本文主要是介绍微软如何打造数字零售力航母系列科普10 - 什么是Azure Databricks?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是Azure Databricks?

目录
一、数据智能平台是如何工作的?
二、Azure Databricks的用途是什么?
三、与开源的托管集成
四、工具和程序访问
五、Azure Databricks如何与Azure协同工作?
六、Azure Databricks的常见用例是什么?
七、构建企业数据湖
八、ETL和数据工程
九、机器学习、人工智能和数据科学
十、数据仓库、分析和BI
十一、数据治理和安全的数据共享
十二、DevOps、CI/CD和任务编排
十三、实时和流媒体分析
Azure Databricks是一个统一、开放的分析平台,用于大规模构建、部署、共享和维护企业级数据、分析和人工智能解决方案。Databricks数据智能平台与您的云帐户中的云存储和安全集成,并代表您管理和部署云基础设施。
一、数据智能平台是如何工作的?
Azure Databricks使用生成人工智能和数据仓库(data lakehouse)来理解数据的独特语义。然后,它会自动优化性能并管理基础架构,以满足您的业务需求。
自然语言处理学习企业的语言,因此您可以通过用自己的话提问来搜索和发现数据。自然语言帮助可以帮助您编写代码、排除错误并在文档中找到答案。
最后,您的数据和人工智能应用程序可以依靠强大的治理和安全性。您可以在不损害数据隐私和IP控制的情况下集成OpenAI等API。
二、Azure Databricks的用途是什么?
Azure Databricks提供了一些工具,可以帮助您将数据源连接到一个平台,通过从BI到生成人工智能的解决方案来处理、存储、共享、分析、建模和货币化数据集。
Azure Databricks工作区为大多数数据任务提供了统一的界面和工具,包括:
1. 数据处理调度和管理,特别是ETL
2. 生成仪表板和可视化
3. 管理安全性、治理、高可用性和灾难恢复
4. 数据发现、注释和探索
5. 机器学习(ML)建模、跟踪和模型服务
6. 生成型人工智能解决方案
三、与开放资源一起托管集成
Databricks对开源社区有着坚定的承诺。Databricks在Databricks Runtime版本中管理开源集成的更新。以下技术是Databricks员工最初创建的开源项目:
1. 三角洲湖(Delt Lake)与三角洲共享(Delta Sharing)
2. MLflow
3. Apache Spark和结构化流媒体(structure streaming)
4. Redash
四、工具和程序访问
Azure Databricks维护了许多专有工具,这些工具集成并扩展了这些技术,以增加优化的性能和易用性,例如:
1. 工作流 (workflows)
2. Unity Catalog
3. Delta Live Tables
4. Databricks SQL
5. 光子计算簇(Photo compute clusters)
除了工作区UI,您还可以使用以下工具以编程方式与Azure Databricks交互:
1. REST API
2. CLI
3. Terraform
五、Azure Databricks如何与Azure协同工作?
Azure Databricks平台架构包括两个主要部分:
1. Azure Databricks用于部署、配置和管理平台和服务的基础设施。
2. 由Azure Databricks和您的公司协同管理的客户拥有的基础设施。
与许多企业数据公司不同,Azure Databricks不会强制您将数据迁移到专有存储系统中以使用该平台。相反,您可以通过配置Azure Databricks平台和您的云帐户之间的安全集成来配置Azure Databricks工作区,然后Azure Databrick使用您的帐户中的云资源部署计算集群,以在对象存储和您控制的其他集成服务中处理和存储数据。
Unity Catalog进一步扩展了这种关系,允许您使用Azure Databricks中熟悉的SQL语法管理访问数据的权限。
Azure Databricks工作区满足世界上一些最大、最具安全意识的公司的安全和网络要求(推荐阅读1)。Databricks Customer Stories | DatabricksDiscover how companies across every industry are leveraging the effectiveness of the Databricks Lakehouse Platform.![]() https://www.databricks.com/customers
https://www.databricks.com/customers
Azure Databricks让新用户可以轻松开始使用该平台。它消除了使用云基础设施的许多负担和担忧,而不限制定制和控制经验丰富的数据、操作和安全团队所需的内容。
六、Azure Databricks的常见用例是什么?
Azure Databricks上的用例因平台上处理的数据以及将数据作为工作核心部分的员工的许多角色而异。以下用例强调了整个组织的用户如何利用Azure Databricks来完成处理、存储和分析驱动关键业务功能和决策的数据所必需的任务。
七、构建企业数据湖

数据湖之家结合了企业数据仓库和数据湖的优势,以加速、简化和统一企业数据解决方案。数据工程师、数据科学家、分析师和生产系统都可以将数据湖屋作为其唯一的真相来源,允许及时访问一致的数据,并降低构建、维护和同步许多分布式数据系统的复杂性。看什么是数据小屋?。
八、ETL(Extraction\Transform\Loading)和数据工程
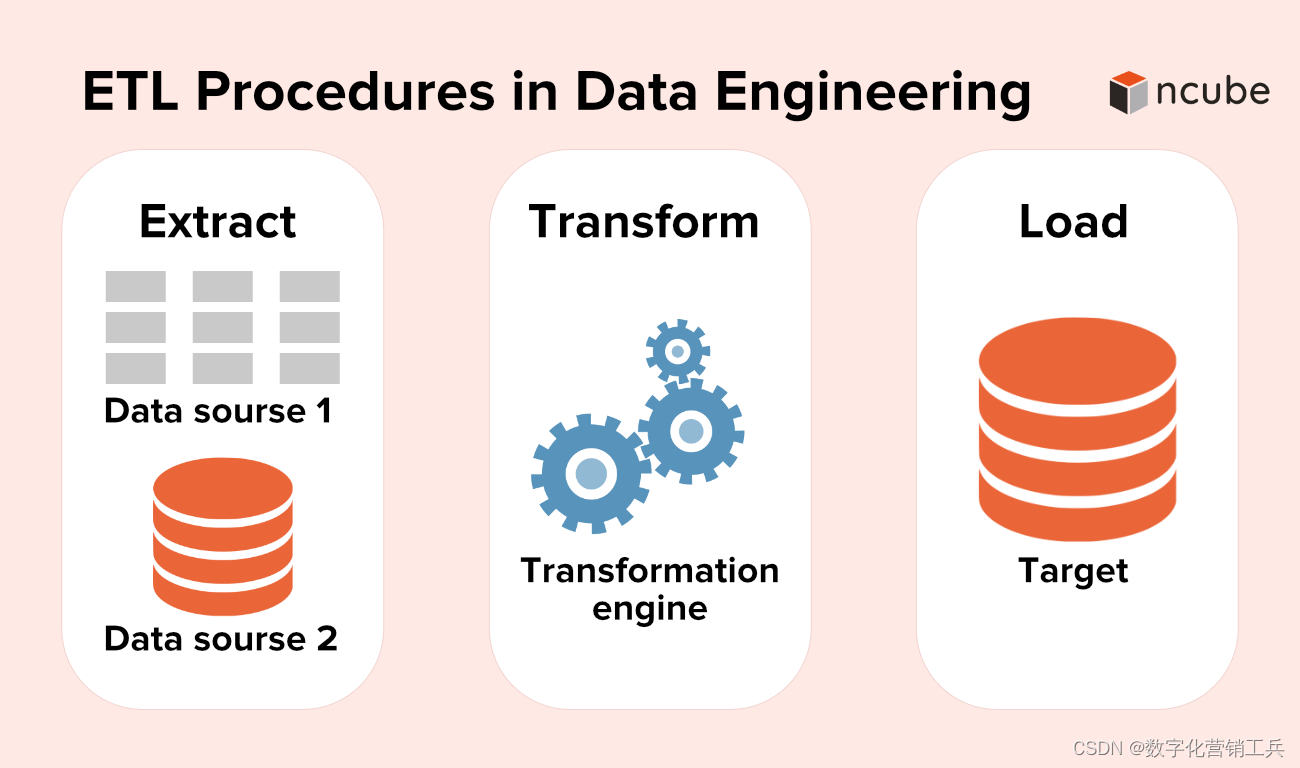
无论您是在生成仪表板还是为人工智能应用程序提供动力,数据工程都能确保数据可用、干净并存储在数据模型中,从而实现高效的发现和使用,从而为以数据为中心的公司提供骨干。Azure Databricks将Apache Spark的强大功能与Delta Lake和自定义工具相结合,提供无与伦比的ETL(提取、转换、加载)体验。您可以使用SQL、Python和Scala来编写ETL逻辑,然后只需点击几下即可编排计划的作业部署。
Delta Live Tables通过智能管理数据集之间的依赖关系,并自动部署和扩展生产基础架构,确保根据您的规范及时准确地交付数据,从而进一步简化了ETL。(推荐阅读5 - ETL与企业数据工程)ETL Developer Role Explained: Responsibilities, Skills, and When to Hire One? - nCube![]() https://ncube.com/etl-developer-role-explained-responsibilities-skills-and-when-hire-one/
https://ncube.com/etl-developer-role-explained-responsibilities-skills-and-when-hire-one/
Azure Databricks提供了许多用于数据摄取的自定义工具,包括Auto Loader,这是一种高效且可扩展的工具,用于将数据从云对象存储和数据湖增量和幂等地加载到数据湖库中。(推荐阅读6 - ETL on Azure Databricks) Databricks文档04----使用 Azure Databricks 提取、转换和加载数据_azure添加key vault后在databricks上使用-CSDN博客文章浏览阅读4.9k次,点赞4次,收藏19次。使用 Azure Databricks 执行 ETL(提取、转换和加载数据)操作。 将数据从 Azure Data Lake Storage Gen2 提取到 Azure Databricks 中,在 Azure Databricks 中对数据运行转换操作,然后将转换的数据加载到 Azure Synapse Analytics 中。本教程中的步骤使用 Azure Databricks 的 Azure Synapse 连接器将数据传输到 Azure Databricks。 _azure添加key vault后在databricks上使用https://blog.csdn.net/capsicum29/article/details/123614322?spm=1001.2101.3001.6650.6&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogOpenSearchComplete~Rate-6-123614322-blog-138834281.235%5Ev43%5Epc_blog_bottom_relevance_base3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogOpenSearchComplete~Rate-6-123614322-blog-138834281.235%5Ev43%5Epc_blog_bottom_relevance_base3&utm_relevant_index=5
九、机器学习、人工智能和数据科学
Azure Databricks机器学习通过一套根据数据科学家和ML工程师的需求量身定制的工具扩展了平台的核心功能,包括MLflow和用于机器学习的Databricks Runtime(推荐阅读2)。
AI and Machine Learning on Databricks - Azure Databricks | Microsoft LearnAI and Machine Learning on Databricks, an integrated environment to simplify and standardize ML, DL, LLM, and AI development. Tutorials and user guides for common tasks and scenarios.![]() https://learn.microsoft.com/en-us/azure/databricks/machine-learning/
https://learn.microsoft.com/en-us/azure/databricks/machine-learning/
大型语言模型和生成人工智能
Databricks Runtime for Machine Learning包括Hugging Face Transformers等库,允许您将现有的预训练模型或其他开源库集成到工作流程中。Databricks MLflow集成使MLflow跟踪服务易于与变压器管道、模型和处理组件一起使用。此外,您可以在Databricks工作流中集成来自John Snow Labs等合作伙伴的OpenAI模型或解决方案。
使用Azure Databricks,您可以为特定任务自定义数据LLM。在开源工具(如Hugging Face和DeepSpeed)的支持下,您可以高效地进行基础LLM,并开始使用自己的数据进行训练,以提高您的领域和工作负载的准确性。
此外,Azure Databricks提供了人工智能功能,SQL数据分析师可以使用这些功能直接在其数据管道和工作流程中访问LLM模型,包括从OpenAI访问。请参阅Azure Databricks上的AI功能。
十、数据仓库、分析和BI
Azure Databricks将用户友好的UI与经济高效的计算资源和可无限扩展、价格合理的存储相结合,为运行分析查询提供了一个强大的平台。管理员将可扩展计算集群配置为SQL仓库,允许最终用户执行查询,而无需担心在云中工作的任何复杂性。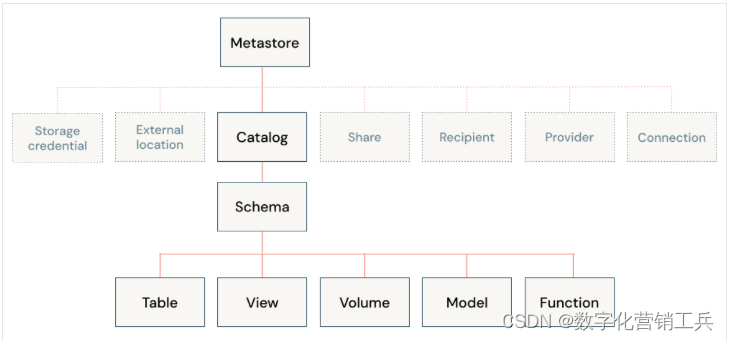
SQL用户可以使用SQL查询编辑器或笔记本电脑对lakehouse中的数据进行查询。除了SQL之外,笔记本还支持Python、R和Scala,并允许用户在传统的面板中嵌入相同的可视化效果,以及用markdown(推荐阅读3 什么是Markdown?) 编写的链接、图像和评论。Markdown reference for Microsoft Learn - Contributor guide | Microsoft LearnLearn the Markdown features and syntax used in Microsoft Learn content.![]() https://learn.microsoft.com/en-us/contribute/content/markdown-reference
https://learn.microsoft.com/en-us/contribute/content/markdown-reference
十一、数据治理和安全的数据共享
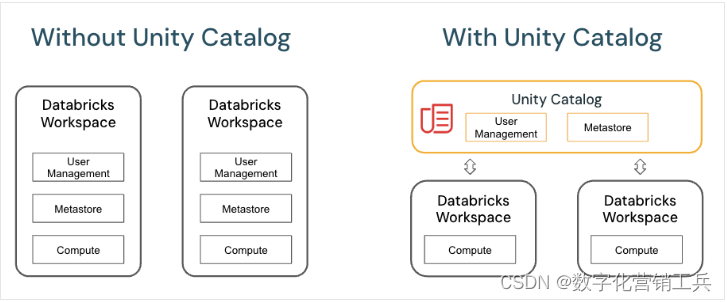
Unity Catalog为数据小屋提供了一个统一的数据治理模型。云管理员为Unity Catalog配置和集成粗略访问控制权限,然后Azure Databricks管理员可以管理团队和个人的权限。权限通过用户友好的UI或SQL语法通过访问控制列表(ACL)进行管理,使数据库管理员更容易安全地访问数据,而无需扩展云原生身份访问管理(IAM)和网络。
Unity Catalog使在云中运行安全分析变得简单,并提供了责任分工,有助于限制平台管理员和最终用户所需的再技能或技能提升。请参阅什么是Unity Catalog (推荐阅读4 – 什么是Unity Catalog ?)What is Unity Catalog? - Azure Databricks | Microsoft LearnLearn how to perform data governance in Azure Databricks using Unity Catalog.![]() https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-cataloglakehouse使组织内的数据共享变得简单,只需授予对表或视图的查询访问权限。对于在安全环境之外的共享,Unity Catalog提供了管理版本的Delta sharing。
https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-cataloglakehouse使组织内的数据共享变得简单,只需授予对表或视图的查询访问权限。对于在安全环境之外的共享,Unity Catalog提供了管理版本的Delta sharing。
十二、DevOps、CI/CD和任务编排
ETL管道、ML模型和分析仪表板的开发生命周期各有其独特的挑战。Azure Databricks允许您的所有用户利用单个数据源,从而减少重复工作和不同步报告。通过额外提供一套用于版本控制、自动化、调度、部署代码和生产资源的通用工具,您可以简化监控、编排和操作的开销。工作流安排Azure Databricks笔记本、SQL查询和其他任意代码。Git文件夹允许您将Azure Databricks项目与许多流行的Git提供程序同步。有关工具的完整概述,请参阅开发人员工具和指南。
十三、实时和流媒体分析
Azure Databricks利用Apache Spark结构化流处理流数据和增量数据更改。结构化流与DeltaLake紧密集成,这些技术为DeltaLiveTables和AutoLoader提供了基础。请参阅Azure Databricks上的流式处理。
推荐阅读7 - 数字零售力航母 - 看微软如何重塑媒体
数字零售力航母-看微软如何重塑媒体-CSDN博客文章浏览阅读1k次,点赞29次,收藏25次。数字零售力航母-看微软如何重塑媒体?从2024全美广播协会展会看微软如何整合营销媒体AI技术和AI平台公司。 微软打造的“数据+技术+云”平台将为各个参与者(stakeholder)提供各种合作的机会和可能,互联网会产生更多的合作模式和技术组合。再次巩固数字化营销工兵的认知–任何一个人,一个组织,必须成为某个细分领域的专家,就像数据的颗粒度那样,越细,越能反映事物的独一特征(unique feature)https://blog.csdn.net/weixin_45278215/article/details/137907809?spm=1001.2014.3001.5502
这篇关于微软如何打造数字零售力航母系列科普10 - 什么是Azure Databricks?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







