本文主要是介绍通过LinkedHashMap缓存图片并实现LRU策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近看了下通过LinkedHashMap来缓存图片并且实现LRU机制优化内存使用率的内容,所以做下总结!~~
在Android开发过程中,实现图片缓存是一个很重要的问题,如果处理不当很容易引起OOM等问题。很多图片加载框架中都会使用LRU机制来优化内存使用率。今天我们就看下通过LinkedHashMap如何实现LRU机制。
LRU(Least Recently Used)策略,即当内存使用不足时,把最近最少使用的数据从缓存中移除,保留使用最频繁的数据。
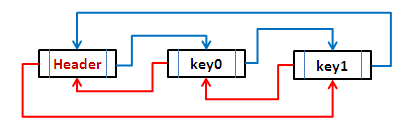
LinkedHashMap,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素,上图即为一个双向链表。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。在初始化一个LinkedHashMap时可以指定accessOrder值来指定链表的排序策略,当accessOrder为false的时候链表按插入顺序排序,默认为false,当为true的时候按访问顺序排序,什么是按访问顺序排序呢?
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {super(initialCapacity, loadFactor);init();this.accessOrder = accessOrder;
}
其实按访问顺序排序就是指在调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。这部分源码如下
public V get(Object key) {if (key == null) {HashMapEntry<K, V> e = entryForNullKey;if (e == null)return null;if (accessOrder)makeTail((LinkedEntry<K, V>) e);return e.value;}int hash = Collections.secondaryHash(key);HashMapEntry<K, V>[] tab = table;for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];e != null; e = e.next) {K eKey = e.key;if (eKey == key || (e.hash == hash && key.equals(eKey))) {if (accessOrder)makeTail((LinkedEntry<K, V>) e);return e.value;}}return null;}查看源码我们发现,不管keys是否为空,在accessOrder为true(即按访问顺序排序)后,会先执行makeTail方法,然后再返回元素的Value。我们继续跟到makeTail方法中。
private void makeTail(LinkedEntry<K, V> e) {// Unlink ee.prv.nxt = e.nxt;e.nxt.prv = e.prv;// Relink e as tailLinkedEntry<K, V> header = this.header;LinkedEntry<K, V> oldTail = header.prv;e.nxt = header;e.prv = oldTail;oldTail.nxt = header.prv = e;modCount++;}观察makeTail的函数体,我们很容易发现这是一个对双向链表中一个元素解绑后与header关联的代码,经过操作后,当前元素会被插入到链表尾部。看到这里,我想大家就明白了为什么通过get方法会使链表按照按访问顺序排序。那当我们put数据的时候又会发生什么呢?通过源码我们发现,当我们put数据的时候,会先跳hashmap的put方法中,这是因为LinkedHashMap并没用重写这个方法而是重写了put方法中所调用的addNewEntry或addNewEntryForNullKey等方法。我们主要看下addNewEntry的函数体。
@Override void addNewEntry(K key, V value, int hash, int index) {LinkedEntry<K, V> header = this.header;LinkedEntry<K, V> eldest = header.nxt;if (eldest != header && removeEldestEntry(eldest)) {remove(eldest.key);}LinkedEntry<K, V> oldTail = header.prv;LinkedEntry<K, V> newTail = new LinkedEntry<K,V>(key, value, hash, table[index], header, oldTail);table[index] = oldTail.nxt = header.prv = newTail;}addNewEntry方法中首先会获取头指针的下一个元素,并定义为eldest,从字面上理解应该是最老的元素,结合前面get方法的介绍也比较好理解为什么头指针下一个元素会是”最老的“。if中的第一个链表非空的判断比较好理解,然后我们看下removeEldestEntry这个方法
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return false;}默认倩况下返回false的,那什么时候返回true,只有在removeEldestEntry也返回true的时候才会去执行删除“最老”的元素的操作,这样才比较符合我们的逻辑。。。其实目前LRU策略少一个判断,就是什么时候去执行删除最近最少操作的数据,重新看下LRU的概念,当内存不足时进行删除,而这个内存对LinkedHashMap来说其实就是大小,所以我们只需要在初始化LinkedHashMap的时候重写这个方法并且做一个判断,如果当前大小已经大于LinkedHashMap的容量就返回true,从而就会删除最近最少的数据,码如下。
HashMap<String, Bitmap> hardCache = new LinkedHashMap<String, Bitmap>(10, 0.75f, true) {@Overrideprotected boolean removeEldestEntry(Entry<String, Bitmap> entry) {if (this.size() > CAPACITY) {return true;} else {return false;}}
};到这里LinkedHashMap的LRU策略就实现了。下面我们验证下前面所说的。
HashMap<String, String> map=new LinkedHashMap<String,String>(5, 0.75f, true){protected boolean removeEldestEntry(java.util.Map.Entry<String,String> eldest) {if(this.size()>5){return true;}else{return false;}}};for(int i=0;i<5;i++){map.put("key"+i,"value"+i);}for(String value:map.values()){System.out.println(value);}输出输出结果为:
value0
value1
value2
value3
value4下面我们get下map中的数据
for(int i=0;i<5;i++){map.put("key"+i,"value"+i);}map.get("key"+3);for(String value:map.values()){System.out.println(value);}输出结果为:
value0
value1
value2
value4
value3结果和我们上面讲的是一致的。
接下来改下代码再测试下
for(int i=0;i<5;i++){map.put("key"+i,"value"+i);}map.get("key"+3);map.put("key5","value new add");for(String value:map.values()){System.out.println(value);}这段代码是向已经满了的LinkedHashMap中继续添加一个元素,根据前所讲,应该会删除第一个元素,即为key0元素被删除,下面看下结果:
value1
value2
value4
value3
value new add结果与我们前面所讲的一致。
写到这里大家应该对linkedhashmap实现LRU有了一个全面的了解。利用这个机制在缓存图片的时候大大的优化内存使用率,使内存中保留的数据是经常使用的图片。
好了!就写到这里了,欢迎大家留言一起讨论!这是我第一篇博客,以后还是继续努力!~~~~
这篇关于通过LinkedHashMap缓存图片并实现LRU策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


