本文主要是介绍CoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
名词解释
1.特征重建
特征重建是一种机器学习中常用的技术,通常用于自监督学习或无监督学习任务。在特征重建中,模型被要求将输入数据经过编码器(encoder)转换成某种表示,然后再经过解码器(decoder)将这种表示转换回原始的输入数据。
具体来说,特征重建的过程通常分为以下几个步骤:
1.编码(Encoding): 输入数据经过编码器,被映射到一个低维度的表示空间中,这个表示通常称为特征向量或隐藏表示。
2.重建(Reconstruction): 编码后的特征向量再经过解码器,被映射回原始的输入空间,尝试重建原始输入数据。
3.损失计算(Loss Computation): 通过比较重建数据与原始数据之间的差异,计算出重建误差或损失值。
4.优化(Optimization): 模型被训练以最小化重建误差,通过调整编码器和解码器的参数来提高重建的准确性。
在自监督学习中,通常使用无标签的数据来进行特征重建,因此模型必须依靠数据本身来学习如何有效地表示和重建输入。这样做的好处在于可以在本身是无监督的任务中,图片本身自己去学习自己的有用表示,有助于提取图片中的关键信息,从而提高后续任务的性能。因为往常的视频分割任务通常都会有人工标注的昂贵的注释集,而本文应用特征重建是由于语义的异质性,边界处的帧很难重建(通常具有较大的重建误差),这有利于事件边界检测(这样就能很容易检测出边界)。
2.语义视觉表示
语义视觉表示是指通过计算机视觉技术将图像或视频数据转换为具有语义含义的向量或特征表示。这种表示捕捉了图像或视频中物体、场景和动作等高级概念的语义信息,而不仅仅是低级的像素值或几何特征。
在语义视觉表示中,模型通常会学习到与物体类别、场景描述或动作等相关的特征,这些特征具有更高层次的抽象性,能够更好地反映数据的语义内容。这种表示有助于计算机理解图像或视频,并支持各种计算机视觉任务,如物体识别、场景理解、行为分析等。
语义视觉表示的生成可以通过多种方式实现,包括传统的手工设计特征提取器、基于深度学习的端到端表示学习方法以及结合语义信息的生成式模型等。随着深度学习技术的发展,基于深度神经网络的方法已经成为生成语义视觉表示的主流方法之一,这些方法可以在大规模数据集上进行端到端的训练,从而学习到更加丰富和高效的语义表示。
总的来说,语义视觉表示是计算机视觉领域中一种重要的数据表示形式,它将图像或视频转换为具有语义含义的向量表示,为各种视觉任务提供了有力支持。
3.特征空间和像素空间
特征空间和像素空间是在计算机视觉和机器学习中经常提到的两个概念,它们描述了数据在不同层次上的表示方式和表达内容的不同。
1.像素空间:
在像素空间中,图像被表示为一个由像素组成的矩阵,每个像素包含有关图像中某个位置的颜色或灰度信息。像素空间是图像的原始表示形式,它反映了图像中每个位置的具体像素值,通常是RGB颜色空间中的值或灰度值。像素空间中的操作通常是基于像素级别的,例如图像增强、滤波、边缘检测等处理都是直接在像素空间上进行的。
2.特征空间:
在特征空间中,图像被表示为一组抽象的特征向量或特征表示,这些特征捕捉了图像中的语义信息和高级结构。特征空间中的特征通常是通过特征提取器或深度神经网络从原始图像中学习得到的,它们可能表示物体、场景、纹理等高级概念。特征空间的表示更加抽象和语义化,它能够更好地捕捉到图像的语义内容,而不仅仅是像素级别的细节。在特征空间中进行的操作通常是基于特征级别的,例如特征重建、特征匹配、语义分割等处理都是在特征空间上进行的。
总的来说,像素空间和特征空间代表了数据在不同层次上的表达方式,像素空间更接近于原始数据的表示,而特征空间则更加抽象和语义化,能够捕捉到数据的高级结构和语义信息。个人理解就是,像素空间就是一张图片的原始矩阵,原始矩阵经过卷积等操作后被转为特征图,特征图代表的语义信息 更丰富更抽象,之后特征重建是在特征图上重建的。
框架
1.Contrastive Temporal Feature Embedding(CTFE)
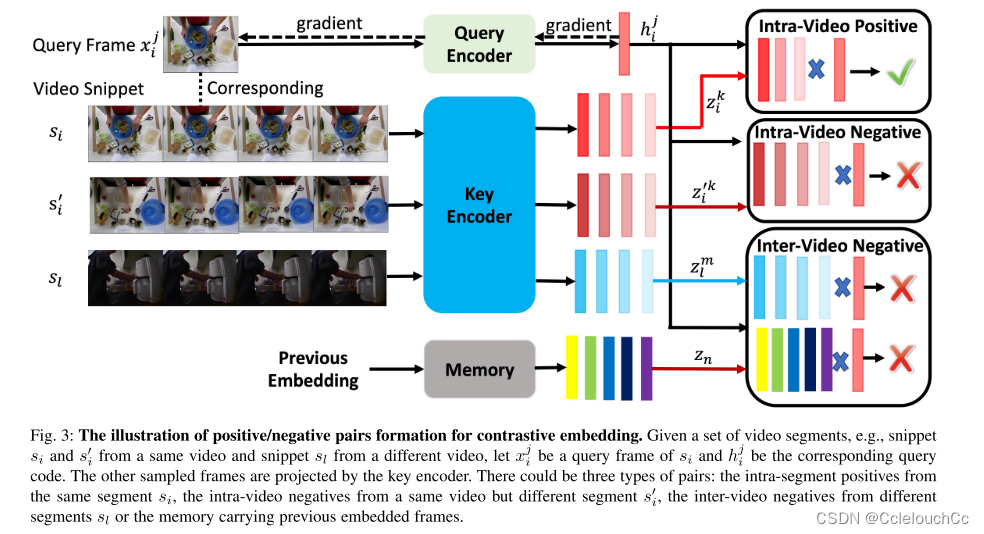
通常,视频事件由语义相关的帧的序列组成。也就是说,相邻帧比以长时间间隔采样的帧更可能在语义上相似。根据这一观察,我们提出了一个对比时间特征嵌入方案来学习一个有区别的帧表示。从本质上讲,它将语义相似的框架投射得更近,而将不相似的框架推开。通过比较,利用这种学习,我们的框架将帧转换为一种新的表示,在语义上更容易区分。如图3所示,对比学习的正对由段内帧组成,而负对来自来自相同或其他视频的其他片段的段间帧,或存储器中的帧。
总体思路为选取B个视频,在每个视频里选择X个片段(片段帧数为T)。以图3为例:共选取了视频的三个片段,S(i)、S’(j)是同一个视频的不同片段,S(l)是别的视频的一个片段。首先,取S(i)中的一帧作为查询键Q,其他片段的一帧作为被查询键K,接下来,我们形成与查询xj i相关联的三种类型的否定对:1)视频内否定对:否定帧来自相同的视频,但来自不同的片段,即X’(j)的帧。2)视频间负对:负帧选自从不同视频提取的任何片段,即X(l)的帧。3)存储器负对:负帧来自在先前迭代期间嵌入在存储器中的帧。然后,将两帧进行对比学习,来判断它们是正样本还是负样本,图3表示的是Q与K来自于同一个视频的正样本。
利用这种学习,我们的框架将帧转换为一种新的表示,在语义上更容易区分。这对本质上是二分类的任务是友好的。
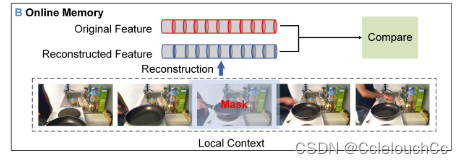
Frame Feature Reconstruction (FFR)
如我们所知,视频事件之间的过渡帧通常是不一致的,因此较难预测。因此,我们开发了一种无监督的特征重建方法来检测这些事件的边界,因为我们推测,边界帧通常比非边界帧具有更高的重建误差。然而,与之前的像素级图像重建不同,我们的帧重建是在高级语义特征空间中进行的。也就是说,我们的方法旨在重建由CTFE训练的框架的语义表示。
为了从H0(t)重构掩蔽的特征向量,我们修改了Transformer编码器的多头注意部分。具体来说,我们采用2层多头自注意(MSA)和多层感知器(MLP)块来处理H0,同时随机将掩码M(t)应用于第t个特征嵌入。重构模块的第l层的输出被定义为
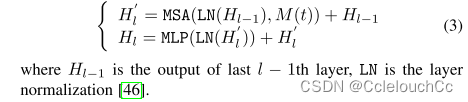
重构模块的第l层的输出可以用如下方式定义:已知l层的输入来自于l-1层的输出
参数为掩掉的某一帧M(t)和l-1层的输出H(l-1),首先对M(t)和H(l-1)进行层归一化,保证训练稳定,再经过多头注意力机制计算得到具有时间上下文的语义信息,再和上一层输出相加后经过多层感知机输出。
整体框架
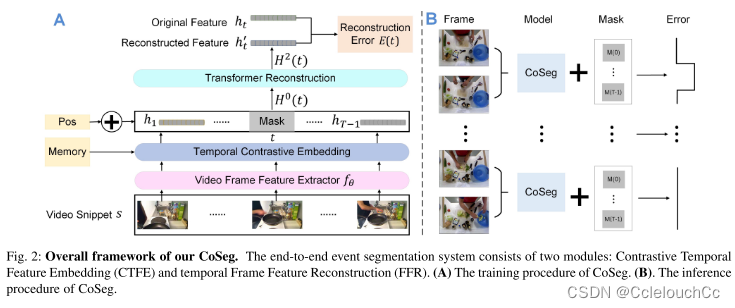
A:train
1.视频片段经过特征提取网络变成特征图。
2.CTFE模块对特征图进行处理,得到更高级的表示。
3.经过CTFE得到的表示送入FFR模块,进行特征重建,得到重建后的特征。
4.重建后的特征图与原特征图进行比较,特征重建是由于语义的异质性,边界处的帧很难重建(通常具有较大的重建误差),这有利于事件边界检测(这样就能很容易检测出边界)。
B:test
将视频帧送入模型,再逐个地对每一帧进行掩码,从而重建所有帧的特征,与原特征进行比较后有两种结果,一种是上半部构建错误,即检测到边界帧,另一种是下半部构建成功,即无边界帧。
这篇关于CoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









