本文主要是介绍模型推导:BG/NBD(预测用户生命周期(CLV)模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CLV(Customer Lifetime Value)指的是客户生命周期价值,用以衡量客户在一段时间内对企业有多大的价值。企业对每个用户的流失与否、在未来时间是否会再次购买,还会再购买多少次才会流失等问题感兴趣,本文中的BG/NBD模型就是用来解决这样一系列问题的。
本文的模型数学推理均参考自:
https://www.brucehardie.com/notes/039/bgnbd_derivation__2019-11-06.pdf
模型假设
BG/NBD模型包含以下的五个假设:
1、用户在活跃状态下,一个用户在时间段t内完成的交易数量服从交易率为 λ \lambda λ的泊松过程,这相当于假设了交易与交易之间的时间随交易率 λ \lambda λ呈指数分布
f ( t j ∣ t j − 1 ; λ ) = λ e − λ ( t j − t j − 1 ) f(t_j|t_{j-1};\lambda) = \lambda e^{-\lambda(t_j-t_{j-1})} f(tj∣tj−1;λ)=λe−λ(tj−tj−1) , t_j>t_{j-1}>=0
2、用户的交易率 λ \lambda λ服从如下的gamma分布
f ( λ ∣ r , α ) = α r λ r − 1 e − λ α Γ ( r ) , λ > 0 f(\lambda | r,\alpha)=\frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} , \lambda>0 f(λ∣r,α)=Γ(r)αrλr−1e−λα,λ>0
其中 Γ ( r ) = ∫ 0 + ∞ t r − 1 e − t d t \Gamma(r)=\int_0^{+\infty}t^{r-1}e^{-t}dt Γ(r)=∫0+∞tr−1e−tdt,是gamma函数
3、每个用户在第j次交易完之后流失的概率服从参数为p的二项分布,p为发生任何交易后用户流失的概率
P ( 在第 j 次交易后不再活跃 ) = p ( 1 − p ) j − 1 , j = 1 , 2 , 3 , . . . P(在第j次交易后不再活跃)=p(1-p)^{j-1},j=1,2,3,... P(在第j次交易后不再活跃)=p(1−p)j−1,j=1,2,3,...
4、每个用户的流失率p服从形状参数为a,b的beta分布
f ( p ∣ a , b ) = p a − 1 ( 1 − p ) b − 1 B ( a , b ) , 0 < = p < = 1 f(p|a,b)=\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)},0<=p<=1 f(p∣a,b)=B(a,b)pa−1(1−p)b−1,0<=p<=1
其中,B(a,b)是贝塔函数, B ( a , b ) = Γ ( a ) Γ ( b ) Γ ( a + b ) = ∫ 0 1 x a − 1 ( 1 − x ) b − 1 d x B(a,b)=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}=\int_0^1x^{a-1}\left(1-x\right)^{b-1}dx B(a,b)=Γ(a+b)Γ(a)Γ(b)=∫01xa−1(1−x)b−1dx
5、交易率 λ \lambda λ和流失率p互相独立
对于某个特定顾客的推导(已知 λ \lambda λ和p)
1、似然函数的推导
在 t 1 t_1 t1时刻发生第一次交易的概率服从标准指数分布,等于 λ e − λ t 1 \lambda e^{-\lambda t_1} λe−λt1
在 t 2 t_2 t2时刻发生第二次交易的概率为 t 1 t_1 t1时刻依然活跃的概率乘以标准指数分布,等于 λ ( 1 − p ) λ e − λ t 2 − t 1 \lambda (1-p)\lambda e^{-\lambda t_2-t_1} λ(1−p)λe−λt2−t1
以此类推,
在 t x t_x tx时刻发生第x次交易的概率为 t x t_x tx时刻依然活跃的概率乘以标准指数分布,等于 λ ( 1 − p ) λ e − λ t x − t x − 1 \lambda (1-p)\lambda e^{-\lambda t_x-t_{x-1}} λ(1−p)λe−λtx−tx−1
而在 ( t x , T ] (t_x,T] (tx,T]时间段内,没有任何交易的概率,则是客户已经不再活跃额度概率加上他活跃但是不进行任何购买的概率,也就是 p + ( 1 − p ) e − λ T − t x p+(1-p)e^{-\lambda T-t_x} p+(1−p)e−λT−tx
注意后面那一项是因为泊松过程发生k次事件的概率
P ( N ( T ) − N ( t x ) = k ) = e − λ ( T − t x ) ( λ ( T − t x ) ) k k ! P(N(T)-N(t_x)=k)=\frac{e^{-\lambda (T-t_x)}(\lambda (T-t_x))^k}{k!} P(N(T)−N(tx)=k)=k!e−λ(T−tx)(λ(T−tx))k 令k等于0得到,再乘以在t_x时刻依然活跃的概率(1-p)得到的。
因此,似然函数可以写作
L ( λ , p ∣ t 1 , t 2 , . . . , t x , T ) = ( 1 − p ) x − 1 λ x e − λ t x ∗ ( p + ( 1 − p ) e − λ T − t x ) = p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x λ x e − λ L(\lambda ,p|t_1,t_2,...,t_x,T)= (1-p)^{x-1}\lambda^x e^{-\lambda t_x} * (p+(1-p)e^{-\lambda T-t_x}) = p(1-p)^{x-1}\lambda^x e^{-\lambda t_x}+(1-p)^{x}\lambda^x e^{-\lambda} L(λ,p∣t1,t2,...,tx,T)=(1−p)x−1λxe−λtx∗(p+(1−p)e−λT−tx)=p(1−p)x−1λxe−λtx+(1−p)xλxe−λ
此时我们发现每一次交易发生的时间t是不需要的,因此我们只需要X=x(交易次数)、 t x t_x tx(最后一次交易时间)与T就可以了。
还有一种极端情况,就是在(0,T]之间内没有任何的交易,我们假设这用户在一开始就是活跃的,那么现在(T时刻)依然活跃的概率就是: L ( λ ∣ X = 0 , T ) = e − λ T L(\lambda | X=0,T)=e^{-\lambda T} L(λ∣X=0,T)=e−λT(这个式子依然可以根据泊松过程发生0次事件的概率获得)
最终得到个人水平下在T时交易次数为x的似然函数
L ( λ , p ∣ X = x , T ) = δ x > 0 p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x λ x e − λ L(\lambda,p | X=x,T)= \delta_{x>0} p(1-p)^{x-1}\lambda^x e^{-\lambda t_x}+(1-p)^{x}\lambda^x e^{-\lambda} L(λ,p∣X=x,T)=δx>0p(1−p)x−1λxe−λtx+(1−p)xλxe−λ
其中 δ x > 0 \delta_{x>0} δx>0为示性函数,当x>0是为1,否则为0。
2、 P ( X ( t ) = x ) P(X(t)=x) P(X(t)=x)的推导
此处的 X ( t ) X(t) X(t)代表第t期发生交易的次数
我们将有关交易时间的变量转化为有关交易次数的变量:
X ( t ) > = x ⇔ T x < = t X(t)>=x \Leftrightarrow T_x<=t X(t)>=x⇔Tx<=t
其中 T x T_x Tx表示第x次交易的时间,于是我们有:
P ( X ( t ) = x ) = P ( X ( t ) > = x ) − P ( X ( t ) > = x + 1 ) = P ( T x < = t ) − P ( T x + 1 < = t ) P(X(t)=x)=P(X(t)>=x)-P(X(t)>=x+1)=P(T_x<=t)-P(T_{x+1}<=t) P(X(t)=x)=P(X(t)>=x)−P(X(t)>=x+1)=P(Tx<=t)−P(Tx+1<=t)
而根据我们对用户失活的假设,这个式子也可以写成
P ( X ( t ) = t ) = P ( 第 x 次交易后依然活跃 ) P ( T x < = t 且 T x + 1 > t ) + δ x > 0 P ( 第 x 次交易后不再活跃 ) P ( T x < = t ) P(X(t)=t)=P(第x次交易后依然活跃)P(T_x<=t 且 T_{x+1}>t)+\delta_{x>0} P(第x次交易后不再活跃)P(T_x<=t) P(X(t)=t)=P(第x次交易后依然活跃)P(Tx<=t且Tx+1>t)+δx>0P(第x次交易后不再活跃)P(Tx<=t)
从而这个式子可以写成 P ( X ( t ) = x ∣ λ , p ) = ( 1 − p ) x e − λ t ( λ t ) x x ! + δ x > 0 p ( 1 − p ) x − 1 [ 1 − e − λ t Σ j = 0 x − 1 ( λ t ) j j ! ] P(X(t)=x|\lambda,p)=(1-p)^x\frac{e^{-\lambda t}(\lambda t)^x}{x!} +\delta_{x>0} p(1-p)^{x-1}[1-e^{-\lambda t}\Sigma_{j=0}^{x-1}\frac{(\lambda t)^j}{j!} ] P(X(t)=x∣λ,p)=(1−p)xx!e−λt(λt)x+δx>0p(1−p)x−1[1−e−λtΣj=0x−1j!(λt)j]
在原链接中,还提供了一个证明其为概率质量函数(PMF)的过程:
式子的前一项从0到无穷的累加可以写为
e − λ p t Σ x = 0 ∞ ( λ ( 1 − p ) t ) x e − λ ( 1 − p ) t x ! e^{-\lambda pt}\Sigma_{x=0}^\infty \frac{(\lambda(1-p)t)^x e^{-\lambda(1-p)t}}{x!} e−λptΣx=0∞x!(λ(1−p)t)xe−λ(1−p)t
相当于拿出一份 e − λ p t e^{-\lambda pt} e−λpt作为常数系数,而求和项就恰好是一个均值为 λ ( 1 − p ) t \lambda(1-p)t λ(1−p)t的泊松分布的概率质量函数,求和为1,故而整个式子的前一项等于 e − λ p t e^{-\lambda pt} e−λpt
而后一项的中括号里其实是Erlang分布的累计分布函数,故而后一项的累计求和可以写为
Σ x = 1 ∞ p ( 1 − p ) x − 1 ∫ 0 t λ x u x − 1 e ( − λ u ) ( x − 1 ) ! d u \Sigma_{x=1}^\infty p(1-p)^{x-1}\int_{0}^{t}\frac{\lambda^x u^{x-1}e^(-\lambda u)}{(x-1)!}du Σx=1∞p(1−p)x−1∫0t(x−1)!λxux−1e(−λu)du
= ∫ 0 t λ p e − λ p u Σ x = 1 ∞ [ λ ( 1 − p ) u ] e − λ ( 1 − p ) u ( x − 1 ) ! d u =\int_{0}^{t}\lambda pe^{-\lambda pu}\Sigma_{x=1}^\infty \frac{[\lambda(1-p)u]e^{-\lambda(1-p)u}}{(x-1)!}du =∫0tλpe−λpuΣx=1∞(x−1)![λ(1−p)u]e−λ(1−p)udu
求和项中的式子可以将x-1看做是随机变量,那么求和项就正好是一个均值为 λ ( 1 − p ) u \lambda(1-p)u λ(1−p)u的泊松分布的概率质量函数求和,为1,于是本式可以写为 ∫ 0 t λ p e − λ p u d u = 1 − e − λ p t \int_{0}^{t}\lambda pe^{-\lambda pu}du=1-e^{-\lambda pt} ∫0tλpe−λpudu=1−e−λpt
综上,我们可以看出 Σ x = 0 ∞ P ( X ( t ) = x ∣ λ , p ) = 1 \Sigma_{x=0}^\infty P(X(t)=x|\lambda,p)=1 Σx=0∞P(X(t)=x∣λ,p)=1,它的确是一个概率质量函数
3、P(在t时刻活跃)的推导
对于客户在t时刻还活跃的情况,有如下这么几种可能:
客户在(0,t]时刻内没有任何购买
客户在(0,t]时刻只购买了1次,而且在第1次购买后并没有“失活”
客户在(0,t]时刻只购买了2次,而且在第2次购买后并没有“失活”
…
从而我们能够获得如下的式子:
P ( 在第 t 时刻活跃 ∣ λ , p ) = Σ j = 0 ∞ ( 1 − p ) j ( λ t ) j e − λ t j ! P(在第t时刻活跃|\lambda,p)=\Sigma_{j=0}^{\infty}(1-p)^j\frac{(\lambda t)^je^{-\lambda t}}{j!} P(在第t时刻活跃∣λ,p)=Σj=0∞(1−p)jj!(λt)je−λt
= e − λ p t Σ j = 0 ∞ ( λ ( 1 − p ) t ) j e − λ ( 1 − p ) t j ! =e^{-\lambda pt}\Sigma_{j=0}^{\infty}\frac{(\lambda(1-p)t)^je^{-\lambda(1-p)t}}{j!} =e−λptΣj=0∞j!(λ(1−p)t)je−λ(1−p)t
上式求和部分正好是一个均值为 λ ( 1 − p ) t \lambda(1-p)t λ(1−p)t的破松分布的概率质量函数求和,为1。
所以 P ( 在第 t 时刻活跃 ∣ λ , p ) = e − λ p t P(在第t时刻活跃|\lambda,p)=e^{-\lambda pt} P(在第t时刻活跃∣λ,p)=e−λpt
我们假设用户在 τ \tau τ时刻不再活跃,那么
P ( τ > t ∣ λ , p ) = e − λ p t P(\tau > t| \lambda,p)=e^{-\lambda pt} P(τ>t∣λ,p)=e−λpt
根据这个定义,能够获得其累积分布函数,求导得到概率密度函数:
g ( τ ∣ λ , p ) = λ p e − λ p τ g(\tau|\lambda,p)=\lambda pe^{-\lambda p\tau} g(τ∣λ,p)=λpe−λpτ
4、E[X(t)]的推导
和上面一样,假设用户在 τ \tau τ时刻不再活跃,那么当 τ > t \tau>t τ>t时,E[X(t)]就是单纯的泊松分布期望: λ t \lambda t λt
而当 τ < = t \tau<=t τ<=t时,在用户活跃的时间段内交易量的期望数为 λ τ \lambda \tau λτ
于是我们有:
E ( X ( t ) ∣ λ , p ) = ( λ t ) P ( τ > t ) + ∫ 0 t λ τ g ( τ ∣ λ , p ) d τ E(X(t)|\lambda,p)=(\lambda t)P(\tau>t)+\int_{0}^{t}\lambda \tau g(\tau|\lambda,p)d\tau E(X(t)∣λ,p)=(λt)P(τ>t)+∫0tλτg(τ∣λ,p)dτ
= λ t e − λ p t + λ 2 p ∫ 0 t τ e − λ p τ d τ =\lambda te^{-\lambda pt}+\lambda^2 p\int_{0}^{t}\tau e^{-\lambda p\tau}d\tau =λte−λpt+λ2p∫0tτe−λpτdτ
= 1 p − 1 p e − λ p t =\frac{1}{p}-\frac{1}{p}e^{-\lambda pt} =p1−p1e−λpt
对任意用户的推导
上面的所有式子都是以交易率 λ \lambda λ和用户失活率p作为条件的,但是在实际场景下这2个都是无法被观测到的。为了对任意的单个客户都能得到表达式,我们需要取 λ \lambda λ和p分布的期望。
1、似然函数推导
对于任意选择的一个客户而言,
L ( r , α , a , b ∣ X = x , t x , T ) = ∫ 0 1 ∫ 0 ∞ L ( λ , p ∣ X = x , T ) f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p L(r,\alpha,a,b|X=x,t_x,T)=\int_0^1\int_0^\infty L(\lambda,p | X=x,T) f(\lambda | r,\alpha) f(p|a,b)d\lambda dp L(r,α,a,b∣X=x,tx,T)=∫01∫0∞L(λ,p∣X=x,T)f(λ∣r,α)f(p∣a,b)dλdp
我们根据基础假设和单个客户的似然函数:
f ( λ ∣ r , α ) = α r λ r − 1 e − λ α Γ ( r ) , λ > 0 f(\lambda | r,\alpha)=\frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} , \lambda>0 f(λ∣r,α)=Γ(r)αrλr−1e−λα,λ>0
f ( p ∣ a , b ) = p a − 1 ( 1 − p ) b − 1 B ( a , b ) , 0 < = p < = 1 f(p|a,b)=\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)},0<=p<=1 f(p∣a,b)=B(a,b)pa−1(1−p)b−1,0<=p<=1
L ( λ , p ∣ X = x , T ) = δ x > 0 p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x λ x e − λ L(\lambda,p | X=x,T)= \delta_{x>0} p(1-p)^{x-1}\lambda^x e^{-\lambda t_x}+(1-p)^{x}\lambda^x e^{-\lambda} L(λ,p∣X=x,T)=δx>0p(1−p)x−1λxe−λtx+(1−p)xλxe−λ
原式= ∫ 0 1 ∫ 0 ∞ ( δ x > 0 p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x λ x e − λ ) α r λ r − 1 e − λ α Γ ( r ) p a − 1 ( 1 − p ) b − 1 B ( a , b ) d λ d p \int_0^1\int_0^\infty (\delta_{x>0} p(1-p)^{x-1}\lambda^x e^{-\lambda t_x}+(1-p)^{x}\lambda^x e^{-\lambda}) \frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} \frac{p^{a-1}(1-p)^{b-1}}{B(a,b)} d\lambda dp ∫01∫0∞(δx>0p(1−p)x−1λxe−λtx+(1−p)xλxe−λ)Γ(r)αrλr−1e−λαB(a,b)pa−1(1−p)b−1dλdp
注意到,
∫ 0 1 p j ( 1 − p ) k p a − 1 ( 1 − p ) b − 1 B ( a , b ) d p = B ( a + j , b + k ) B ( a , b ) \int_0^1 p^j(1-p)^k\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)}dp=\frac{B(a+j,b+k)}{B(a,b)} ∫01pj(1−p)kB(a,b)pa−1(1−p)b−1dp=B(a,b)B(a+j,b+k)
∫ 0 ∞ λ j e − λ t α r λ r − 1 e − λ α Γ ( r ) d λ = Γ ( r + j ) α r Γ ( r ) ( α + t ) r + j \int_0^\infty \lambda^j e^{-\lambda t}\frac{\alpha^r\lambda^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} d\lambda=\frac{\Gamma(r+j)\alpha^r}{\Gamma(r)(\alpha+t)^{r+j}} ∫0∞λje−λtΓ(r)αrλr−1e−λαdλ=Γ(r)(α+t)r+jΓ(r+j)αr
这2个式子在下面会经常用到,下简称“化简式”
最终能够得到
原式= B ( a , b + x ) B ( a , b ) Γ ( r + x ) α r Γ ( r ) ( α + T ) r + x + δ x > 0 B ( a + 1 , b + x − 1 ) B ( a , b ) Γ ( r + x ) α r Γ ( r ) ( α + t x ) r + x \frac{B(a,b+x)}{B(a,b)}\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+T)^{r+x}} + \delta_{x>0}\frac{B(a+1,b+x-1)}{B(a,b)}\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+t_x)^{r+x}} B(a,b)B(a,b+x)Γ(r)(α+T)r+xΓ(r+x)αr+δx>0B(a,b)B(a+1,b+x−1)Γ(r)(α+tx)r+xΓ(r+x)αr
2、P(X(t)=x)的推导
对于任意选择的一个客户而言
P ( X ( t ) = x ∣ r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ P ( X ( t ) = x ∣ λ , p ) f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p P(X(t)=x|r,\alpha,a,b)=\int_0^1\int_0^\infty P(X(t)=x|\lambda,p) f(\lambda | r,\alpha) f(p|a,b)d\lambda dp P(X(t)=x∣r,α,a,b)=∫01∫0∞P(X(t)=x∣λ,p)f(λ∣r,α)f(p∣a,b)dλdp
其中,
P ( X ( t ) = x ∣ λ , p ) = ( 1 − p ) x e − λ t ( λ t ) x x ! + δ x > 0 p ( 1 − p ) x − 1 [ 1 − e − λ t Σ j = 0 x − 1 ( λ t ) j j ! ] P(X(t)=x|\lambda,p)=(1-p)^x\frac{e^{-\lambda t}(\lambda t)^x}{x!} +\delta_{x>0} p(1-p)^{x-1}[1-e^{-\lambda t}\Sigma_{j=0}^{x-1}\frac{(\lambda t)^j}{j!} ] P(X(t)=x∣λ,p)=(1−p)xx!e−λt(λt)x+δx>0p(1−p)x−1[1−e−λtΣj=0x−1j!(λt)j]
根据基础假设与化简式,可以得到
P ( X ( t ) = x ∣ r , α , a , b ) = B ( a , b + x ) B ( a , b ) Γ ( r + x ) Γ ( r ) x ! ( α α + t ) r ( t α + t ) x + δ x > 0 B ( a + 1 , b + x − 1 ) B ( a , b ) [ 1 − ( α α + t ) r { Σ j = 0 x − 1 Γ ( r + j ) Γ ( r ) j ! } ( t α + t ) j ] P(X(t)=x|r,\alpha,a,b)=\frac{B(a,b+x)}{B(a,b)}\frac{\Gamma(r+x)}{\Gamma(r)x!}(\frac{\alpha}{\alpha+t})^r(\frac{t}{\alpha+t})^x+\delta_{x>0}\frac{B(a+1,b+x-1)}{B(a,b)}[1-(\frac{\alpha}{\alpha+t})^r\left\{\Sigma_{j=0}^{x-1}\frac{\Gamma(r+j)}{\Gamma(r)j!}\right\}(\frac{t}{\alpha+t})^j] P(X(t)=x∣r,α,a,b)=B(a,b)B(a,b+x)Γ(r)x!Γ(r+x)(α+tα)r(α+tt)x+δx>0B(a,b)B(a+1,b+x−1)[1−(α+tα)r{Σj=0x−1Γ(r)j!Γ(r+j)}(α+tt)j]
3、P(在t时刻依然存活)的推导
对于任意选择的一个客户而言
P ( 在 t 时刻依然存活 ∣ r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ P ( 在第 t 时刻活跃 ∣ λ , p ) f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p P(在t时刻依然存活|r,\alpha,a,b)=\int_0^1\int_0^\infty P(在第t时刻活跃|\lambda,p) f(\lambda | r,\alpha) f(p|a,b) d\lambda dp P(在t时刻依然存活∣r,α,a,b)=∫01∫0∞P(在第t时刻活跃∣λ,p)f(λ∣r,α)f(p∣a,b)dλdp
其中, P ( 在第 t 时刻活跃 ∣ λ , p ) = e − λ p t P(在第t时刻活跃|\lambda,p)=e^{-\lambda pt} P(在第t时刻活跃∣λ,p)=e−λpt;根据我们的假设,可得:
P ( 在 t 时刻依然存活 ∣ r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ e − λ p t α r λ r − 1 e − λ α Γ ( r ) p a − 1 ( 1 − p ) b − 1 B ( a , b ) d λ d p P(在t时刻依然存活|r,\alpha,a,b)=\int_0^1\int_0^\infty e^{-\lambda pt} \frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} \frac{p^{a-1}(1-p)^{b-1}}{B(a,b)} d\lambda dp P(在t时刻依然存活∣r,α,a,b)=∫01∫0∞e−λptΓ(r)αrλr−1e−λαB(a,b)pa−1(1−p)b−1dλdp
= α r B ( a , b ) ∫ 0 1 ∫ 0 ∞ λ r − 1 e − λ ( α + p t ) d λ Γ ( r ) p a − 1 ( 1 − p ) b − 1 d p =\frac{\alpha^r}{B(a,b)}\int_0^1 \frac{\int_0^\infty\lambda ^{r-1}e^{-\lambda(\alpha+pt)}d\lambda}{\Gamma(r)} p^{a-1}(1-p)^{b-1} dp =B(a,b)αr∫01Γ(r)∫0∞λr−1e−λ(α+pt)dλpa−1(1−p)b−1dp
其中, ∫ 0 ∞ λ r − 1 e − λ ( α + p t ) d λ = 1 ( α + p t ) r ∫ 0 ∞ ( ( α + p t ) λ ) r − 1 e − λ ( α + p t ) d ( ( α + p t ) λ ) = ( α + p t ) − r Γ ( r ) \int_0^\infty\lambda ^{r-1}e^{-\lambda(\alpha+pt)}d\lambda=\frac{1}{(\alpha+pt)^r}\int_0^\infty ((\alpha+pt)\lambda) ^{r-1}e^{-\lambda(\alpha+pt)}d((\alpha+pt)\lambda)=(\alpha+pt)^{-r}\Gamma(r) ∫0∞λr−1e−λ(α+pt)dλ=(α+pt)r1∫0∞((α+pt)λ)r−1e−λ(α+pt)d((α+pt)λ)=(α+pt)−rΓ(r)
所以原式 = α r B ( a , b ) ∫ 0 1 p a − 1 ( 1 − p ) b − 1 ( α + p t ) − r d p =\frac{\alpha^r}{B(a,b)}\int_0^1p^{a-1}(1-p)^{b-1}(\alpha+pt)^{-r}dp =B(a,b)αr∫01pa−1(1−p)b−1(α+pt)−rdp
积分换元:q=1-p,则原式 = α r B ( a , b ) ∫ 0 1 q b − 1 ( 1 − q ) a − 1 ( α + t − q t ) − r d q =\frac{\alpha^r}{B(a,b)}\int_0^1q^{b-1}(1-q)^{a-1}(\alpha+t-qt)^{-r}dq =B(a,b)αr∫01qb−1(1−q)a−1(α+t−qt)−rdq
= ( α α + t ) r 1 B ( a , b ) ∫ 0 1 q b − 1 ( 1 − q ) a − 1 ( 1 − t α + t q ) − r d q =(\frac{\alpha}{\alpha+t})^r\frac{1}{B(a,b)}\int_0^1q^{b-1}(1-q)^{a-1}(1-\frac{t}{\alpha+t}q)^{-r}dq =(α+tα)rB(a,b)1∫01qb−1(1−q)a−1(1−α+ttq)−rdq
而根据超几何函数的积分形式(可以看:https://zh.wikipedia.org/wiki/%E8%B6%85%E5%87%A0%E4%BD%95%E5%87%BD%E6%95%B0#%E7%A7%AF%E5%88%86%E8%A1%A8%E7%A4%BA )
2 F 1 ( a , b ; c ; z ) = 1 B ( b , c − b ) ∫ 0 1 t b − 1 ( 1 − t ) c − b − 1 ( 1 − z t ) − a d t , c > b _2F_1(a,b;c;z)=\frac{1}{B(b,c-b)}\int_0^1t^{b-1}(1-t)^{c-b-1}(1-zt)^{-a}dt ,\quad c>b 2F1(a,b;c;z)=B(b,c−b)1∫01tb−1(1−t)c−b−1(1−zt)−adt,c>b
原式 = P ( 在 t 时刻依然存活 ∣ r , α , a , b ) = ( α α + t ) r 2 F 1 ( r , b ; a + b ; t α + t ) =P(在t时刻依然存活 | r,\alpha,a,b)=\left(\frac{\alpha}{\alpha+t}\right)^r{}_2F_1\big(r,b;a+b;\frac{t}{\alpha+t}\big) =P(在t时刻依然存活∣r,α,a,b)=(α+tα)r2F1(r,b;a+b;α+tt)
4、E[X(t)]的推导
E ( X ( t ) ∣ λ , p ) = 1 p − 1 p e − λ p t E(X(t)|\lambda,p)=\frac{1}{p}-\frac{1}{p}e^{-\lambda pt} E(X(t)∣λ,p)=p1−p1e−λpt
首先让我们求出 E ( X ( t ) ∣ r , α , p ) E(X(t)|r,\alpha,p) E(X(t)∣r,α,p)。由于 f ( λ ∣ r , α ) = α r λ r − 1 e − λ α Γ ( r ) , λ > 0 f(\lambda | r,\alpha)=\frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} , \lambda>0 f(λ∣r,α)=Γ(r)αrλr−1e−λα,λ>0,我们可以求出:
E ( X ( t ) ∣ r , α , p ) = 1 p − ∫ 0 ∞ 1 p e − λ p t α r λ r − 1 e − λ α Γ ( r ) d λ E(X(t)|r,\alpha,p)=\frac{1}{p}-\int_0^\infty\frac{1}{p}e^{-\lambda pt}\frac{\alpha^r\lambda ^{r-1}e^{-\lambda\alpha}}{\Gamma(r)} d\lambda E(X(t)∣r,α,p)=p1−∫0∞p1e−λptΓ(r)αrλr−1e−λαdλ
右侧的积分结果在我们求 P ( 在 t 时刻依然存活 ∣ r , α , a , b ) P(在t时刻依然存活|r,\alpha,a,b) P(在t时刻依然存活∣r,α,a,b)时已经求过了,所以 E ( X ( t ) ∣ r , α , p ) = 1 p − α r p ( α + p t ) r E(X(t)|r,\alpha,p)=\frac{1}{p}-\frac{\alpha^r}{p(\alpha+pt)^r} E(X(t)∣r,α,p)=p1−p(α+pt)rαr
接下来我们将p的分布带入,求 E ( X ( t ) ∣ r , α , a , b ) E(X(t)|r,\alpha,a,b) E(X(t)∣r,α,a,b)。其中 f ( p ∣ a , b ) = p a − 1 ( 1 − p ) b − 1 B ( a , b ) , 0 < = p < = 1 f(p|a,b)=\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)},0<=p<=1 f(p∣a,b)=B(a,b)pa−1(1−p)b−1,0<=p<=1
对于被减数而言, ∫ 0 1 1 p p a − 1 ( 1 − p ) b − 1 B ( a , b ) d p = ∫ 0 1 p a − 1 ( 1 − p ) b − 1 d p B ( a , b ) = B ( a − 1 ) ( b ) B ( a , b ) = a + b − 1 a − 1 \int_0^1\frac1p\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)}dp = \frac{\int_0^1p^{a-1}(1-p)^{b-1}dp}{B(a,b)}=\frac{B(a-1)(b)}{B(a,b)}=\frac{a+b-1}{a-1} ∫01p1B(a,b)pa−1(1−p)b−1dp=B(a,b)∫01pa−1(1−p)b−1dp=B(a,b)B(a−1)(b)=a−1a+b−1(贝塔函数递推公式)
对于减数而言, ∫ 0 1 α r p ( α + p t ) r p a − 1 ( 1 − p ) b − 1 B ( a , b ) d p = α r B ( a , b ) ∫ 0 1 p a − 2 ( 1 − p ) b − 1 ( α + p t ) − r d p \int_{0}^{1}\frac{\alpha^{r}}{p(\alpha+pt)^{r}}\frac{p^{a-1}(1-p)^{b-1}}{B(a,b)}dp=\frac{\alpha^r}{B(a,b)}\int_0^1p^{a-2}(1-p)^{b-1}(\alpha+pt)^{-r}dp ∫01p(α+pt)rαrB(a,b)pa−1(1−p)b−1dp=B(a,b)αr∫01pa−2(1−p)b−1(α+pt)−rdp
和上面一样,使用积分换元q=1-p,于是
减数= = α r B ( a , b ) ∫ 0 1 q b − 1 ( 1 − q ) a − 2 ( α + t − q t ) − r d q \begin{aligned}&=\frac{\alpha^r}{B(a,b)}\int_0^1q^{b-1}(1-q)^{a-2}(\alpha+t-qt)^{-r}dq\end{aligned} =B(a,b)αr∫01qb−1(1−q)a−2(α+t−qt)−rdq
= ( α α + t ) r 1 B ( a , b ) ∫ 0 1 q b − 1 ( 1 − q ) a − 2 ( 1 − t α + t q ) − r d q =\left(\frac{\alpha}{\alpha+t}\right)^r\frac{1}{B(a,b)}\int_0^1q^{b-1}(1-q)^{a-2}\big(1-\frac{t}{\alpha+t}q\big)^{-r}dq =(α+tα)rB(a,b)1∫01qb−1(1−q)a−2(1−α+ttq)−rdq
和上面一样,将其写作超几何函数的积分形式,得
( α α + t ) r B ( a − 1 , b ) B ( a , b ) 2 F 1 ( r , b ; a + b − 1 ; t α + t ) \left(\frac{\alpha}{\alpha+t}\right)^r\frac{B(a-1,b)}{B(a,b)}_2F_1\big(r,b;a+b-1;\frac{t}{\alpha+t}\big) (α+tα)rB(a,b)B(a−1,b)2F1(r,b;a+b−1;α+tt)
综上,我们有
E ( X ( t ) ∣ r , α , a , b ) = a + b − 1 a − 1 [ 1 − ( α α + t ) r 2 F 1 ( r , b ; a + b − 1 ; t α + t ) ] E(X(t)|r,\alpha,a,b)=\frac{a+b-1}{a-1}\left[1-\left(\frac{\alpha}{\alpha+t}\right)^{r}{}_{2}F_{1}\left(r,b;a+b-1;\frac{t}{\alpha+t}\right)\right] E(X(t)∣r,α,a,b)=a−1a+b−1[1−(α+tα)r2F1(r,b;a+b−1;α+tt)]
参数求解
接下来我们来看一下如何求解模型中的四个参数( r , α , a , b r,\alpha,a,b r,α,a,b)
参考:https://brucehardie.com/notes/004/bgnbd_spreadsheet_note.pdf
根据贝塔函数的递推公式,我们有 B ( a + 1 , b + x ) = a a + b + x B ( a , b + x ) = b + x − 1 a + b + x B ( a + 1 , b + x − 1 ) B(a+1,b+x) = \frac{a}{a+b+x}B(a,b+x) = \frac{b+x-1}{a+b+x}B(a+1,b+x-1) B(a+1,b+x)=a+b+xaB(a,b+x)=a+b+xb+x−1B(a+1,b+x−1),
B ( a + 1 , b + x − 1 ) = a b + x − 1 B ( a , b + x ) B(a+1,b+x-1) = \frac{a}{b+x-1}B(a,b+x) B(a+1,b+x−1)=b+x−1aB(a,b+x)
根据公式 B ( a , b ) = Γ ( a ) Γ ( b ) Γ ( a + b ) B(a,b)=\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)} B(a,b)=Γ(a+b)Γ(a)Γ(b),可以得出 B ( a , b + x ) B ( a , b ) = Γ ( a + b ) Γ ( b + x ) Γ ( b ) Γ ( a + b + x ) \frac{B(a,b+x)}{B(a,b)} = \frac{\Gamma(a+b)\Gamma(b+x)}{\Gamma(b)\Gamma(a+b+x)} B(a,b)B(a,b+x)=Γ(b)Γ(a+b+x)Γ(a+b)Γ(b+x)
从而似然函数能够写成 L ( r , α , a , b ∣ X = x , t x , T ) = A 1 A 2 ( A 3 + δ x > 0 A 4 ) L(r,\alpha,a,b|X=x,t_x,T)=A_1A_2(A_3+\delta_{x>0}A_4) L(r,α,a,b∣X=x,tx,T)=A1A2(A3+δx>0A4)的形式
其中, A 1 = Γ ( r + x ) α r Γ ( r ) A_1=\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)} A1=Γ(r)Γ(r+x)αr
A 2 = Γ ( a + b ) Γ ( b + x ) Γ ( b ) Γ ( a + b + x ) A_2=\frac{\Gamma(a+b)\Gamma(b+x)}{\Gamma(b)\Gamma(a+b+x)} A2=Γ(b)Γ(a+b+x)Γ(a+b)Γ(b+x)
A 3 = ( 1 α + T ) r + x A_3=\left(\frac1{\alpha+T}\right)^{r+x} A3=(α+T1)r+x
A 4 = ( a b + x − 1 ) ( 1 α + t x ) r + x A_4=\Big(\frac a{b+x-1}\Big)\Big(\frac1{\alpha+t_x}\Big)^{r+x} A4=(b+x−1a)(α+tx1)r+x
为了求得似然函数的对数形式,我们有
l n ( A 1 ) = l n ( Γ ( r + x ) ) − l n ( Γ ( r ) ) + r l n ( α ) ln(A_1) = ln(\Gamma(r+x))-ln(\Gamma(r))+rln(\alpha) ln(A1)=ln(Γ(r+x))−ln(Γ(r))+rln(α)
l n ( A 2 ) = l n ( Γ ( a + b ) ) + l n ( Γ ( b + x ) ) − l n ( Γ ( b ) ) − l n ( Γ ( a + b + x ) ) ln(A_2) = ln(\Gamma(a+b))+ln(\Gamma(b+x))-ln(\Gamma(b))-ln(\Gamma(a+b+x)) ln(A2)=ln(Γ(a+b))+ln(Γ(b+x))−ln(Γ(b))−ln(Γ(a+b+x))
l n ( A 3 ) = − ( r + x ) l n ( α + T ) ln(A_3) = -(r+x)ln(\alpha+T) ln(A3)=−(r+x)ln(α+T)
l n ( A 4 ) = l n ( a ) − l n ( b + x − 1 ) − ( r + x ) l n ( α + t x ) ln(A_4) = ln(a)-ln(b+x-1)-(r+x)ln(\alpha+t_x) ln(A4)=ln(a)−ln(b+x−1)−(r+x)ln(α+tx)
最终我们有
l n [ L ( r , α , a , b ∣ X = x , t x , T ) ] = l n ( A 1 ) + l n ( A 2 ) + l n ( A 3 + δ x > 0 A 4 ) ln[L(r,\alpha,a,b|X=x,t_x,T)]=ln(A_1)+ln(A_2)+ln(A_3+\delta_{x>0}A_4) ln[L(r,α,a,b∣X=x,tx,T)]=ln(A1)+ln(A2)+ln(A3+δx>0A4)
在我给出的那个页面中,作者使用了Excel作为参数求解的工具:
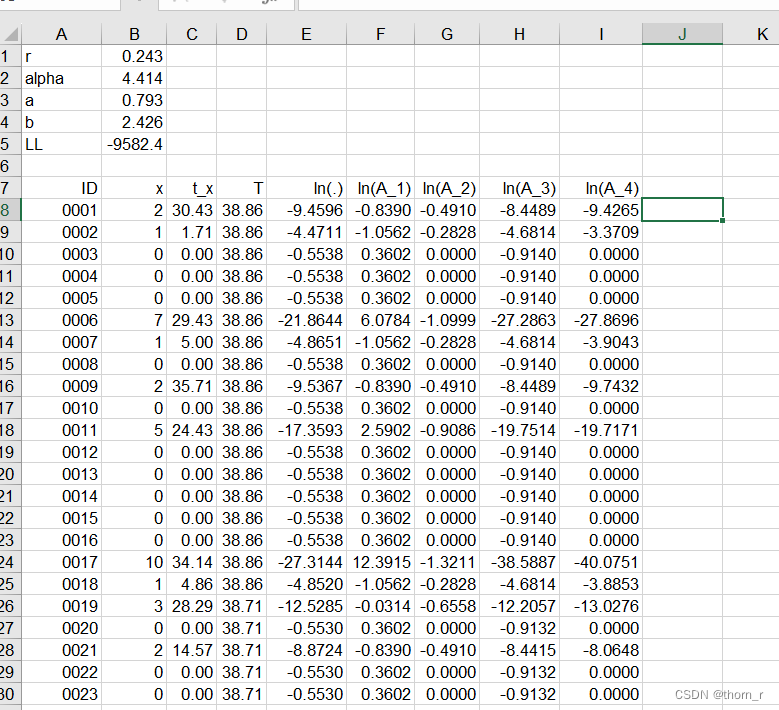
如图所示,B、C、D列3列是我们的原始数据。x代表从第0期到当前期数的总交易次数, t x t_x tx代表交易期数,注意 t x = 0 t_x=0 tx=0时,x也为0,T代表真实时间与设定的第0时刻相差多少。
将4个参数放到B1到B4,然后分别在F到I列求出 A 1 A_1 A1到 A 4 A_4 A4的对数值,然后在E列求出每行的积,最后在B5求出似然函数的求和。我们可以使用Excel进行规划参数求解。
在文件-选项中选择【加载项】,选中【规划求解加载项】,然后点积下面的【转到(G)…】
选中规划求解加载项,然后点击确定。
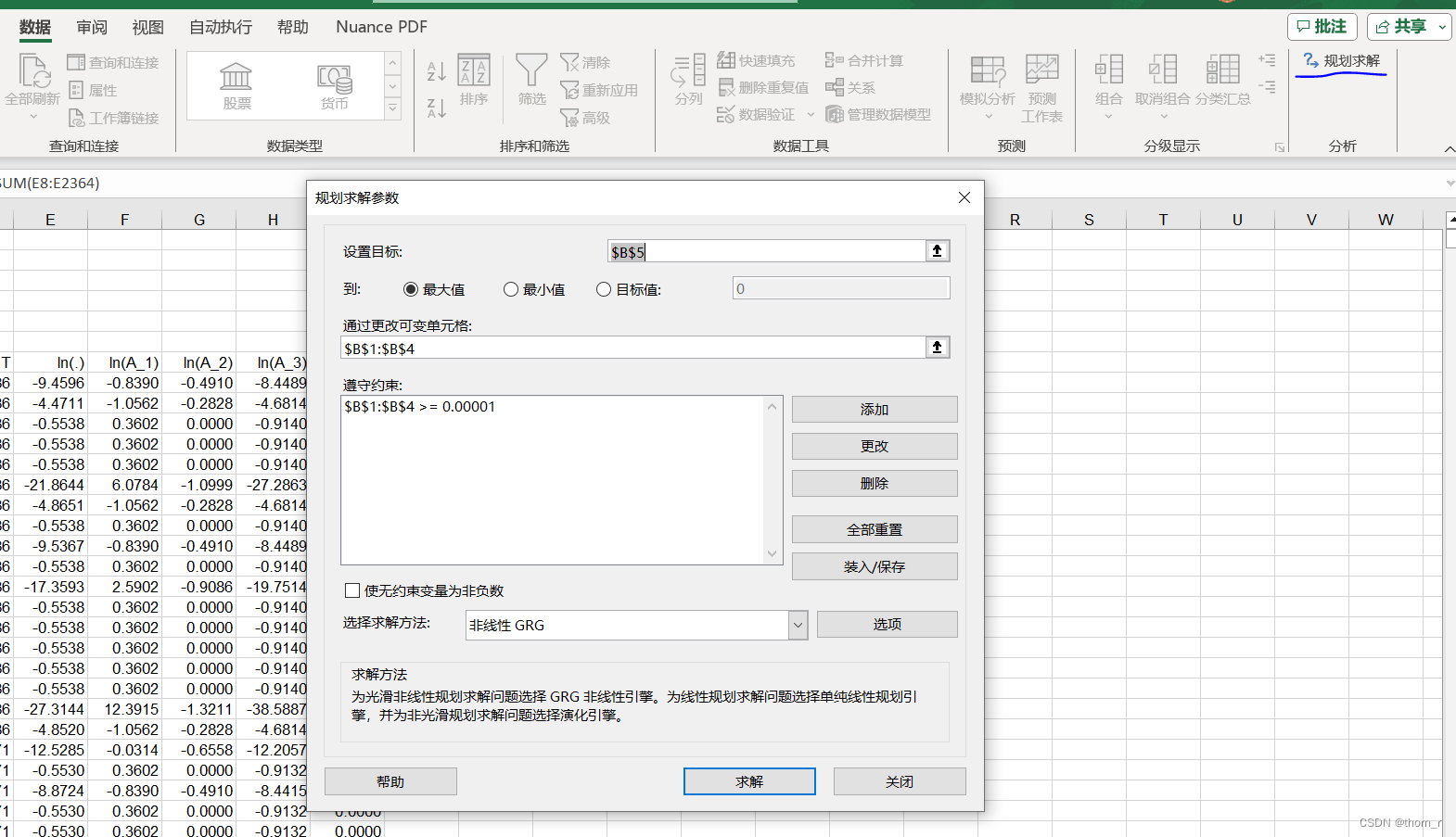
最后,在数据选项卡中点击右上角的规划求解按钮,注意此处的B5是似然函数的几个乘积,选择最大值。就可以使用Excel进行参数求解了。
下面我们来看一下python的lifetimes包时如何进行处理的。
这是lifetimes中BetaGeoFitter类的fit方法:
def fit(self, frequency, recency, T, weights=None, initial_params=None, verbose=False, tol=1e-7, index=None, **kwargs):frequency = np.asarray(frequency).astype(int)recency = np.asarray(recency)T = np.asarray(T)_check_inputs(frequency, recency, T)if weights is None:weights = np.ones_like(recency, dtype=int)else:weights = np.asarray(weights)self._scale = _scale_time(T)scaled_recency = recency * self._scalescaled_T = T * self._scalelog_params_, self._negative_log_likelihood_, self._hessian_ = self._fit((frequency, scaled_recency, scaled_T, weights, self.penalizer_coef),initial_params,4,verbose,tol,**kwargs)self.params_ = pd.Series(np.exp(log_params_), index=["r", "alpha", "a", "b"])self.params_["alpha"] /= self._scaleself.data = pd.DataFrame({"frequency": frequency, "recency": recency, "T": T, "weights": weights}, index=index)self.generate_new_data = lambda size=1: beta_geometric_nbd_model(T, *self._unload_params("r", "alpha", "a", "b"), size=size)self.predict = self.conditional_expected_number_of_purchases_up_to_timeself.variance_matrix_ = self._compute_variance_matrix()self.standard_errors_ = self._compute_standard_errors()self.confidence_intervals_ = self._compute_confidence_intervals()return self
在所有参数中,frequency要输入顾客购买的频数,即公式的 X ( t ) = x X(t)=x X(t)=x中的x
而recency要输入输入顾客最近一次购买的时间,即公式中的 t x t_x tx
最后的T即是客户的寿命(现在一直到客户第一次购买),即公式中的T
以上的三个值都可以通过lifetime中的summary_data_from_transaction_data或calibration_and_holdout_data(会留出一部分验证集)来实现。
剩下的几个参数中
weights参数可以将每个transaction加上权重(可以看做这个transaction是由几个customer购买),某个transaction的权重大于1时,表明它有多个customer,因此似然函数对数要乘以这个权重(不填默认全都是1)。
initial_params:要优化的4个参数的初始值,不填默认会给个0.1
verbose:是否要打印模型收敛的过程
tol:小于这个tolerance值之后函数终止计算
index:最终模型训练完成后会根据frequency,recency,T生成DataFrame,这个参数可以指定生成的DataFrame的索引。
在进行模型拟合之前,会根据客户寿命向量T先对T和recency进行一次缩放将其缩放到0~1之间:
def _scale_time(age
):"""Create a scalar such that the maximum age is 1."""return 1.0 / age.max()
之后使用的是_fit方法进行的拟合:
def _fit(self, minimizing_function_args, initial_params, params_size, disp, tol=1e-7, bounds=None, **kwargs):# set options for minimize, if specified in kwargs will be overwrittenminimize_options = {}minimize_options["disp"] = dispminimize_options.update(kwargs)current_init_params = 0.1 * np.ones(params_size) if initial_params is None else initial_paramsoutput = minimize(value_and_grad(self._negative_log_likelihood),jac=True,method=None,tol=tol,x0=current_init_params,args=minimizing_function_args,options=minimize_options,bounds=bounds,)if output.success:hessian_ = hessian(self._negative_log_likelihood)(output.x, *minimizing_function_args)return output.x, output.fun, hessian_print(output)raise ConvergenceError(dedent("""The model did not converge. Try adding a larger penalizer to see if that helps convergence."""))
此处没有任何的限制条件,直接使用了BFGS方法进行优化。BFGS算法我个人理解就是使用一个正定矩阵B_k来近似Heissen矩阵以此弥补牛顿法中需要求函数二阶导的缺陷。(优化算法笔者不熟,有误的话评论区还请多多指正)。
模型预测
1、在T时刻用户依然活跃的概率
也就是 P ( 在 T 时刻依然活跃 ∣ X = x , t x , T ) P(在T时刻依然活跃|X=x,t_x,T) P(在T时刻依然活跃∣X=x,tx,T)
针对于以此都没有购买的客户(x=0),我们假定 P ( 在T时刻依然活跃 T ∣ X = 0 , T , r , α , a , b ) = 1 P(\text{在T时刻依然活跃}T\mid X=0,T,r,\alpha,a,b)=1 P(在T时刻依然活跃T∣X=0,T,r,α,a,b)=1
而对于购买次数为x的客户,在T时刻活跃的概率为:
P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , λ , p ) = ( 1 − p ) e − λ ( T − t x ) p + ( 1 − p ) e − λ ( T − t x ) P(在T时刻依然活跃\mid X=x,t_x,T,\lambda,p)=\frac{(1-p)e^{-\lambda(T-t_x)}}{p+(1-p)e^{-\lambda(T-t_x)}} P(在T时刻依然活跃∣X=x,tx,T,λ,p)=p+(1−p)e−λ(T−tx)(1−p)e−λ(T−tx)
其中,p为用户失活的情形,而 ( 1 − p ) e − λ ( T − t x ) (1-p)e^{-\lambda(T-t_x)} (1−p)e−λ(T−tx)则代表了用户在x次购买之后,在最后一次交易直到T时间没有任何交易,但是依然活跃的概率。
分子分母同时乘以 ( 1 − p ) x − 1 λ x e − λ t x (1-p)^{x-1}\lambda^xe^{-\lambda t_x} (1−p)x−1λxe−λtx,
其中分母为:
L ( λ , p ∣ X = x , t x , T ) = δ x > 0 p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x λ x e − λ L(\lambda,p | X=x,t_x,T)= \delta_{x>0} p(1-p)^{x-1}\lambda^x e^{-\lambda t_x}+(1-p)^{x}\lambda^x e^{-\lambda} L(λ,p∣X=x,tx,T)=δx>0p(1−p)x−1λxe−λtx+(1−p)xλxe−λ(当x=0时,原式=1,和此处的 δ x > 0 \delta_{x>0} δx>0没有冲突)
而分子= ( 1 − p ) x λ x e − λ T (1-p)^{x}\lambda^xe^{-\lambda T} (1−p)xλxe−λT
由于式子中含有不可测的 p p p和 λ \lambda λ,我们还需要进行计算。和前面的对任意的单个客户求表达式的思路一样,我们求:
P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , λ , p ) f ( λ , p ∣ r , α , a , b , X = x , t x , T ) d λ d p P(在T时刻依然活跃\mid X=x,t_x,T,r,\alpha,a,b)=\int_0^1\int_0^\infty P(在T时刻依然活跃\mid X=x,t_x,T,\lambda,p) f(\lambda,p|r,\alpha,a,b,X=x,t_x,T)d\lambda dp P(在T时刻依然活跃∣X=x,tx,T,r,α,a,b)=∫01∫0∞P(在T时刻依然活跃∣X=x,tx,T,λ,p)f(λ,p∣r,α,a,b,X=x,tx,T)dλdp
而根据贝叶斯公式,我们有:
f ( λ , p ∣ r , α , a , b , X = x , t x , T ) = L ( λ , p ∣ X = x , t x , T ) f ( λ ∣ r , α ) f ( p ∣ a , b ) L ( r , α , a , b ∣ X = x , t x , T ) f(\lambda,p | r,\alpha,a,b,X=x,t_x,T)=\frac{L(\lambda,p | X=x,t_x,T)f(\lambda | r,\alpha)f(p | a,b)}{L(r,\alpha,a,b | X=x,t_x,T)} f(λ,p∣r,α,a,b,X=x,tx,T)=L(r,α,a,b∣X=x,tx,T)L(λ,p∣X=x,tx,T)f(λ∣r,α)f(p∣a,b)
我们将贝叶斯公式得出的式子和我们一开始求的 L ( λ , p ∣ X = x , t x , T ) L(\lambda,p | X=x,t_x,T) L(λ,p∣X=x,tx,T)带入到中间的 P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , r , α , a , b ) P(在T时刻依然活跃\mid X=x,t_x,T,r,\alpha,a,b) P(在T时刻依然活跃∣X=x,tx,T,r,α,a,b)中,可得
P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , r , α , a , b ) = 1 L ( r , α , a , b ∣ X = x , t x , T ) ∫ 0 1 ∫ 0 ∞ ( 1 − p ) x λ x e − λ T f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p P(在T时刻依然活跃\mid X=x,t_x,T,r,\alpha,a,b)=\frac{1}{L(r,\alpha,a,b | X=x,t_x,T)}\int_0^1\int_0^\infty (1-p)^x\lambda^xe^{-\lambda T}f(\lambda | r,\alpha)f(p | a,b)d\lambda dp P(在T时刻依然活跃∣X=x,tx,T,r,α,a,b)=L(r,α,a,b∣X=x,tx,T)1∫01∫0∞(1−p)xλxe−λTf(λ∣r,α)f(p∣a,b)dλdp
式中的积分部分可以写为 ∫ 0 1 ( 1 − p ) x f ( p ∣ a , b ) d p ∫ 0 ∞ λ x e − λ T f ( λ ∣ r , α ) d λ \int_0^1 (1-p)^xf(p | a,b) dp\int_0^\infty\lambda^xe^{-\lambda T}f(\lambda | r,\alpha)d\lambda ∫01(1−p)xf(p∣a,b)dp∫0∞λxe−λTf(λ∣r,α)dλ
这2个形式正好对应了我们在求单个客户表达式时使用的“化简式”,于是我们有:
∫ 0 1 ∫ 0 ∞ ( 1 − p ) x λ x e − λ T f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p = B ( a , b + x ) B ( a , b ) = Γ ( r + x ) α r Γ ( r ) ( α + T ) r + x \int_0^1\int_0^\infty (1-p)^x\lambda^xe^{-\lambda T}f(\lambda | r,\alpha)f(p | a,b)d\lambda dp=\frac{B(a,b+x)}{B(a,b)}=\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+T)^{r+x}} ∫01∫0∞(1−p)xλxe−λTf(λ∣r,α)f(p∣a,b)dλdp=B(a,b)B(a,b+x)=Γ(r)(α+T)r+xΓ(r+x)αr
最终再把 L ( r , α , a , b ∣ X = x , t x , T ) = B ( a , b + x ) B ( a , b ) Γ ( r + x ) α r Γ ( r ) ( α + T ) r + x + δ x > 0 B ( a + 1 , b + x − 1 ) B ( a , b ) Γ ( r + x ) α r Γ ( r ) ( α + t x ) r + x L(r,\alpha,a,b|X=x,t_x,T)=\frac{B(a,b+x)}{B(a,b)}\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+T)^{r+x}} + \delta_{x>0}\frac{B(a+1,b+x-1)}{B(a,b)}\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+t_x)^{r+x}} L(r,α,a,b∣X=x,tx,T)=B(a,b)B(a,b+x)Γ(r)(α+T)r+xΓ(r+x)αr+δx>0B(a,b)B(a+1,b+x−1)Γ(r)(α+tx)r+xΓ(r+x)αr带入,可以得:
P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , r , α , a , b ) = 1 1 + δ x > 0 a b + x − 1 ( α + T α + t x ) r + x P(在T时刻依然活跃\mid X=x,t_x,T,r,\alpha,a,b)=\frac{1}{1+\delta_{x>0}\frac{a}{b+x-1}\left(\frac{\alpha+T}{\alpha+t_{x}}\right)^{r+x}} P(在T时刻依然活跃∣X=x,tx,T,r,α,a,b)=1+δx>0b+x−1a(α+txα+T)r+x1
2、预测 E ( Y ( t ) ∣ X = x , t x , T ) E(Y(t)|X=x,t_x,T) E(Y(t)∣X=x,tx,T)
式中的Y(t)代表在时间段(T,T+t]的交易数
在最初,我们已经推导了 E ( Y ( t ) ∣ λ , p ) = 1 p − 1 p e − λ p t E(Y(t)|\lambda,p)=\frac{1}{p}-\frac{1}{p}e^{-\lambda pt} E(Y(t)∣λ,p)=p1−p1e−λpt
将这个式子乘以 P ( 在 T 时刻依然活跃 ∣ X = x , t x , T ) = ( 1 − p ) x λ x e − λ T L ( λ , p ∣ X = x , t x , T ) P(在T时刻依然活跃\mid X=x,t_x,T)=\frac{(1-p)^{x}\lambda^xe^{-\lambda T}}{L(\lambda,p | X=x,t_x,T)} P(在T时刻依然活跃∣X=x,tx,T)=L(λ,p∣X=x,tx,T)(1−p)xλxe−λT
则 E ( Y ( t ) ∣ X = x , t x , T , λ , p ) E(Y(t)|X=x,t_x,T,\lambda,p) E(Y(t)∣X=x,tx,T,λ,p)
= ( 1 − p ) x λ x e − λ T ( 1 p − 1 p e − λ p t ) L ( λ , p ∣ X = x , t x , T ) =\frac{(1-p)^{x}\lambda^{x}e^{-\lambda T}\left(\frac{1}{p}-\frac{1}{p}e^{-\lambda pt}\right)}{L(\lambda,p\mid X=x,t_{x},T)} =L(λ,p∣X=x,tx,T)(1−p)xλxe−λT(p1−p1e−λpt)
= p − 1 ( 1 − p ) x λ x e − λ T − p − 1 ( 1 − p ) x λ x e − λ ( T + p t ) L ( λ , p ∣ X = x , t x , T ) =\frac{p^{-1}(1-p)^{x}\lambda^{x}e^{-\lambda T}-p^{-1}(1-p)^{x}\lambda^{x}e^{-\lambda(T+pt)}}{L(\lambda,p | X=x,t_{x},T)} =L(λ,p∣X=x,tx,T)p−1(1−p)xλxe−λT−p−1(1−p)xλxe−λ(T+pt)
和上面一样,我们求 E ( Y ( t ) ∣ X = x , t x , T , r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ E ( Y ( t ) ∣ X = x , t x , T , λ , p ) f ( λ , p ∣ r , α , a , b , X = x , t x , T ) d λ d p E(Y(t)|X=x,t_x,T,r,\alpha,a,b)=\int_0^1\int_0^\infty E(Y(t)|X=x,t_x,T,\lambda,p) f(\lambda,p|r,\alpha,a,b,X=x,t_x,T)d\lambda dp E(Y(t)∣X=x,tx,T,r,α,a,b)=∫01∫0∞E(Y(t)∣X=x,tx,T,λ,p)f(λ,p∣r,α,a,b,X=x,tx,T)dλdp
= A − B L ( r , α , a , b ∣ X = x , t x , T ) =\frac{\mathrm{A}-\mathrm{B}}{L(r,\alpha,a,b\mid X=x,t_x,T)} =L(r,α,a,b∣X=x,tx,T)A−B
其中, A = ∫ 0 1 ∫ 0 ∞ p − 1 ( 1 − p ) x λ x e − λ T f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p A=\int_0^1\int_0^\infty p^{-1}(1-p)^x\lambda^xe^{-\lambda T}f(\lambda | r,\alpha)f(p | a,b)d\lambda dp A=∫01∫0∞p−1(1−p)xλxe−λTf(λ∣r,α)f(p∣a,b)dλdp
(根据“化简式”) = B ( a − 1 , b + x ) B ( a , b ) = Γ ( r + x ) α r Γ ( r ) ( α + T ) r + x =\frac{B(a-1,b+x)}{B(a,b)}=\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)(\alpha+T)^{r+x}} =B(a,b)B(a−1,b+x)=Γ(r)(α+T)r+xΓ(r+x)αr
而B = ∫ 0 1 ∫ 0 ∞ p − 1 ( 1 − p ) x λ x e − λ ( T + p t ) f ( λ ∣ r , α ) f ( p ∣ a , b ) d λ d p =\int_{0}^{1}\int_{0}^{\infty}p^{-1}(1-p)^{x}\lambda^{x}e^{-\lambda(T+pt)}f(\lambda | r,\alpha)f(p | a,b)d\lambda dp =∫01∫0∞p−1(1−p)xλxe−λ(T+pt)f(λ∣r,α)f(p∣a,b)dλdp
= ∫ 0 1 p a − 2 ( 1 − p ) b + x − 1 B ( a , b ) { ∫ 0 ∞ α r λ r + x − 1 e − λ ( α + T + p t ) Γ ( r ) d λ } d p =\int_0^1\frac{p^{a-2}(1-p)^{b+x-1}}{B(a,b)}\left\{\int_0^\infty\frac{\alpha^r\lambda^{r+x-1}e^{-\lambda(\alpha+T+pt)}}{\Gamma(r)}d\lambda\right\}dp =∫01B(a,b)pa−2(1−p)b+x−1{∫0∞Γ(r)αrλr+x−1e−λ(α+T+pt)dλ}dp
其中关于 λ \lambda λ的积分可以写作
∫ 0 ∞ α r λ r + x − 1 e − λ ( α + T + p t ) Γ ( r ) d λ = α r Γ ( r ) ∫ 0 ∞ λ r + x − 1 e − λ ( α + T + p t ) d λ = α r Γ ( r ) ( α + T + p t ) − ( r + x ) Γ ( r + x ) \int_0^\infty\frac{\alpha^r\lambda^{r+x-1}e^{-\lambda(\alpha+T+pt)}}{\Gamma(r)}d\lambda=\frac{\alpha^r}{\Gamma(r)}\int_0^\infty\ \lambda^{r+x-1}e^{-\lambda(\alpha+T+pt)}d\lambda=\frac{\alpha^r}{\Gamma(r)}(\alpha+T+pt)^{-(r+x)}\Gamma(r+x) ∫0∞Γ(r)αrλr+x−1e−λ(α+T+pt)dλ=Γ(r)αr∫0∞ λr+x−1e−λ(α+T+pt)dλ=Γ(r)αr(α+T+pt)−(r+x)Γ(r+x)
从而 B = Γ ( r + x ) α r Γ ( r ) B ( a , b ) ∫ 0 1 p a − 2 ( 1 − p ) b + x − 1 ( α + T + p t ) − ( r + x ) d p B=\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)B(a,b)}\int_0^1p^{a-2}(1-p)^{b+x-1}(\alpha+T+pt)^{-(r+x)}dp B=Γ(r)B(a,b)Γ(r+x)αr∫01pa−2(1−p)b+x−1(α+T+pt)−(r+x)dp
和上面一样,使用 q = 1 − p q=1-p q=1−p进行还元,得
Γ ( r + x ) α r Γ ( r ) B ( a , b ) ∫ 0 1 q b + x − 1 ( 1 − q ) a − 2 ( α + T + t − q t ) − ( r + x ) d q \frac{\Gamma(r+x)\alpha^r}{\Gamma(r)B(a,b)}\int_0^1q^{b+x-1}(1-q)^{a-2}(\alpha+T+t-qt)^{-(r+x)}dq Γ(r)B(a,b)Γ(r+x)αr∫01qb+x−1(1−q)a−2(α+T+t−qt)−(r+x)dq
= Γ ( r + x ) α r Γ ( r ) B ( a , b ) ( α + T + t ) r + x ∫ 0 1 q b + x − 1 ( 1 − q ) a − 2 ( 1 − t α + T + t q ) − ( r + x ) d q =\frac{\Gamma(r+x)\alpha^r}{\Gamma(r)B(a,b)(\alpha+T+t)^{r+x}}\int_0^1q^{b+x-1}(1-q)^{a-2}\big(1-\frac t{\alpha+T+t}q\big)^{-(r+x)}dq =Γ(r)B(a,b)(α+T+t)r+xΓ(r+x)αr∫01qb+x−1(1−q)a−2(1−α+T+ttq)−(r+x)dq
积分部分可以写作超几何函数的积分形式,故而
B = B ( a − 1 , b + x ) B ( a , b ) Γ ( r + x ) α r Γ ( r ) ( α + T + t ) r + x 2 F 1 ( r + x , b + x ; a + b + x − 1 ; t α + T + t ) B=\frac{B(a-1,b+x)}{B(a,b)}\frac{\Gamma(r+x)\alpha^{r}}{\Gamma(r)(\alpha+T+t)^{r+x}}_2F_1\big(r+x,b+x;a+b+x-1;\frac{t}{\alpha+T+t}\big) B=B(a,b)B(a−1,b+x)Γ(r)(α+T+t)r+xΓ(r+x)αr2F1(r+x,b+x;a+b+x−1;α+T+tt)
综上,我们可以求得:
E ( Y ( t ) ∣ X = x , t x , T , r , α , a , b ) = a + b + x − 1 a − 1 [ 1 − ( α + T α + T + t ) r + x 2 F 1 ( r + x , b + x ; a + b + x − 1 ; t α + T + t ) ] 1 + δ x > 0 a b + x − 1 ( α + T α + t x ) r + x \begin{aligned}&E(Y(t)\mid X=x,t_x,T,r,\alpha,a,b)=\\&\frac{\frac{a+b+x-1}{a-1}\left[1-\left(\frac{\alpha+T}{\alpha+T+t}\right)^{r+x} 2F_1\big(r+x,b+x;a+b+x-1;\frac{t}{\alpha+T+t}\big)\right]}{1+\delta_{x>0}\frac{a}{b+x-1}\left(\frac{\alpha+T}{\alpha+t_x}\right)^{r+x}}\end{aligned} E(Y(t)∣X=x,tx,T,r,α,a,b)=1+δx>0b+x−1a(α+txα+T)r+xa−1a+b+x−1[1−(α+T+tα+T)r+x2F1(r+x,b+x;a+b+x−1;α+T+tt)]
3、预测 P ( Y ( t ) = y ∣ X = x , y x , T ) P(Y(t)=y|X=x,y_x,T) P(Y(t)=y∣X=x,yx,T)
也就是根据一个客户的历史购买情况预测出这个客户在(T,T+t]时间段内的购买可能。
首先我们之前已经推导过了当用户在T时刻依然活跃的情形:
P ( X ( t ) = x ∣ λ , p ) = ( 1 − p ) x e − λ t ( λ t ) x x ! + δ x > 0 p ( 1 − p ) x − 1 [ 1 − e − λ t Σ j = 0 x − 1 ( λ t ) j j ! ] P(X(t)=x|\lambda,p)=(1-p)^x\frac{e^{-\lambda t}(\lambda t)^x}{x!} +\delta_{x>0} p(1-p)^{x-1}[1-e^{-\lambda t}\Sigma_{j=0}^{x-1}\frac{(\lambda t)^j}{j!}] P(X(t)=x∣λ,p)=(1−p)xx!e−λt(λt)x+δx>0p(1−p)x−1[1−e−λtΣj=0x−1j!(λt)j]
而对于用户在T时刻不再活跃的情情形,我们有
P ( Y ( t ) = y ∣ λ , p ) = { 1 如果 y = 0 0 其他情况 P(Y(t)=y | \lambda,p)=\begin{cases}1&\text{如果}y=0\\0&\text{其他情况}\end{cases} P(Y(t)=y∣λ,p)={10如果y=0其他情况
我们分别将 P ( 在 T 时刻依然活跃 ∣ X = x , t x , T , λ , p ) = ( 1 − p ) x λ x e − λ T L ( λ , p ∣ X = x , t x , T ) P(在T时刻依然活跃|X=x,t_x,T,\lambda,p)=\frac{(1-p)^{x}\lambda^xe^{-\lambda T}}{L(\lambda,p | X=x,t_x,T)} P(在T时刻依然活跃∣X=x,tx,T,λ,p)=L(λ,p∣X=x,tx,T)(1−p)xλxe−λT
与
P ( 在 t x 时刻活跃,但是到了第 x 次交易之后立刻失活 ) = p ( 1 − p ) x − 1 λ x e − λ t x L ( λ , p ∣ X = x , t x , T ) P(在t_x时刻活跃,但是到了第x次交易之后立刻失活)=\frac{p(1-p)^{x-1}\lambda^xe^{-\lambda t_x}}{L(\lambda,p | X=x,t_x,T)} P(在tx时刻活跃,但是到了第x次交易之后立刻失活)=L(λ,p∣X=x,tx,T)p(1−p)x−1λxe−λtx
作为系数,乘以这2个情形下的式子,获得统一的表达式:
P ( Y ( t ) = y ∣ X = x , t x , T , λ , p ) = { δ x > 0 , y = 0 p ( 1 − p ) x − 1 λ x e − λ t x + ( 1 − p ) x + y λ x + y t y e − λ ( T + t ) y ! + δ y > 0 p ( 1 − p ) x + y − 1 [ λ x e − λ T − e − λ ( T + t ) ∑ j = 0 y − 1 λ x + j t j j ! ] } / L ( λ , p ∣ X = x , t x , T ) P(Y(t)=y | X=x,t_x,T,\lambda,p)=\left\{\delta_{x>0,y=0} p(1-p)^{x-1}\lambda^xe^{-\lambda t_x}+(1-p)^{x+y}\frac{\lambda^{x+y}t^ye^{-\lambda(T+t)}}{y!}+\delta_{y>0}p(1-p)^{x+y-1}\left[\lambda^xe^{-\lambda T}-e^{-\lambda(T+t)}\sum_{j=0}^{y-1}\frac{\lambda^{x+j}t^j}{j!}\right]\right\}\Big/L(\lambda,p | X=x,t_x,T) P(Y(t)=y∣X=x,tx,T,λ,p)={δx>0,y=0p(1−p)x−1λxe−λtx+(1−p)x+yy!λx+ytye−λ(T+t)+δy>0p(1−p)x+y−1[λxe−λT−e−λ(T+t)∑j=0y−1j!λx+jtj]}/L(λ,p∣X=x,tx,T)
和上面一样,我们需将 λ \lambda λ和p转换为我们求出的那4个参数:
P ( Y ( t ) = y ∣ X = x , t x , T , r , α , a , b ) = ∫ 0 1 ∫ 0 ∞ { P ( Y ( t ) = y ∣ X = x , t x , T , λ , p ) f ( λ , p ∣ r , α , a , b , X = x , t x , T ) } d λ d p \begin{aligned}P(Y(t)=y | X&=x,t_x,T,r,\alpha,a,b)\\&=\int_0^1\int_0^\infty\Big\{P(Y(t)=y | X=x,t_x,T,\lambda,p) f(\lambda,p | r,\alpha,a,b,X=x,t_x,T)\Big\} d\lambda dp\end{aligned} P(Y(t)=y∣X=x,tx,T,r,α,a,b)=∫01∫0∞{P(Y(t)=y∣X=x,tx,T,λ,p)f(λ,p∣r,α,a,b,X=x,tx,T)}dλdp
这个$ f(\lambda,p | r,\alpha,a,b,X=x,t_x,T)$我们上文已经求过了,现在能够得到:
P ( Y ( t ) = y ∣ X = x , t x , T , r , α , a , b ) = δ x > 0 , y = 0 A + B + δ y > 0 C L ( r , α , a , b ∣ X = x , t x , T ) P(Y(t)=y | X=x,t_x,T,r,\alpha,a,b)=\frac{\delta_{x>0,y=0}\text{A}+\text{B}+\delta_{y>0}\text{C}}{L(r,\alpha,a,b | X=x,t_x,T)} P(Y(t)=y∣X=x,tx,T,r,α,a,b)=L(r,α,a,b∣X=x,tx,T)δx>0,y=0A+B+δy>0C
其中, A = B ( a + 1 , b + x − 1 ) B ( a , b ) Γ ( r + x ) Γ ( r ) α r ( α + t x ) r + x A=\frac{B(a+1,b+x-1)}{B(a,b)}\frac{\Gamma(r+x)}{\Gamma(r)}\frac{\alpha^r}{(\alpha+t_x)^{r+x}} A=B(a,b)B(a+1,b+x−1)Γ(r)Γ(r+x)(α+tx)r+xαr
,
B = B ( a , b + x + y ) B ( a , b ) Γ ( r + x + y ) Γ ( r ) y ! α r t y ( α + T + t ) r + x + y B=\frac{B(a,b+x+y)}{B(a,b)}\frac{\Gamma(r+x+y)}{\Gamma(r)y!}\frac{\alpha^rt^y}{(\alpha+T+t)^{r+x+y}} B=B(a,b)B(a,b+x+y)Γ(r)y!Γ(r+x+y)(α+T+t)r+x+yαrty
C = B ( a + 1 , b + x + y − 1 ) B ( a , b ) { Γ ( r + x ) Γ ( r ) α r ( α + T ) r + x − ∑ j = 0 y − 1 Γ ( r + x + j ) Γ ( r ) j ! α r t j ( α + T + t ) r + x + j } C=\frac{B(a+1,b+x+y-1)}{B(a,b)}\left\{\begin{aligned}\frac{\Gamma(r+x)}{\Gamma(r)}\frac{\alpha^r}{(\alpha+T)^{r+x}}-\sum_{j=0}^{y-1}\frac{\Gamma(r+x+j)}{\Gamma(r)j!}\frac{\alpha^rt^j}{(\alpha+T+t)^{r+x+j}}\end{aligned}\right\} C=B(a,b)B(a+1,b+x+y−1)⎩ ⎨ ⎧Γ(r)Γ(r+x)(α+T)r+xαr−j=0∑y−1Γ(r)j!Γ(r+x+j)(α+T+t)r+x+jαrtj⎭ ⎬ ⎫
lifetimes中的函数
在lifetimes包中,使用conditional_expected_number_of_purchases_up_to_time函数来预测t期之后的交易数,也就是我们求的 E ( Y ( t ) ∣ X = x , t x , T ) E(Y(t)|X=x,t_x,T) E(Y(t)∣X=x,tx,T)
def conditional_expected_number_of_purchases_up_to_time(self, t, frequency, recency, T
):"""Conditional expected number of purchases up to time.Calculate the expected number of repeat purchases up to time t for arandomly chosen individual from the population, given they havepurchase history (frequency, recency, T).This function uses equation (10) from [2]_.Parameters----------t: array_liketimes to calculate the expectation for.frequency: array_likehistorical frequency of customer.recency: array_likehistorical recency of customer.T: array_likeage of the customer.Returns-------array_likeReferences----------.. [2] Fader, Peter S., Bruce G.S. Hardie, and Ka Lok Lee (2005a),"Counting Your Customers the Easy Way: An Alternative to thePareto/NBD Model," Marketing Science, 24 (2), 275-84."""x = frequencyr, alpha, a, b = self._unload_params("r", "alpha", "a", "b")_a = r + x_b = b + x_c = a + b + x - 1_z = t / (alpha + T + t)ln_hyp_term = np.log(hyp2f1(_a, _b, _c, _z))# if the value is inf, we are using a different but equivalent# formula to compute the function evaluation.ln_hyp_term_alt = np.log(hyp2f1(_c - _a, _c - _b, _c, _z)) + (_c - _a - _b) * np.log(1 - _z)ln_hyp_term = np.where(np.isinf(ln_hyp_term), ln_hyp_term_alt, ln_hyp_term)first_term = (a + b + x - 1) / (a - 1)second_term = 1 - np.exp(ln_hyp_term + (r + x) * np.log((alpha + T) / (alpha + t + T)))numerator = first_term * second_termdenominator = 1 + (x > 0) * (a / (b + x - 1)) * ((alpha + T) / (alpha + recency)) ** (r + x)return numerator / denominator
它的式子基本上和我们求的结果一样,唯一的不同点在于分子部分带有超越函数的那部分会先进行对数化处理,如果对数化的结果为inf,则使用不同但等效的公式(ln_hyp_term_alt)来计算函数的求值。
接下来是计算在T时刻依然活跃的函数。
def conditional_probability_alive(self, frequency, recency, T
):"""Compute conditional probability alive.Compute the probability that a customer with history(frequency, recency, T) is currently alive.From http://www.brucehardie.com/notes/021/palive_for_BGNBD.pdfParameters----------frequency: array or scalarhistorical frequency of customer.recency: array or scalarhistorical recency of customer.T: array or scalarage of the customer.Returns-------arrayvalue representing a probability"""r, alpha, a, b = self._unload_params("r", "alpha", "a", "b")log_div = (r + frequency) * np.log((alpha + T) / (alpha + recency)) + np.log(a / (b + np.maximum(frequency, 1) - 1))return np.atleast_1d(np.where(frequency == 0, 1.0, expit(-log_div)))def conditional_probability_alive_matrix(self, max_frequency=None, max_recency=None
):"""Compute the probability alive matrix.Uses the ``conditional_probability_alive()`` method to get calculate the matrix.Parameters----------max_frequency: float, optionalthe maximum frequency to plot. Default is max observed frequency.max_recency: float, optionalthe maximum recency to plot. This also determines the age of thecustomer. Default to max observed age.Returns-------matrix:A matrix of the form [t_x: historical recency, x: historical frequency]"""max_frequency = max_frequency or int(self.data["frequency"].max())max_recency = max_recency or int(self.data["T"].max())return np.fromfunction(self.conditional_probability_alive, (max_frequency + 1, max_recency + 1), T=max_recency).T
公式和我们推出来的一样,只是计算的是式子的对数形式,最后再指数展开。
除此以外,还会有计算t期内交易数期望值的函数,也就是我们计算的 E ( X ( t ) ∣ r , α , a , b ) E(X(t)|r,\alpha,a,b) E(X(t)∣r,α,a,b)
def expected_number_of_purchases_up_to_time(self, t
):"""Calculate the expected number of repeat purchases up to time t.Calculate repeat purchases for a randomly chosen individual from thepopulation.Equivalent to equation (9) of [2]_.Parameters----------t: array_liketimes to calculate the expection forReturns-------array_likeReferences----------.. [2] Fader, Peter S., Bruce G.S. Hardie, and Ka Lok Lee (2005a),"Counting Your Customers the Easy Way: An Alternative to thePareto/NBD Model," Marketing Science, 24 (2), 275-84."""r, alpha, a, b = self._unload_params("r", "alpha", "a", "b")hyp = hyp2f1(r, b, a + b - 1, t / (alpha + t))return (a + b - 1) / (a - 1) * (1 - hyp * (alpha / (alpha + t)) ** r)
公式和我们推导出来的结果一样。
最后,还有一个可以预测未来t期,交易数为n概率的函数,也就是我们的 P ( Y ( t ) = y ∣ X = x , y x , T ) P(Y(t)=y|X=x,y_x,T) P(Y(t)=y∣X=x,yx,T)
def probability_of_n_purchases_up_to_time(self, t, n
):r"""Compute the probability of n purchases... math:: P( N(t) = n | \text{model} )where N(t) is the number of repeat purchases a customer makes in tunits of time.Comes from equation (8) of [2]_.Parameters----------t: floatnumber units of timen: intnumber of purchasesReturns-------float:Probability to have n purchases up to t units of timeReferences----------.. [2] Fader, Peter S., Bruce G.S. Hardie, and Ka Lok Lee (2005a),"Counting Your Customers the Easy Way: An Alternative to thePareto/NBD Model," Marketing Science, 24 (2), 275-84."""r, alpha, a, b = self._unload_params("r", "alpha", "a", "b")first_term = (beta(a, b + n)/ beta(a, b)* gamma(r + n)/ gamma(r)/ gamma(n + 1)* (alpha / (alpha + t)) ** r* (t / (alpha + t)) ** n)if n > 0:j = np.arange(0, n)finite_sum = (gamma(r + j) / gamma(r) / gamma(j + 1) * (t / (alpha + t)) ** j).sum()second_term = beta(a + 1, b + n - 1) / beta(a, b) * (1 - (alpha / (alpha + t)) ** r * finite_sum)else:second_term = 0return first_term + second_term形式上的和我们推出来的公式不大一样,但是结果应该是一样的,注意此处的参数n应该代表的是我们推导中的x+y
总结
本文跟随了https://www.brucehardie.com/notes/039/bgnbd_derivation__2019-11-06.pdf 中的过程一步步推导了BG/NBD的数学公式,并介绍了使用Excel与lifetimes包中的求解以及预测方法。笔者本人也跟随着扩展了贝塔/伽马/泊松/指数分布的知识。之后有机会会做一个使用BG/NBD的CLV分析案例。
这篇关于模型推导:BG/NBD(预测用户生命周期(CLV)模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







