本文主要是介绍科赛网 魔镜杯“风控算法比赛”赛后总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.问题描述
从平均400个数据维度来评估当前用户的信用状态,给每个借款人打出当前状态的信用分。在此基础上,再结合新发标的信息,打出对于每个标的6个月内逾期率的预测,为投资人提供了关键的决策依据,促进健康高效的互联网金融。
2.数据集
数据是国内网络借贷行业的贷款风险数据,包括信用违约标签(因变量)、建模所需的基础与加工字段(自变量)、相关用户的网络行为原始数据。数据下载地址:
Master 每一行代表一个样本(一笔成功成交借款),每个样本包含200多个各类字段。
idx:每一笔贷款的unique key,可以与另外2个文件里的idx相匹配。
UserInfo_*:借款人特征字段
WeblogInfo_*:Info网络行为字段
Education_Info*:学历学籍字段
ThirdParty_Info_PeriodN_*:第三方数据时间段N字段
SocialNetwork_*:社交网络字段
LinstingInfo:借款成交时间
Target:违约标签(1 = 贷款违约,0 = 正常还款)。测试集里不包含target字段。Log_Info 借款人的登陆信息。
ListingInfo:借款成交时间
LogInfo1:操作代码
LogInfo2:操作类别
LogInfo3:登陆时间
idx:每一笔贷款的unique keyUserupdate_Info 借款人修改信息
ListingInfo1:借款成交时间
UserupdateInfo1:修改内容
UserupdateInfo2:修改时间
idx:每一笔贷款的unique key
3 特征工程和特征选择
思路如下:
- 第1步 对含有‘文字’和‘字母’的特征进行处理,处理之后整个数据集转换为数值型,便于下一步处理。
- 第2步 根据特征类型,可以把特征分为数值型特征和类别型特征;其中,类别型特征可以再细分为定序特征和定类特征,定类特征是指特征仅仅具有类别关系,比如性别特征,只有‘男’和‘女’之分;定类特征是指特征不仅具有类别关系,同时还表示特征间的序列关系,比如受教育程度,”小学”、”中学”,”高中”和”大学”。我对定序特征全部转换为序列的数值,对定类特征全部转换为哑变量。
- 第3步 将空值补-1 .经过以上三步,就得到了一版可以使用的特征组了,能够代入模型进行预测。因为这时还没生成新的特征,我们记为“原始特征”。
第4步 开始发掘特征潜在信息,构造新的特征。
- 4.1 对空值进行分析。将每一行的空值进行统计,或者将每一行中重要 特征的空值进行统计,得出一个空值个数,作为一列。再将个数进行离散化分类,作为一列。
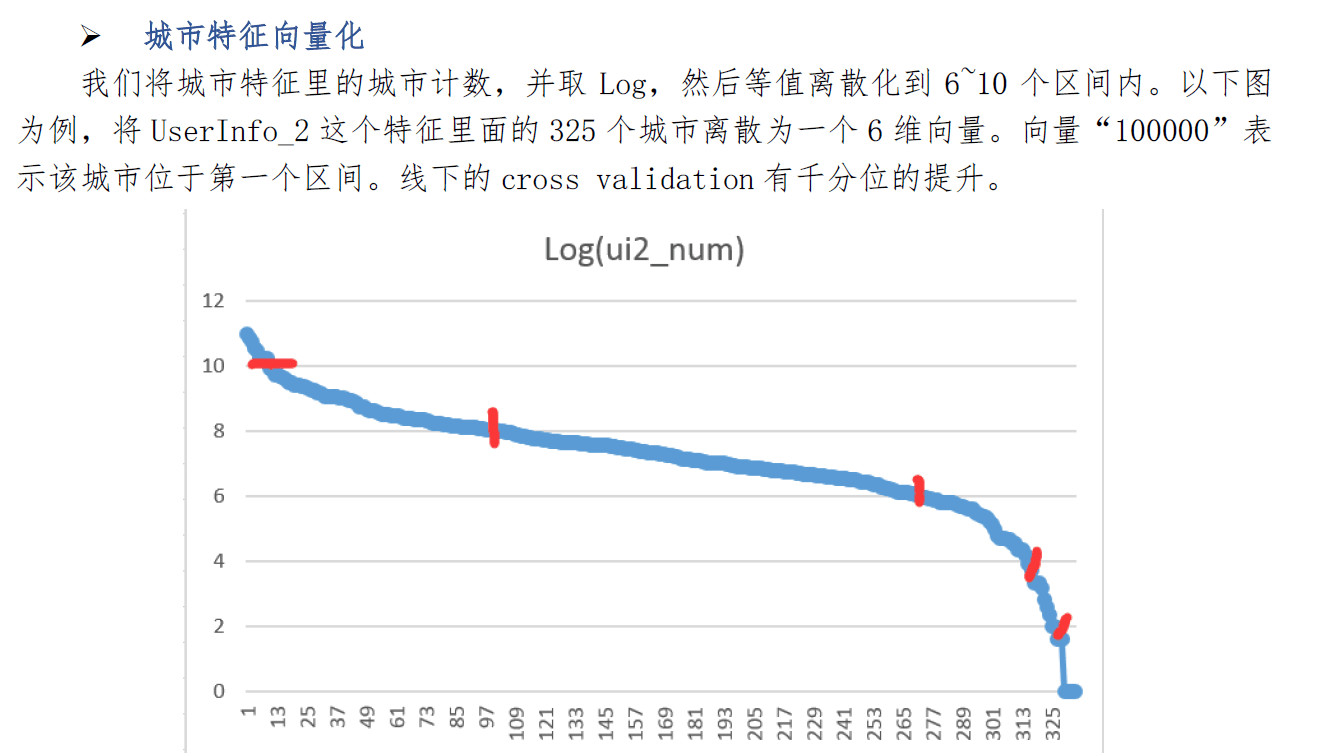
- 4.2 对数值型特征进行分析。对数值型特征可以先根据其值,进行排序,将排序的序号作为新的特征。这样对于每一列数值型都会有一列新的特征生成。在此基础上还可以再根据排序特征再进行离散化处理,可以处理成[6~10]个区间,这样就生成了同样列数的离散化特征。最后,基于离散化特征中每一行中每个数值的个数进行统计,会得到[6~10]列计数特征。
- 4.3 对数组型特征进行特征组合。通常组合方式有x*y x/y x^2+y^2 1/x+1/y 等方式。这要看具体的数据,如果是数据中包含0值,有关除的运算就不能使用。但或许可以尝试在该特征的变型特征上使用。最后有关特征组合,可能在 相对重要的特征上效果更好一些。
4.4 对类别型特征进行分析。类别行特征进行分箱处理(频率聚类),在此基础上可以再log一下。
简单说一下分箱:它是通过考察周围的值来平滑存储数据的值。存储的值被分布到箱中,由于分箱方法参考相邻的值,因此它可以局部平滑。它的一般步骤是: 1,排序数据,然后以等深分箱法(按记录数分箱)或者是等宽分箱法(按区间范围分箱)将数据分到各个箱子里。2,按照每个箱子中的平均值或者中值或者边界值进行平滑。
本图来自网络- 4.5 对于一些时间序列的周期特征,可以考虑对周期进行合并,来消除数据之间的共线性问题。比如说提取出第一个周期特征,最大最小值,中值,方差这几个特征。
- 4.6 添加外部数据 这里最明显的就是地理位置。对于地理位置,可以从网上找到两份文件,一份是全国城市地理位置经纬度表,一份是全国城市等级排名。第一份表将离散的地理位置转换成来了连续的经纬度值,使得地理位置关系信息充分表达,第二份表体现了城市间的贫富关系,等价于对所有城市离散化类别。
- 第5步,特征选择。经过第四步的过程,会生成大量的特征,里面有优秀的特征,也有无用的特征。如果不加以选择,反而会造成维度灾难。特征选择的常用方法一般分为两种,一种是系数型:考虑每一列特征与label 之间的线性或者非线性关系。比如pearson能够发现特征间的线性关系。一种是基于模型的特征重要性排序:每一个模型在设置好合适的参数训练完毕之后,会对所有特征进行打分,可以看出特征针对于该模型的重要程度。
- 第6步 模型训练与调优 这块内容我在之前博客里已经提及,这里就不再细说了。
- 第7步,模型融合。模型融合是一项很重要的工作。究其原因是因为对于每个单模型来说,它都有自己擅长的地方,它们处理特征的方式不一样,处理特征的方法不一样,对于这些具有差异性的模型进行融合,一般来说能够形成合力,使得预测效果更加有效。模型融合的方法很多,简单的方法通常是各个单模型取得最优之后,再去做一个加权计算。复杂的方法可能如模型套模型的组合,这样的方法需要经验丰富才敢使用,因为它的可解释性差。
以上是我和另外两名队友做比赛的一点经验,由于我组水平尚浅,以复赛第27名结束比赛(初赛500选100,复赛100选6)。比赛过程中遇见到不少大神,founder,BRYAN等等,学到了很多数据挖掘的经验。以后继续努力,继续挑战!
这篇关于科赛网 魔镜杯“风控算法比赛”赛后总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







