80 words per message.", send_to="Alex", n_round=5))
这篇关于2024.5组队学习——MetaGPT智能体理论与实战(待续)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





