本文主要是介绍目标检测(2)-RCNN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址:https://zhuanlan.zhihu.com/p/27473413
RCNN注意事项:https://blog.csdn.net/u010417185/article/details/79723974
RCNN作为第一篇目标检测领域的深度学习文章,大幅提升了目标检测的识别精度,在PASCAL VOC2012数据集上将MAP从35.1%提升至53.7%。使得CNN在目标检测领域成为常态,也使得大家开始探索CNN在其他计算机视觉领域的巨大潜力。这篇文章的创新点有以下几点:将CNN用作目标检测的特征提取器、有监督预训练的方式初始化CNN、在CNN特征上做BoundingBox 回归。
摘要
从ILSVRC 2012、2013表现结果来看,CNN在计算机视觉的特征表示能力要远高于传统的HOG、SIFT特征等,而且这种层次的、多阶段、逐步细化的特征计算方式也更加符合人类的认知习惯。但是,如何将在目标检测领域重现这种奇迹呢?目标检测区别于目标识别很重要的一点是其需要目标的具体位置,也就是BoundingBox。而产生BoundingBox最简单的方法就是滑窗,可以在卷积特征上滑窗。但是我们知道CNN是一个层次的结构,随着网络层数的加深,卷积特征的步伐及感受野也越来越大。例如AlexNet的Pool5层感受野为195*195,步伐为32*32,显然这种感受野是不足以进行目标定位的。使用浅层的神经网络能够保留这种空间结构,但是特征提取的性能就会大打折扣。RCNN另辟蹊径,既然我们无法使用卷积特征滑窗,那我们通过区域建议方法产生一系列的区域,然后直接使用CNN去分类这些区域是目标还是背景不就可以吗?当然这样做也会面临很多的问题,不过这个思路正是RCNN的核心。因此RCNN全称为Regions with CNN features。
整体结构
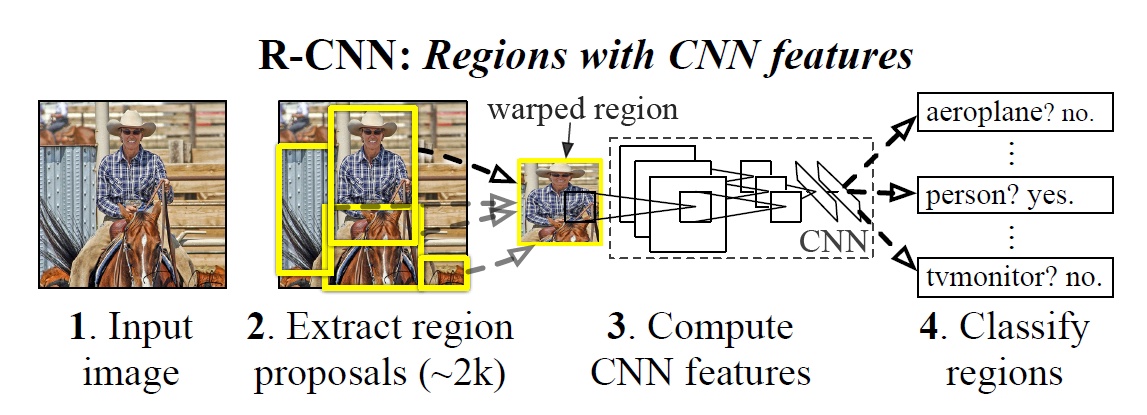
RCNN的输入为完整图片,首先通过区域建议算法产生一系列的候选目标区域,其中使用的区域建议算法为Selective Search,具体可以参照:目标检测(1)-Selective Search - 知乎专栏。然后对于这些目标区域候选提取其CNN特征,并训练SVM分类这些特征。最后为了提高定位的准确性在SVM分类后区域基础上进行BoundingBox回归。
- 产生目标区域候选
这部分其实就是直接使用Selective Search,选择2K个置信度最高的区域候选,关于筛选的细节以及排序规则可以参照本专栏上一篇文章。
- CNN目标特征提取
RCNN使用的是AlexNet,可以参见我们的相关文章:卷积神经网络模型(2)-AlexNet解读 - 知乎专栏由于CNN的参数量巨大,训练CNN需要大量的样本,此前的方法是大家先用无监督的预训练初始化CNN的参数,然后再在样本集上使用监督的训练方法。不同于这些方法,RCNN使用ImageNet的有标签数据进行有监督的预训练,然后再在本数据集上微调最后一层全连接层。直到现在,这种方法已经成为CNN初始化的标准化方法。但是训练CNN的样本量还是不能少的,因此RCNN将正样本定义的很宽松,为了尽可能获取最多的正样本,RCNN将IOU>0.5(IoU 指重叠程度,计算公式为:A∩B/A∪B)的样本都称为正样本。每次迭代批大小为128,其中正样本个数为32,负样本为96.其实这种设置是偏向于正样本的,因为正样本的数量实在是太少了。由于CNN需要固定大小的输入,因此对于每一个区域候选,首先将其放缩至227*227,然后通过CNN提取特征。
对IOU的进一步理解或再详细了解RCNN可参照博文 https://blog.csdn.net/u010417185/article/details/79723463
现在CNN已经能够提取到目标的特征了,但是CNN的层数很多,选择哪一层作为特征提取层呢?RCNN进行了宽泛的实验,最终选择的fc层。
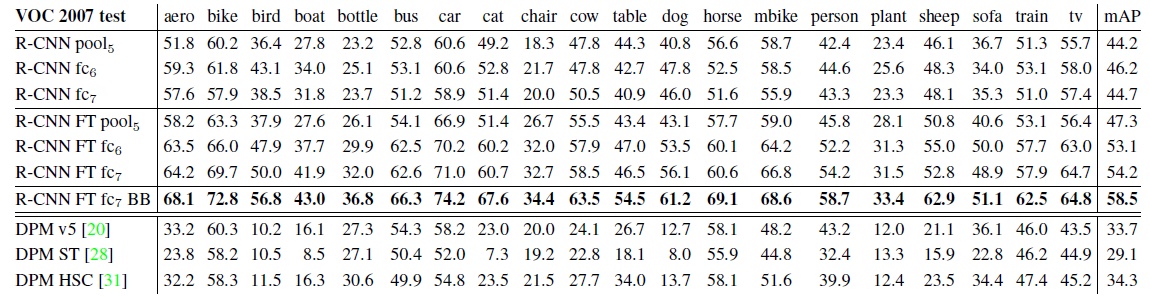
- 目标种类分类器
在通过CNN提取区域候选的特征后,RCNN对于每个种类训练SVM用以分类这些特征具体属于哪个种类。但是这里面的样本确定和CNN中的样本也是不一样的啦,因为CNN需要大量的样本去驱动特征提取,因此正样本的阈值比较低。而SVM适合小样本的分类,通过反复的实验,RCNN的SVM训练将ground truth样本作为正样本,而IOU>0.3的样本作为负样本,这样也是SVM困难样本挖掘的方法。
- 贪婪非极大值抑制
由于有多达2K个区域候选,我们如何筛选得到最后的区域呢?RCNN使用贪婪非极大值抑制的方法,假设ABCDEF五个区域候选,首先根据概率从大到小排列。假设为FABCDE。然后从最大的F开始,计算F与ABCDE是否IoU是否超过某个阈值,如果超过则将ABC舍弃。然后再从D开始,直到集合为空。而这个阈值是筛选得到的,通过这种处理之后一般只会剩下几个区域候选了。
- BoundingBox回归
为了进一步提高定位的准确率,RCNN在贪婪非极大值抑制后进行BoundingBox回归,进一步微调BoundingBox的位置。不同于DPM的BoundingBox回归,RCNN是在Pool5层进行的回归。而BoundingBox是类别相关的,也就是不同类的BoundingBox回归的参数是不同的。例如我们的区域候选给出的区域位置为:也就是区域的中心点坐标以及宽度和高度
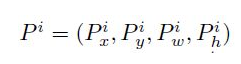
我们要做的就是找到一个映射把他转换到真实的位置:
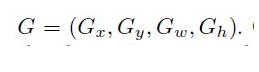
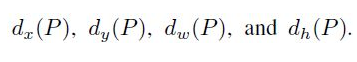
这些就是我们需要的参数,我们想得到关于尺寸无关的X,Y偏移量,以及尺度变化信息。如果求解到了这四个参数,我们就能成功的映射到真是目标位置了。
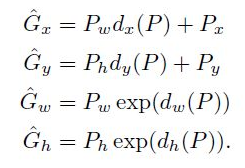
RCNN选用的特征是Pool5层特征,然后假设每个偏移量是Pool5特征的一个线性映射,也就是:
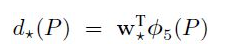
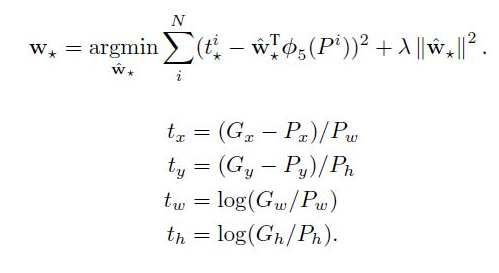
- 为什么不直接使用Fc8的结果作为贪婪极大值抑制的输入而是重新训练很多的SVM呢?
作者有去尝试使用Fc8结果作为输入,但是发现精度大约下降了4%,产生这种情况的原因是我们CNN的图片正样本定义为IOU>0.5,这是个很宽松的条件,导致CNN并不能定位到很精确的位置。那能不能将IOU设置的高一点呢?答案是否定的,因为CNN需要大量的样本,当正样本设置为真是BoundingBox时效果很差,而IOU>0.5相当于30倍的扩充了样本数量。而我们近将CNN结果作为一个初选,然后用困难负样本挖掘的SVM作为第二次筛选就好多了。
- 存在的问题
RCNN虽然效果很好,但是存在一些问题,比如时间代价太高了,网络训练是分阶段的,太麻烦了等。而这些问题将在我们后面的文章一一解决。直到最终版本Faster RCNN可以说是近乎完美的目标检测模型了,网络优美,速度快。
这篇关于目标检测(2)-RCNN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









