本文主要是介绍【RAG 论文】FiD:一种将 retrieved docs 合并输入给 LM 的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文: Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
⭐⭐⭐⭐
EACL 2021, Facebook AI Research
论文速读
在 RAG 中,如何将检索出的 passages 做聚合并输入到生成模型是一个问题,本文提出了一个简单有效的方案:FiD。
下图是一个简单的 open-domain QA 的使用方式,它直接将 question 和检索到的所有 passages 拼接起来,以 <question, retrieved passages> 的形式扔给 seq2seq 模型来生成 answer:
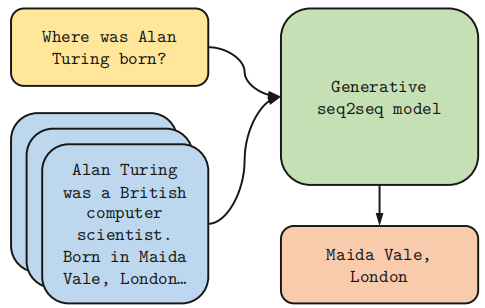
这种处理方式中,随着 retrieved passages 的数量增多,由于 Self-Attention 的运算机制,计算复杂度会呈现二次增长。
本论文提出了一个简单直接的方法 —— FiD(Fusion-in-Decoder)—— 将检索回来的每一个 passage 都独立与 question 用一些特殊符号作为间隔拼接起来并输给 encoder 做编码,然后 concat 在一起输入给 decoder 生成 final answer,所以称之为 Fusion-in-Decoder:

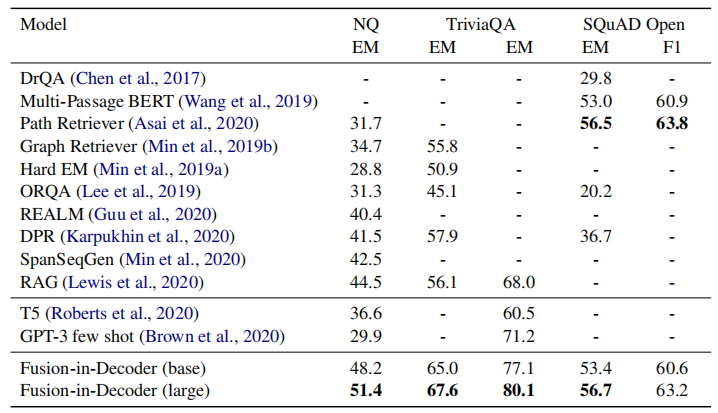
尽管方法简单,但效果却出奇的好,在当时 TriviaQA 和 NaturalQuestions 的 benchmark 上达到了 SOTA 水平:
While conceptually simple, this method sets new state-of-the-art results on the TriviaQA and NaturalQuestions benchmarks.
同时,作者认为,与检索模型相比,生成模型非常善于将多个 passages 的信息进行合成,所以本工作的 retrieved passages 的合成工作是交给了生成模型的 Decoder 来做的:
We believe that this is evidence that generative mod els are good at combining evidence from multiple passages, compared to extractive ones.
实验结果
与其他 baselines 的对比:
作者还测试了一下 FiD 在 valid set 上的 performance 与 retrieved passages 数量的函数关系:
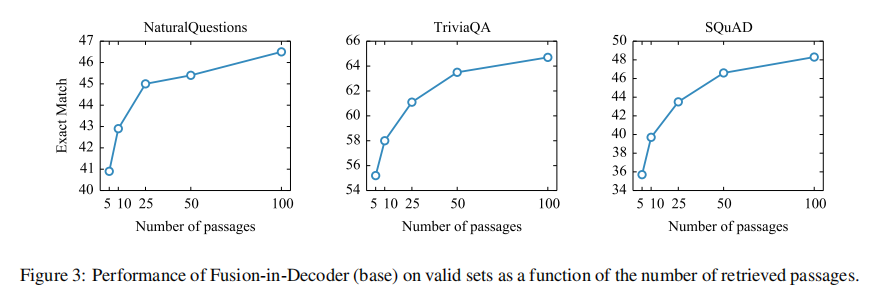
可以看到,随着输入的 passages 越多,模型的性能就越好,但同时由于拼接后给 decoder 的输入变长,肯定会伴随着计算机内存的增长。
总结
FiD 给出了一种将 retrieved passages 如何聚合输入给生成模型的思路,这种方法相比于传统的全部拼接再给 LLM 的优势在于:
- encoder 独立处理每个 passage,因此只需要在一个 passage 上执行 self-attention,这意味着模型的计算时间随着段落数量呈线性增长,而非二次增长。
- 由 decoder 来联合聚合多个 retrieved passages,可以更好的从中找到相关支持信息。
论文最后指出,如何将 FiD 更好集成到 RAG 模型仍然值得探索。
这篇关于【RAG 论文】FiD:一种将 retrieved docs 合并输入给 LM 的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







