本文主要是介绍异方差性以及加权最小二乘优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
异方差性(heteroscedasticity )是相对于同方差而言的。所谓同方差,是为了保证回归参数估计量具有良好的统计性质,经典线性回归模型的一个重要假定:总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,即:随机误差项具有不同的方差,则称线性回归模型存在异方差性。对于异方差性的回归问题,需要用到加权最小二乘法。
以下内容转自:https://zhuanlan.zhihu.com/p/22064801
一.前言
在往前可以看得见的历史里,我们漫长的一生中不知道做了多少个回归,然而并不是每一个回归都尽如人意,究其原因就很多了,可能是回归的方程选择的不好,也可能是参数估计的方法不合适。回归的本质是在探寻因变量Y和自变量X之间的影响关系国外的论文里常常叫因变量为响应变量,自变量为解释变量),如何来描述这种相关关系呢?我们可以假设Y的值由两部分组成,一部分是X能决定的,记为f(X),另一部分由其它众多未加考虑的因素(如随机因素)所组成,记为随机误差e,并且我们有理由认为E(e)=0.于是我们得到
特别地,当f(X)是线性函数时,我们便得到了众多回归组成的王国里最平民也最重要的回归模型——线性回归。回归参数的估计方法最基本的就是最小二乘回归。尽管长江后浪推前浪,我们有了更多回归参数的估计方法(详见优矿量化实验室),但依然不影响我们对它的喜爱,为了介绍后续的回归方法,我依然要先把普通最小二乘法的回归模型摆出来致敬一下:
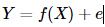 特别地,当f(X)是线性函数时,我们便得到了众多回归组成的王国里最平民也最重要的回归模型——线性回归。回归参数的估计方法最基本的就是最小二乘回归。尽管长江后浪推前浪,我们有了更多回归参数的估计方法(详见优矿量化实验室),但依然不影响我们对它的喜爱,为了介绍后续的回归方法,我依然要先把普通最小二乘法的回归模型摆出来致敬一下:
特别地,当f(X)是线性函数时,我们便得到了众多回归组成的王国里最平民也最重要的回归模型——线性回归。回归参数的估计方法最基本的就是最小二乘回归。尽管长江后浪推前浪,我们有了更多回归参数的估计方法(详见优矿量化实验室),但依然不影响我们对它的喜爱,为了介绍后续的回归方法,我依然要先把普通最小二乘法的回归模型摆出来致敬一下:这里的Y就是n∗1的变量观测向量,X为n∗p的已知设计矩阵,β为p∗1未知参数向量,e为随机误差向量。(这里需要注意的是由于有常数项,所以自变量个数其实是p-1个)
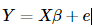 这里的Y就是n∗1的变量观测向量,X为n∗p的已知设计矩阵,β为p∗1未知参数向量,e为随机误差向量。(这里需要注意的是由于有常数项,所以自变量个数其实是p-1个)
这里的Y就是n∗1的变量观测向量,X为n∗p的已知设计矩阵,β为p∗1未知参数向量,e为随机误差向量。(这里需要注意的是由于有常数项,所以自变量个数其实是p-1个)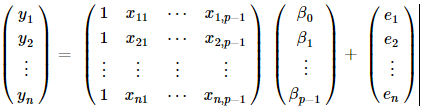
Gauss-Markov假设可以简写为E(e)=0,Cov(e)=In,Cov(e,x)=0
普通最小二乘法就是使得残差平方和最小,通过对矩阵的求导,我们就得到了β的估计Y,在假设下,我们可以证明该估计是β所有线性无偏估计中方差最小的。
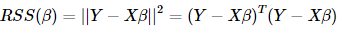 最小,通过对矩阵的求导,我们就得到了β的估计
最小,通过对矩阵的求导,我们就得到了β的估计与之相关的各种分布和检验就不再赘述,社区里也有很多帖子可以学习。既然模型有假设,那么局限性就出来了,我们常常会发现残差项并不满足假设,尤其当变量是时间序列时,非平稳性和自相关性常常会造成异方差的问题,那怎么处理异方差的问题呢?方法也挺多的,本帖主要讨论一种加权最小二乘估计的方法和机器学习里局部加权线性回归的方法。(注:此文中的线性回归是普适的多元线性回归,所以均用矩阵来表示更方便)
二.加权最小二乘法
加权最小二乘法其实是广义最小二乘法的一种特殊情形,而普通最小二乘法也是一种特殊的加权最小二乘法。为了保证知识的完整性,不妨把广义最小二乘介绍一下:
1.广义最小二乘法
刚才说到我们的残差项项不满足Gauss-Markov假设,那么我们就把假设放宽一些:考虑以下模型:
这里的Σ是我们已知的一个n∗n正定对称矩阵,其中不一定是已知的。也就是说不要求误差项互不相关了。这里我们的广义最小二乘法就是使得广义残差平方和
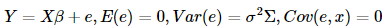 这里的Σ是我们已知的一个n∗n正定对称矩阵,其中
这里的Σ是我们已知的一个n∗n正定对称矩阵,其中最小,最后β的估计为(X)−1Y
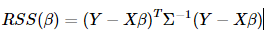 最小,最后β的估计为(
最小,最后β的估计为(实际上,Σ也常常是未知的,但当我们知道Σ的某种形式时,我们可以去估计它。举个例子,如果出于某种原因,我们样本的数据来源的地方不一样,怎样把他们整合在一起呢,我们可以假设那些来源相同的数据样本的残差项方差是一样的,如:
然后我们再通过迭代的方法(第一步就是普通的最小二乘回归)去估计,直到相邻两次迭代求得的β的估计差不多为止。
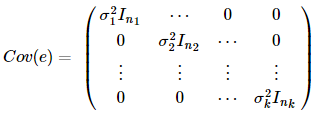 然后我们再通过迭代的方法(第一步就是普通的最小二乘回归)去估计
然后我们再通过迭代的方法(第一步就是普通的最小二乘回归)去估计从上面可以看出,不论你对自变量和因变量作了何等变换,最终都可以用最小二乘的模型去解决回归的问题。但普通最小二乘估计里的那些美好的性质,分布和检验等在广义最小二乘里还存在么?还一致么?其实,我们可以通过一些变换,把广义最小二乘的模型转换为满足普通最小二乘法假设的模型,关于这一点,我们以下面的加权最小二乘法举例说明。
2.加权最小二乘法
加权最小二乘法,就是对上述的Σ取一种特殊的矩阵--对角阵,而这个对角阵的对角元都是常数,也就是权重的倒数,如下:
表示的就是第i个样本在回归里的权重,从上式可以看出来,具有较大权的样本具有较小的方差,它在回归问题里显得更加重要。 不妨用W来表示权重矩阵,那么=W,这时我们用广义最小二乘的方法来求系数的估计,即最小化广义残差平方和
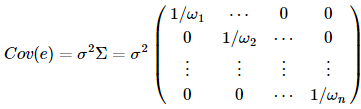
β最后的估计结果为:β^=(WX)−1WY
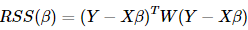 β最后的估计结果为:β^=(
β最后的估计结果为:β^=(我们并不满足于求出广义的最小二乘估计,我们还要研究它的很多性质,下面上面提过的广义最小二乘转换的方法把这个模型转化为满足普通最小二乘回归假设的模型:
首先我们找一下的平方根C,在这个问题里,很容易得到C:
对回归模型每一项乘以C,得到:
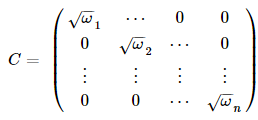 对回归模型每一项乘以C,得到:
对回归模型每一项乘以C,得到:这时候Ce的协方差阵为:
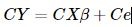 这时候Ce的协方差阵为:
这时候Ce的协方差阵为:这就是满足Gauss-Markov假设的普通线性回归模型了
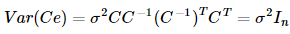 这就是满足Gauss-Markov假设的普通线性回归模型了
这就是满足Gauss-Markov假设的普通线性回归模型了不妨重新对变量命名:
其中,
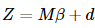 其中,
其中,感兴趣的读者可以验证一下,这个新模型用普通最小二乘所估计出来的β和原模型是一样的,而且线性无偏方差最小的性质和分布,检验等都可以用起来了,如及显著性检验等来看拟合的好坏。
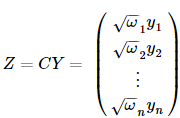
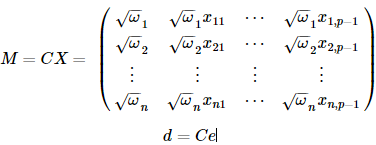 感兴趣的读者可以验证一下,这个新模型用普通最小二乘所估计出来的β和原模型是一样的,而且线性无偏方差最小的性质和分布,检验等都可以用起来了,如
感兴趣的读者可以验证一下,这个新模型用普通最小二乘所估计出来的β和原模型是一样的,而且线性无偏方差最小的性质和分布,检验等都可以用起来了,如三.局部加权线性回归
局部加权线性回归是机器学习里的一种经典的方法,弥补了普通线性回归模型欠拟合或者过拟合的问题。机器学习里分为无监督学习和有监督学习,线性回归里是属于有监督的学习。普通的线性回归属于参数学习算法(parametric learning algorithm);而局部加权线性回归属于非参数学习算法(non-parametric learning algorithm)。所谓参数学习算法它有固定的明确的参数,参数 一旦确定,就不会改变了,我们不需要在保留训练集中的训练样本。而非参数学习算法,每进行一次预测,就需要重新学习一组 , 是变化的,所以需要一直保留训练样本。也就是说,当训练集的容量较大时,非参数学习算法需要占用更多的存储空间。
上面的话好像不够直观,下面我们来直观地看一下局部加权线性回归到底是怎么样的。
局部加权线性回归就是在给待测点附近的每个点赋予一定的权重,也就是加一个核函数矩阵W,最后需要最小化的目标函数如下:
这就是刚刚的加权最小二乘法,再来看看系数的估计项:
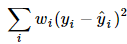 这就是刚刚的加权最小二乘法,再来看看系数的估计项:
这就是刚刚的加权最小二乘法,再来看看系数的估计项:好吧,这就是加权最小二乘法,当然,如果这就是局部加权线性回归的全部,也不用发明它了,我们接着看。这里出现了一个问题,权重是如何确定的,也就是这个所谓的核函数矩阵的形式,百度了一下,通常使用的都是高斯核,形式如下:
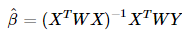
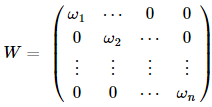 好吧,这就是加权最小二乘法,当然,如果这就是局部加权线性回归的全部,也不用发明它了,我们接着看。这里出现了一个问题,权重是如何确定的,也就是这个所谓的核函数矩阵的形式,百度了一下,通常使用的都是高斯核,形式如下:
好吧,这就是加权最小二乘法,当然,如果这就是局部加权线性回归的全部,也不用发明它了,我们接着看。这里出现了一个问题,权重是如何确定的,也就是这个所谓的核函数矩阵的形式,百度了一下,通常使用的都是高斯核,形式如下:代表的是第i个样本点,x是我们预测点,对于金融数据来说,完全可以用时间t来衡量,也就是说时间越近的样本数据越重要,这样的预测对想研究的对象而言更准确。
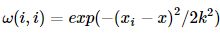
介绍到这里似乎没有体现出机器学习的意思,仔细观察就会发现K是一个很重要的东西,不信,我们举个例子来看看:
为了简单起见,我们就用一元的线性回归来看看,方便数据可视化。这里我们取一些非线性拟合的数据,因为局部加权线性回归的优势就在于处理非线性关系的异方差问题。
看一下我们需要拟合的样本数据(点击查看原文代码):
很明显,这是一个非线性关系的样本数据,我们先用普通最小二乘回归来处理这个问题:
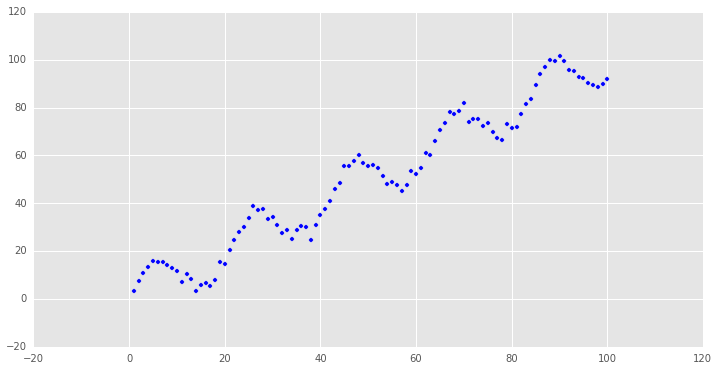 很明显,这是一个非线性关系的样本数据,我们先用普通最小二乘回归来处理这个问题:
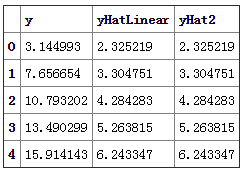
很明显,这是一个非线性关系的样本数据,我们先用普通最小二乘回归来处理这个问题:y=1.34568655273+0.979532165941x
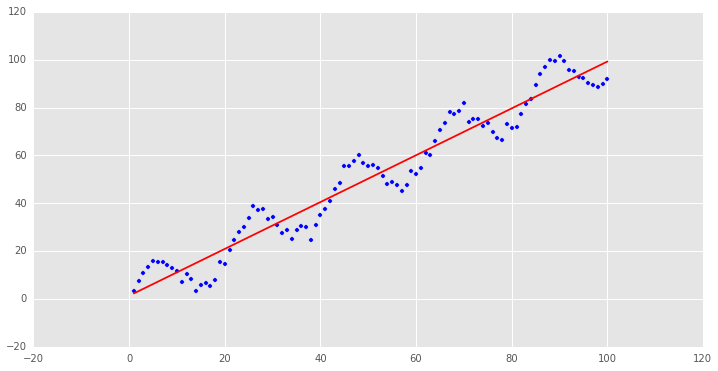
可以看到,要用直线来拟合非线性关系略有牵强,这个例子还算举的不错,金融数据里很多时间序列的关系都是非线性的,回归的结果往往不好.
下面我们用刚才介绍的局部加权线性回归来拟合一下这个模型,简单回顾一下过程:
1.用高斯核函数计算出第i个样本处,其它所有样本点的权重W
2.用权重w对第i个样本作加权线性回归,得到回归方程,即拟合的直线方程
3.用刚才得到的经验回归直线计算出xi处的估计值y^i
4.重复一至三步,得到每个样本点的估计值
这里作加权线性回归时,我使用的是把加权最小二乘转换为普通最小二乘的方法,也就是本帖第二部分内容,网上的做法大多是直接用上面的公式算出β的估计值。
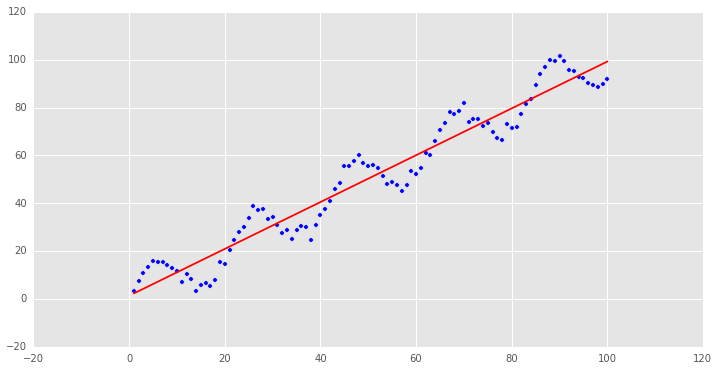
刚才说到,k是一个很关键的参数,我们从高斯函数的形式可以看出,k取非常大的时候,每个样本点的权重都趋近于1,我们可以先取k很大,检验一下是否正确
可以看到用普通最小二乘估计出来的值和我们用局部加权估计出来的值非常的一致,说明逻辑是对的。 下面调整一下k的值,来看看各种k值下的拟合状况:
 可以看到用普通最小二乘估计出来的值和我们用局部加权估计出来的值非常的一致,说明逻辑是对的。 下面调整一下k的值,来看看各种k值下的拟合状况:
可以看到用普通最小二乘估计出来的值和我们用局部加权估计出来的值非常的一致,说明逻辑是对的。 下面调整一下k的值,来看看各种k值下的拟合状况:可以看到,当k越小时,拟合的效果越好,但是我们拟合的目的在于预测,需要避免过拟合的问题,这时候需要做Bias/Variance Trade-off:
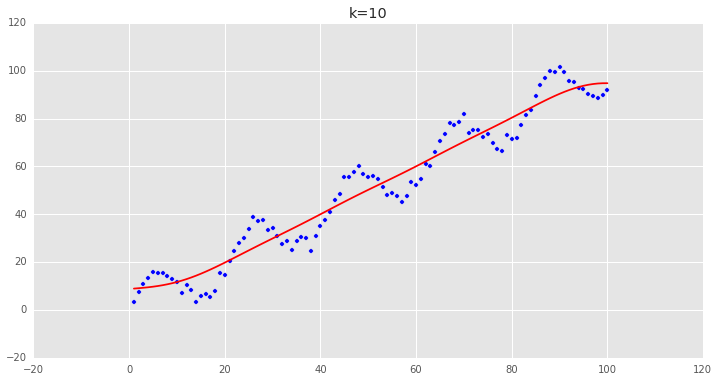
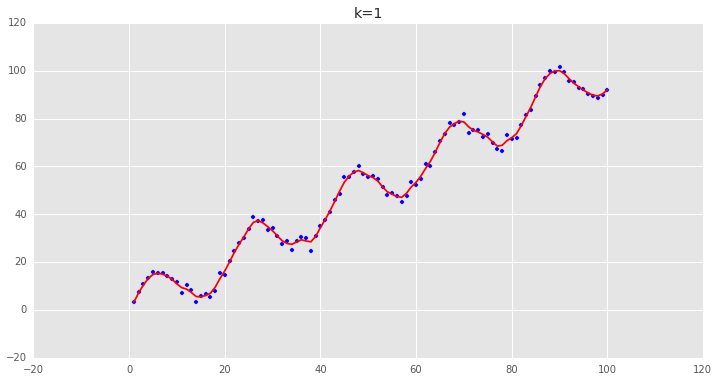
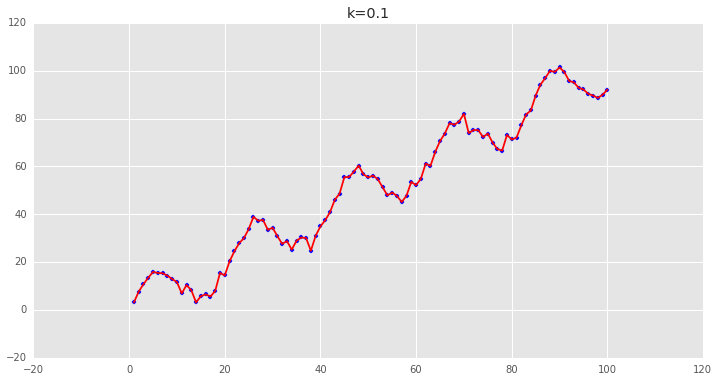 可以看到,当k越小时,拟合的效果越好,但是我们拟合的目的在于预测,需要避免过拟合的问题,这时候需要做Bias/Variance Trade-off:
可以看到,当k越小时,拟合的效果越好,但是我们拟合的目的在于预测,需要避免过拟合的问题,这时候需要做Bias/Variance Trade-off: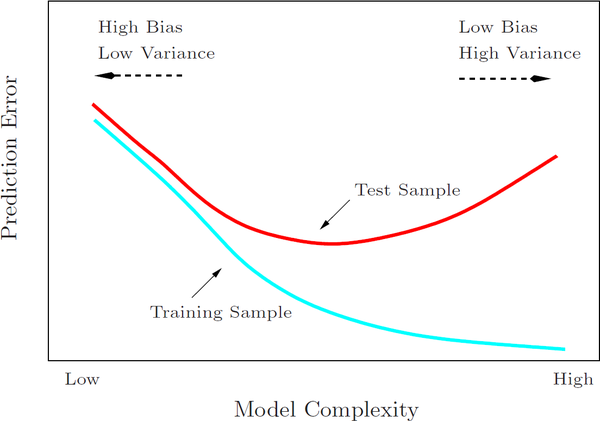
Cross Validation可以帮助我们做Bias/Variance Trade-off:
一般的Validation就是把数据分为随机的两部分一部分做训练,一部分作验证。还有leave-one-out validation,k-fold Cross Validation等方法。
训练的目的是为了让训练误差尽量减小,同时也要注意模型的自由度(参数个数),避免测试误差很大。
训练误差一般用MSE来衡量:
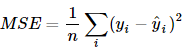
比如在我们这个简单的例子里,如果要对之后的数据进行预测,就需要通过Validation选择参数k的大小,再对离需要预测的点最近的点做加权线性回归去估计那个点的值。
这篇关于异方差性以及加权最小二乘优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


