本文主要是介绍Attention Sink,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文发现自回归LLM存在的一个有趣现象:对于输入文本最靠前的少量几个token,无论它们在语义上与语言建模任务的相关性如何,大量的注意力分数都会分配给他们,如下图所示:
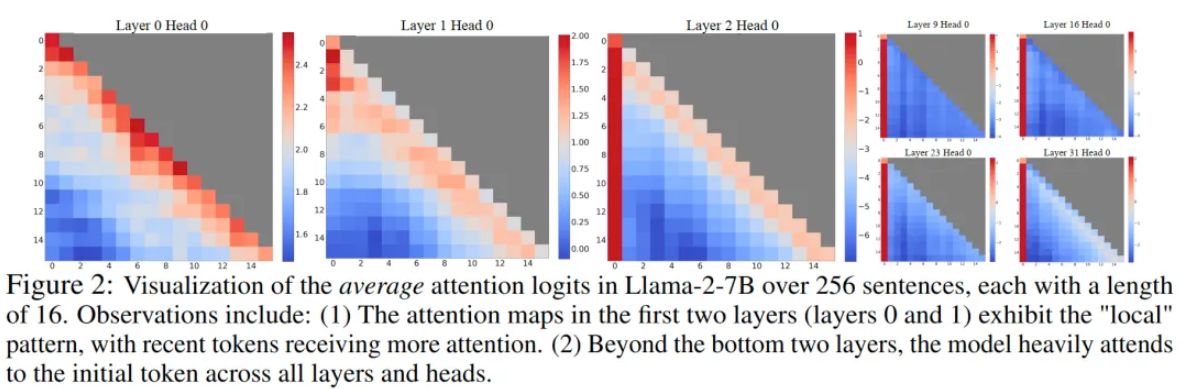
模型的前两层还能保持attention score更多分配给当前token附近位置的特性,而在其他层,靠前的几个token都会接受到大量的注意力。尽管这些token在语义上很可能并没有什么重要性,但它们却聚集了大量的注意力分数。
出现这个现象的原因就是softmax操作。softmax要求所有上下文token的注意力分数加起来等于1。因此,即使当前token跟前面的其他token都没有语义相关性,模型仍然需要将多余的注意力值分配到前面的某些token,以使得总和为1。
为什么最开头的几个初始token就会承担“接收多余的、不需要的注意力”的任务?最简单的原因就是,对于自回归语言建模,初始token对所有后续token都是可见的,这使得它们更容易被训练成attention sink。
上面这个解释还只是猜想,于是论文做了一个实验来验证这个猜想:把初始的4个token都换成没有重要实际语义的换行符号\n,结果发现模型依然会把大量的注意力分配给这些token,这就说明attention sink这个现象和内容语义无关,而只和这些token所在的位置相关。
参考
- 大模型推理窗口-从有限到无限大
这篇关于Attention Sink的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









