sink专题

大数据-117 - Flink DataStream Sink 案例:写出到MySQL、写出到Kafka
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(正在更新!) 章节内容 上节我们完成了如下的内容: Sink 的基本概念等内

大数据-116 - Flink DataStream Sink 原理、概念、常见Sink类型 配置与使用 附带案例1:消费Kafka写到Redis
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(正在更新!) 章节内容 上节我们完成了如下的内容: Flink DataSt

innovus:如何让部分sink长到target insertion delay的长度
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 来自星球提问: 参考命

如何在QCC实现source和sink app合在一起
如何在QCC实现source和sink app合在一起 <?xml version="1.0" encoding="utf-8"?> <!--Copyright (c) 2018 Qualcomm Technologies International, Ltd.--> <message_map> <message_group name="default_message_

spdlog日志库源码:输出通道sink
概述 在 spdlog 日志库中,sinks 并不是一个单独的类,而是一系列类的集合,这些类以基类-派生类的形式组织,每一个 sink 派生类代表了一种输出日志消息的方式。输出目标可以是普通文件、标准输出 (stdout)、标准错误输出 (stderr)、系统日志 (syslog) 等等。其文件位于include/spdlog/sinks中 sink类 类sink是所有sinks系列类的基类

ECP5701 做为PD受电端取电sink芯片,可广泛应用在带锂电的终端设备上,例如电动工具,照明灯具,音箱设备,摄影设备,筋膜枪小家电等
随着科技的发展,USB-C接口逐渐成为手机、平板电脑、小型家电等新型电子设备的主流接口,相较于过去繁杂的传统接口,USB-C不仅简化了消费者的使用体验,也降低了制造商的生产成本。特别是随着PD协议的普及,Type-C接口因其支持正反插和高达240W的充电功率,正逐渐取代microUSB以及各类专用DC适配器。而为了实现USB-C接口的高效电力和数据传输,设备内部需要集成符合USB PD标准的握手协

flume的项目实现自定义sink的输出端
详细的flume工程代码见百度网盘: 实现的功能:监听某个文件的最新输入,让后将其输入到制定文件中。 #配置文件:push.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the

Android14音频进阶之dump各阶段音频数据<Tee Sink方案>(七十五)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒体系统工程师系列【原创干货持续更新中……】🚀 优质视频课程:AAOS车载系统+AOSP14系统攻城狮入门实战课【原创干货持续更新中……】🚀 人生格言:
Flink(3):DataSet的Source、Transform和Sink算子,以及计数器
一、概述 Flink批处理DataSet的处理流程Source、Transform和Sink算子。 二、source 【参考:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/batch/#data-sources】 1.基于文件创建 (1)readTextFile(path) / TextInputForma
Flink error:No data sinks have been created yet. A program needs at least one sink that consumes dat
一、问题描述 Flink程序,批处理程序,执行报错: Exception in thread "main" java.lang.RuntimeException: No data sinks have been created yet. A program needs at least one sink that consumes data. Examples are writing the
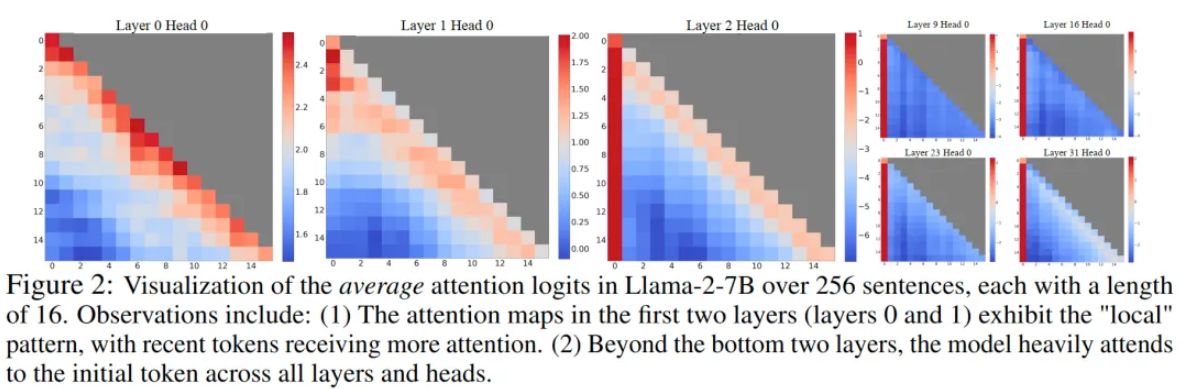
Attention Sink
论文发现自回归LLM存在的一个有趣现象:对于输入文本最靠前的少量几个token,无论它们在语义上与语言建模任务的相关性如何,大量的注意力分数都会分配给他们,如下图所示: 模型的前两层还能保持attention score更多分配给当前token附近位置的特性,而在其他层,靠前的几个token都会接受到大量的注意力。尽管这些token在语义上很可能并没有什么重要性,但它们却聚集了大量的注意力分数
![【DDR 终端稳压器】Sink and Source DDR Termination Regulator [C] S0 S1 S2 S3 S4 S5 6状态](https://img-blog.csdnimg.cn/direct/227ed36e2d5a4fefbb590fa1532e90b7.png)
【DDR 终端稳压器】Sink and Source DDR Termination Regulator [C] S0 S1 S2 S3 S4 S5 6状态
TPS51200A-Q1 器件通过 EN 功能提供 S3 支持。EN引脚可以连接到终端应用中的SLP_S3信号。当EN = 高电平(S0 状态)时,REFOUT 和 VO 引脚均导通。当EN = 低电平(S3状态)时,VO引脚关断并通过内部放电MOSFET放电时,REFOUT引脚保持不变。当EN = 低电平且REFIN电压小于0.390 V时,TPS51200A-Q1器件进入伪S5状态。当伪S5
Flink写出数据到Hbase的Sink
文章目录 一、MyHbaseSink1、继承RichSinkFunction<输入的数据类型>类2、实现open方法,创建连接对象3、实现invoke方法,批次写入数据到Hbase4、实现close方法,关闭连接 二、HBaseUtil工具类 一、MyHbaseSink 1、继承RichSinkFunction<输入的数据类型>类 public class MyHbaseS

flume source、sink、Channels测试
3.一个简单的例子 #设置配置文件 [root@cc-staging-loginmgr2 conf]# cat example.conf # example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1
Flume-0.9.4配置Hbase sink实践
在下载好的Flume-0.9.4里面有两个用于测试Hbase sink的插件类,但是默认情况下,这个插件类是没有被启用的,读完这篇文章你将会了解到如何配置Hbase sink。 1、修改$FLUME_HOME/conf/flume-site.xml的配置文件 ,在里面添加以下配置: <property> <name>flume.plugin.classes
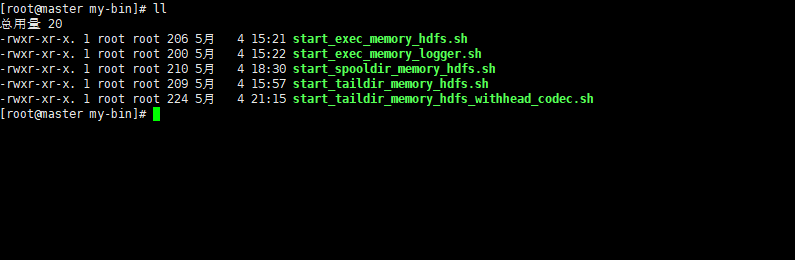
Flume_Flume常用配置5_header + filter taildir.source_memory.channel_hdfs.sink
以下配置基于版本 apache-flume-1.8.0-bin 我们假定已经对Flume有一定了解,并且对Flume 的各个组件有一定了解。 我们演示一个基本的 source 为 taildir源channel 为 memorysink 为 hdfs 类型的配置示例: 上一个配置中,我们对spooldir 源进行了简单的讲解,也提出了spooldir 中存在的问题,这一章我们对 1
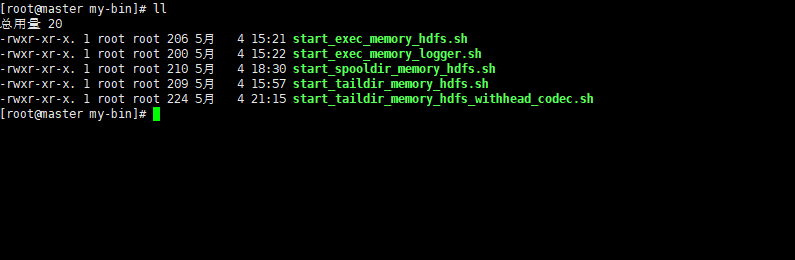
Flume_Flume常用配置4_taildir.source_memory.channel_hdfs.sink
以下配置基于版本 apache-flume-1.8.0-bin 我们假定已经对Flume有一定了解,并且对Flume 的各个组件有一定了解。 我们演示一个基本的 source 为 taildir源channel 为 memorysink 为 hdfs 类型的配置示例: 上一个配置中,我们对spooldir 源进行了简单的讲解,也提出了spooldir 中存在的问题,这一章我们对 1
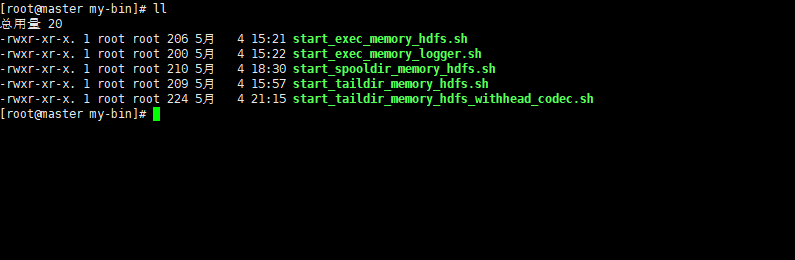
Flume_Flume常用配置3_spooldir.source_memory.channel_hdfs.sink
以下配置基于版本 apache-flume-1.8.0-bin 我们假定已经对Flume有一定了解,并且对Flume 的各个组件有一定了解。 我们演示一个基本的 source 为 spooldir源channel 为 memorysink 为 hdfs 类型的配置示例: 这里我们要对spooldir 源进行简单讲解: spooldir 可以避免 exec 中 利用 tail -f
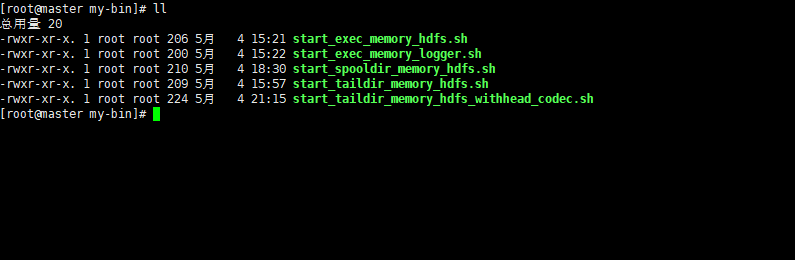
Flume_Flume常用配置2_exec.source_memory.channel_hdfs.sink
以下配置基于版本 apache-flume-1.8.0-bin 我们假定已经对Flume有一定了解,并且对Flume 的各个组件有一定了解。 我们演示一个基本的 source 为 exec源channel 为 memorysink 为 hdfs类型的配置示例: 请确保先安装了HDFS , 并对Hadoop 有一定了解,不懂得请自行百度,或者参看博主的Hadoop 相关搭建的文章。

Flume_Flume常用配置1_exec.source_memory.channel_logger.sink
以下配置基于版本 apache-flume-1.8.0-bin 我们假定已经对Flume有一定了解,并且对Flume 的各个组件有一定了解。 我们演示一个基本的 source 为 exec源channel 为 memorysink 为 logger 类型的配置示例:我们在解压好的目录下创建 2个子目录 my-conf, my-binmy-conf 存放了 对 agent (sour

《从0到1学习Flink》—— 如何自定义 Data Sink ?
前言 前篇文章 《从0到1学习Flink》—— Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢?这篇文章将写一个 demo 教大家将从 Kafka Source 的数据 Sink 到 MySQL 中去。 准备工作 我们先来看下 Flink 从 Kafka topic 中获取数据的 demo,首先你
《从0到1学习Flink》—— Data Sink 介绍
前言 再上一篇文章中 《从0到1学习Flink》—— Data Source 介绍 讲解了 Flink Data Source ,那么这里就来讲讲 Flink Data Sink 吧。 首先 Sink 的意思是: 大概可以猜到了吧!Data sink 有点把数据存储下来(落库)的意思。 如上图,Source 就是数据的来源,中间的 Compute 其实就是 Flink 干的事情,
Flink 常用的 Source 和 Sink Connectors 介绍
通过前面我们可以知道 Flink Job 的大致结构就是 Source ——> Transformation ——> Sink。 那么这个 Source 是什么意思呢?我们下面来看看。 Data Source 介绍 Data Source 是什么呢?就字面意思其实就可以知道:数据来源。 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流
如何自定义 Flink Connectors(Source 和 Sink)?
在前面文章 3.6 节中讲解了 Flink 中的 Data Source 和 Data Sink,然后介绍了 Flink 中自带的一些 Source 和 Sink 的 Connector,接着我们还有几篇实战会讲解了如何从 Kafka 处理数据写入到 Kafka、ElasticSearch 等,当然 Flink 还有一些其他的 Connector,我们这里就不一一介绍了,大家如果感兴趣的话可以去官
Flume之使用Loadbalancing Sink Processor实现sink负载均衡
前言 Load balancing Sink Processor,顾名思义,即能够对Sink组中的每个Sink实现负载均衡,默认采用的是轮询round_robin的方式,还可以使用随机方式random,或者用户自己实现AbstractSinkSelector抽象类定义自己的Sink Selector类,并提供FQCN(Full Qualified Class Name)全类名来进行配置,并且
Flume之使用Failover Sink Processor实现sink故障转移
前言 Failover Sink Processor 维护着Sink组中Sinks的优先级表,根据优先级尝试将Event传输给不同的Sink直到Event成功发送。当优先级高的Sink不可用时,会将Event传输给下一优先级Sink,以此来确保每个Event都能被投递。当Sink不可用时,Failover Sink Processor和Load balancing Sink Processo